 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiftRefine: Progressively Refined View Synthesis from 3D Lifting with Volume-Triplane Representations
Dec 19, 2024

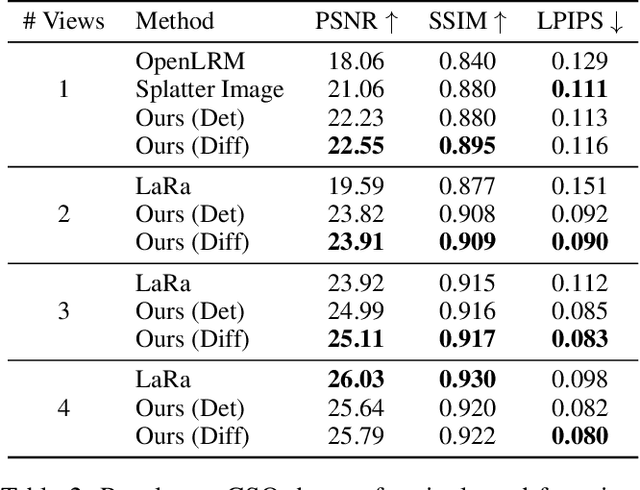

We propose a new view synthesis method via synthesizing a 3D neural field from both single or few-view input images. To address the ill-posed nature of the image-to-3D generation problem, we devise a two-stage method that involves a reconstruction model and a diffusion model for view synthesis. Our reconstruction model first lifts one or more input images to the 3D space from a volume as the coarse-scale 3D representation followed by a tri-plane as the fine-scale 3D representation. To mitigate the ambiguity in occluded regions, our diffusion model then hallucinates missing details in the rendered images from tri-planes. We then introduce a new progressive refinement technique that iteratively applies the reconstruction and diffusion model to gradually synthesize novel views, boosting the overall quality of the 3D representations and their rendering. Empirical evaluation demonstrates the superiority of our method over state-of-the-art methods on the synthetic SRN-Car dataset, the in-the-wild CO3D dataset, and large-scale Objaverse dataset while achieving both sampling efficacy and multi-view consistency.
SwiftBrush v2: Make Your One-step Diffusion Model Better Than Its Teacher
Aug 27, 2024



In this paper, we aim to enhance the performance of SwiftBrush, a prominent one-step text-to-image diffusion model, to be competitive with its multi-step Stable Diffusion counterpart. Initially, we explore the quality-diversity trade-off between SwiftBrush and SD Turbo: the former excels in image diversity, while the latter excels in image quality. This observation motivates our proposed modifications in the training methodology, including better weight initialization and efficient LoRA training. Moreover, our introduction of a novel clamped CLIP loss enhances image-text alignment and results in improved image quality. Remarkably, by combining the weights of models trained with efficient LoRA and full training, we achieve a new state-of-the-art one-step diffusion model, achieving an FID of 8.14 and surpassing all GAN-based and multi-step Stable Diffusion models. The project page is available at https://swiftbrushv2.github.io.
SwiftBrush: One-Step Text-to-Image Diffusion Model with Variational Score Distillation
Dec 08, 2023Despite their ability to generate high-resolution and diverse images from text prompts, text-to-image diffusion models often suffer from slow iterative sampling processes. Model distillation is one of the most effective directions to accelerate these models. However, previous distillation methods fail to retain the generation quality while requiring a significant amount of images for training, either from real data or synthetically generated by the teacher model. In response to this limitation, we present a novel image-free distillation scheme named $\textbf{SwiftBrush}$. Drawing inspiration from text-to-3D synthesis, in which a 3D neural radiance field that aligns with the input prompt can be obtained from a 2D text-to-image diffusion prior via a specialized loss without the use of any 3D data ground-truth, our approach re-purposes that same loss for distilling a pretrained multi-step text-to-image model to a student network that can generate high-fidelity images with just a single inference step. In spite of its simplicity, our model stands as one of the first one-step text-to-image generators that can produce images of comparable quality to Stable Diffusion without reliance on any training image data. Remarkably, SwiftBrush achieves an FID score of $\textbf{16.67}$ and a CLIP score of $\textbf{0.29}$ on the COCO-30K benchmark, achieving competitive results or even substantially surpassing existing state-of-the-art distillation techniques.
Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
Mar 29, 2023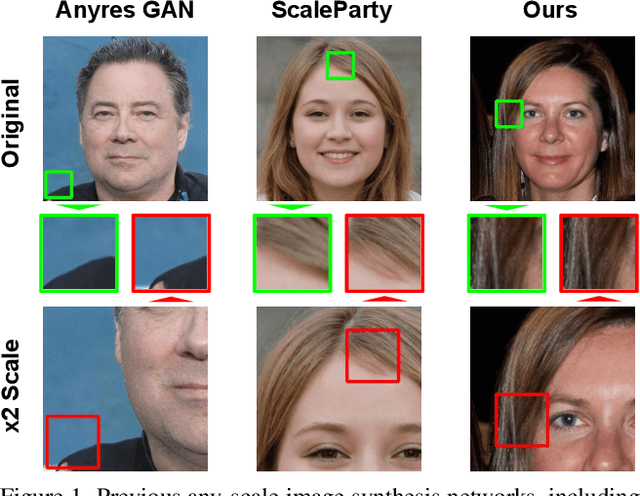



Any-scale image synthesis offers an efficient and scalable solution to synthesize photo-realistic images at any scale, even going beyond 2K resolution. However, existing GAN-based solutions depend excessively on convolutions and a hierarchical architecture, which introduce inconsistency and the $``$texture sticking$"$ issue when scaling the output resolution. From another perspective, INR-based generators are scale-equivariant by design, but their huge memory footprint and slow inference hinder these networks from being adopted in large-scale or real-time systems. In this work, we propose $\textbf{C}$olumn-$\textbf{R}$ow $\textbf{E}$ntangled $\textbf{P}$ixel $\textbf{S}$ynthesis ($\textbf{CREPS}$), a new generative model that is both efficient and scale-equivariant without using any spatial convolutions or coarse-to-fine design. To save memory footprint and make the system scalable, we employ a novel bi-line representation that decomposes layer-wise feature maps into separate $``$thick$"$ column and row encodings. Experiments on various datasets, including FFHQ, LSUN-Church, MetFaces, and Flickr-Scenery, confirm CREPS' ability to synthesize scale-consistent and alias-free images at any arbitrary resolution with proper training and inference speed. Code is available at https://github.com/VinAIResearch/CREPS.
Anti-DreamBooth: Protecting users from personalized text-to-image synthesis
Mar 27, 2023Text-to-image diffusion models are nothing but a revolution, allowing anyone, even without design skills, to create realistic images from simple text inputs. With powerful personalization tools like DreamBooth, they can generate images of a specific person just by learning from his/her few reference images. However, when misused, such a powerful and convenient tool can produce fake news or disturbing content targeting any individual victim, posing a severe negative social impact. In this paper, we explore a defense system called Anti-DreamBooth against such malicious use of DreamBooth. The system aims to add subtle noise perturbation to each user's image before publishing in order to disrupt the generation quality of any DreamBooth model trained on these perturbed images. We investigate a wide range of algorithms for perturbation optimization and extensively evaluate them on two facial datasets over various text-to-image model versions. Despite the complicated formulation of DreamBooth and Diffusion-based text-to-image models, our methods effectively defend users from the malicious use of those models. Their effectiveness withstands even adverse conditions, such as model or prompt/term mismatching between training and testing. Our code will be available at \href{https://github.com/VinAIResearch/Anti-DreamBooth.git}{https://github.com/VinAIResearch/Anti-DreamBooth.git}.