 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftBrush v2: Make Your One-step Diffusion Model Better Than Its Teacher
Aug 27, 2024



In this paper, we aim to enhance the performance of SwiftBrush, a prominent one-step text-to-image diffusion model, to be competitive with its multi-step Stable Diffusion counterpart. Initially, we explore the quality-diversity trade-off between SwiftBrush and SD Turbo: the former excels in image diversity, while the latter excels in image quality. This observation motivates our proposed modifications in the training methodology, including better weight initialization and efficient LoRA training. Moreover, our introduction of a novel clamped CLIP loss enhances image-text alignment and results in improved image quality. Remarkably, by combining the weights of models trained with efficient LoRA and full training, we achieve a new state-of-the-art one-step diffusion model, achieving an FID of 8.14 and surpassing all GAN-based and multi-step Stable Diffusion models. The project page is available at https://swiftbrushv2.github.io.
PlanarTrack: A Large-scale Challenging Benchmark for Planar Object Tracking
Mar 14, 2023



Planar object tracking is a critical computer vision problem and has drawn increasing interest owing to its key roles in robotics, augmented reality, etc. Despite rapid progress, its further development, especially in the deep learning era, is largely hindered due to the lack of large-scale challenging benchmarks. Addressing this, we introduce PlanarTrack, a large-scale challenging planar tracking benchmark. Specifically, PlanarTrack consists of 1,000 videos with more than 490K images. All these videos are collected in complex unconstrained scenarios from the wild, which makes PlanarTrack, compared with existing benchmarks, more challenging but realistic for real-world applications. To ensure the high-quality annotation, each frame in PlanarTrack is manually labeled using four corners with multiple-round careful inspection and refinement. To our best knowledge, PlanarTrack, to date, is the largest and most challenging dataset dedicated to planar object tracking. In order to analyze the proposed PlanarTrack, we evaluate 10 planar trackers and conduct comprehensive comparisons and in-depth analysis. Our results, not surprisingly, demonstrate that current top-performing planar trackers degenerate significantly on the challenging PlanarTrack and more efforts are needed to improve planar tracking in the future. In addition, we further derive a variant named PlanarTrack$_{\mathbf{BB}}$ for generic object tracking from PlanarTrack. Our evaluation of 10 excellent generic trackers on PlanarTrack$_{\mathrm{BB}}$ manifests that, surprisingly, PlanarTrack$_{\mathrm{BB}}$ is even more challenging than several popular generic tracking benchmarks and more attention should be paid to handle such planar objects, though they are rigid. All benchmarks and evaluations will be released at the project webpage.
Ensemble Learning of Myocardial Displacements for Myocardial Infarction Detection in Echocardiography
Mar 12, 2023



Early detection and localization of myocardial infarction (MI) can reduce the severity of cardiac damage through timely treatment interventions. In recent years, deep learning techniques have shown promise for detecting MI in echocardiographic images. However, there has been no examination of how segmentation accuracy affects MI classification performance and the potential benefits of using ensemble learning approaches. Our study investigates this relationship and introduces a robust method that combines features from multiple segmentation models to improve MI classification performance by leveraging ensemble learning. Our method combines myocardial segment displacement features from multiple segmentation models, which are then input into a typical classifier to estimate the risk of MI. We validated the proposed approach on two datasets: the public HMC-QU dataset (109 echocardiograms) for training and validation, and an E-Hospital dataset (60 echocardiograms) from a local clinical site in Vietnam for independent testing. Model performance was evaluated based on accuracy, sensitivity, and specificity. The proposed approach demonstrated excellent performance in detecting MI. The results showed that the proposed approach outperformed the state-of-the-art feature-based method. Further research is necessary to determine its potential use in clinical settings as a tool to assist cardiologists and technicians with objective assessments and reduce dependence on operator subjectivity. Our research codes are available on GitHub at https://github.com/vinuni-vishc/mi-detection-echo.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Measurement of 2x2 LoS MIMO Terahertz Channel
Oct 14, 2022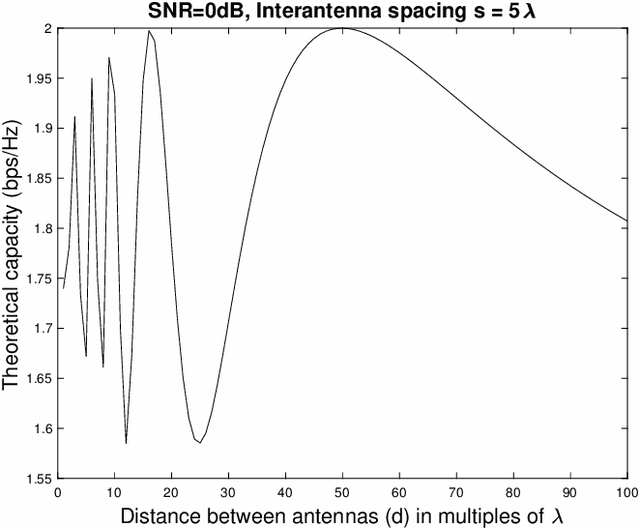
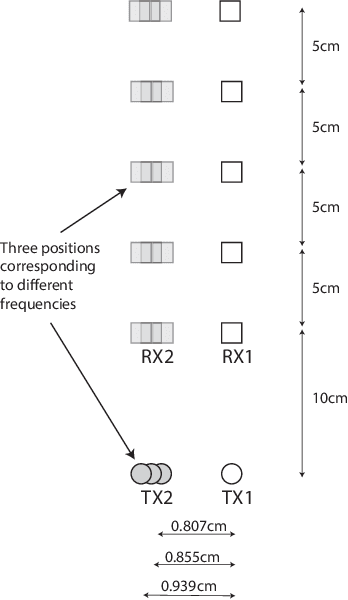

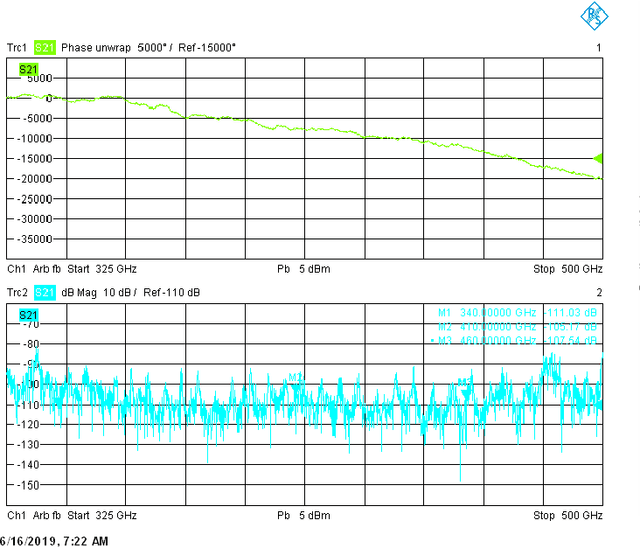
This paper examines the performance of a 2x2 Line of Sight (LoS) Multiple Input Multiple Output (MIMO) channel at three terahertz frequencies-340 GHz, 410 Ghz, and 460 GHz. While theoretical models predict very high channel capacities, we observe lower capacity which is explained by asymmetric transmit-to-receive signal strengths as well as due to signal attenuation over longer distances. Overall, however, we note that at 460 Ghz, channel capacity of higher than 12 bps/hz is possible even at sub-optimal inter-antenna spacings (for different distances). An important observation is also that we need to maintain appropriate receive signal levels at receive antennas in order to improve capacity.
Effect of Standing Wave on Terahertz Channel Model
Oct 13, 2022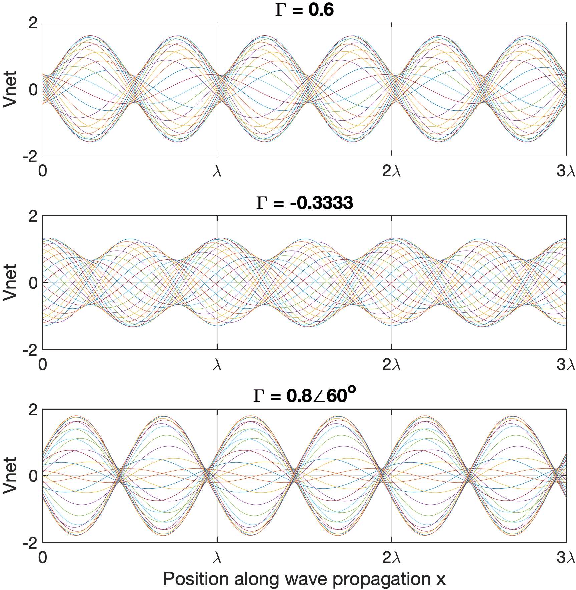
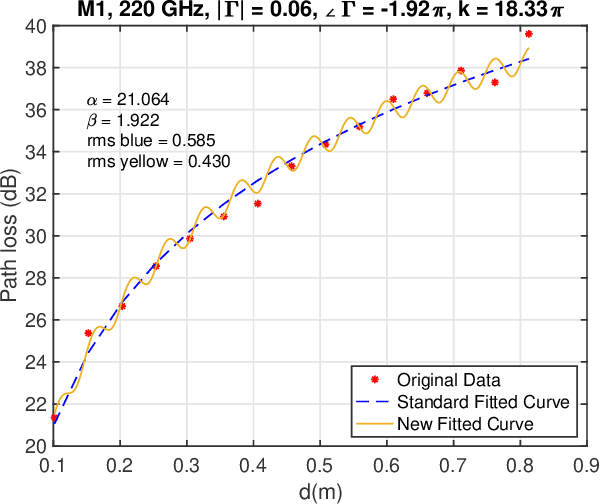
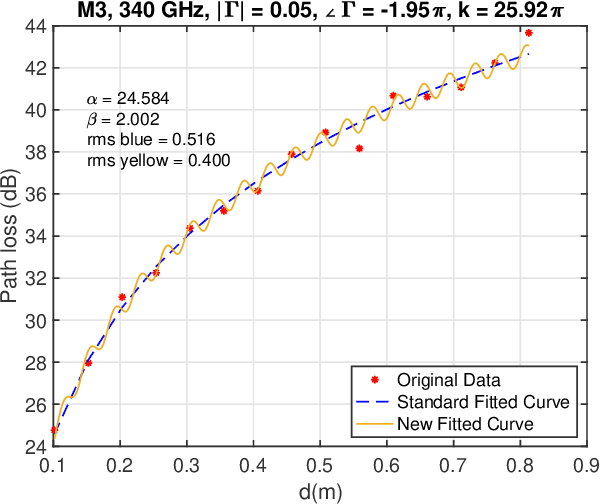
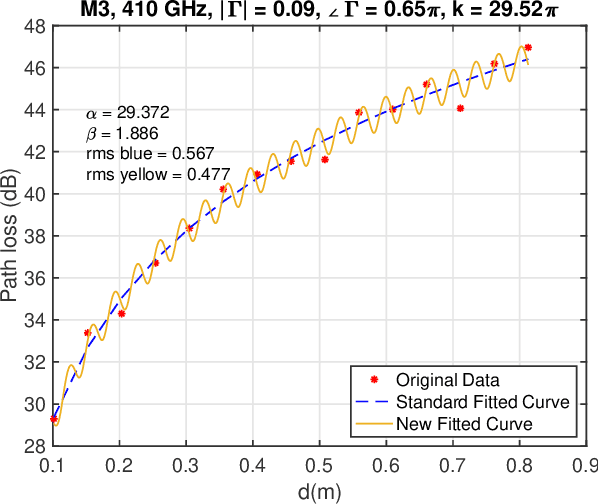
There is a growing interest in exploiting the terahertz frequency band for future communication systems that demand high data rates. Given the complex propagation behavior of this frequency band, various researchers have developed channel models that can be utilized in the development of communication systems. These models however do not include a crucial aspect of terahertz propagation at short distances: the presence of standing waves. Our measurements show that at specific distances, the effect of standing waves is significant. In this paper, we extend previous terahertz channel models to include the effect of standing waves and show a good fit with our measurements. Our measurements and modeling cover the five most promising terahertz frequency bands: 140, 220, 340, 410, 460 GHz.
Reflection Channel Model for Terahertz Communications
Oct 13, 2022
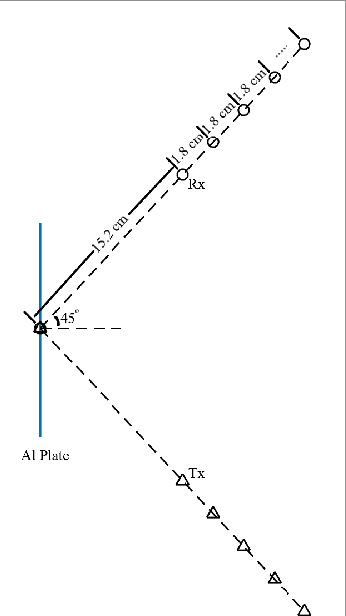
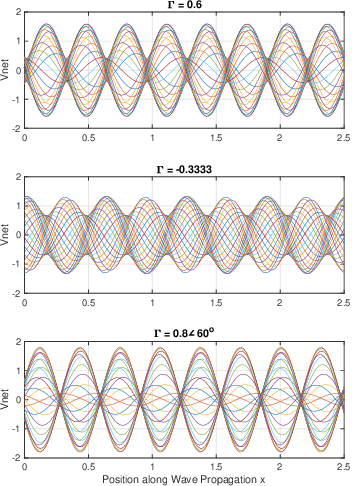
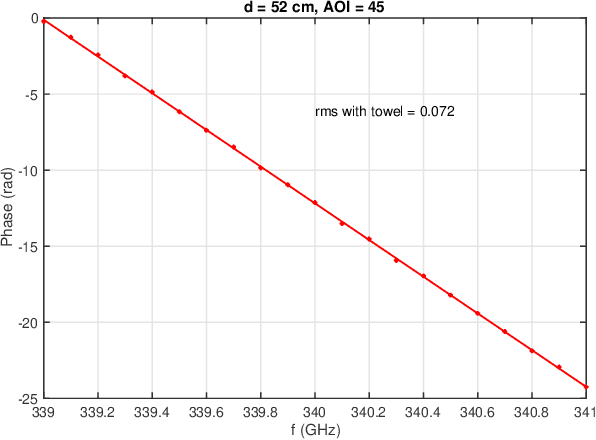
Terahertz frequencies are an untapped resource for providing high-speed short-range communications. As a result, it is of interest to study the propagation characteristics of terahertz waves and to develop channel models. In previous work we used a measurement-based approach to develop an accurate channel model for line of sight (LoS) links. In this paper we extend that work by developing channel models for non-line of sight (NLoS) links where the signal suffers one reflection. We study reflections that occur off a metal plate as well as a piece of wood. Our model for received magnitude includes the effects of standing waves that develop between the transmitter and receiver. Measurements show an excellent agreement between empirical data and the model. In addition, we have analyzed the received phase of the reflected signal at frequencies in the range 320- 480 GHz. We observed a linear error between the predicted and actual phase and developed a model to accommodate that discrepancy. The final model we have developed for predicting received phase is very accurate for the entire range 320 - 480 GHz and for both materials.
The Dynamical Gaussian Process Latent Variable Model in the Longitudinal Scenario
Sep 25, 2019

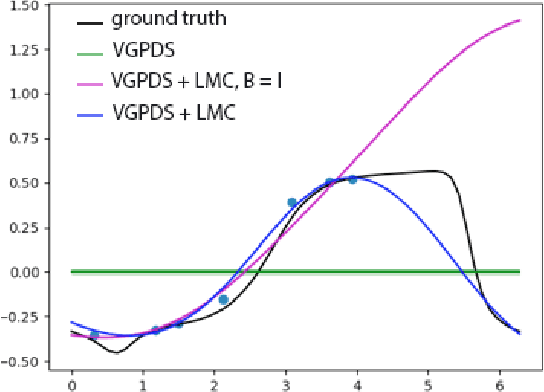
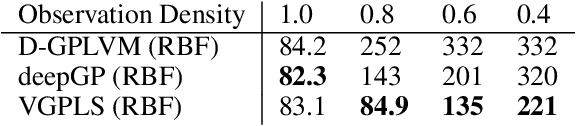
The Dynamical Gaussian Process Latent Variable Models provide an elegant non-parametric framework for learning the low dimensional representations of the high-dimensional time-series. Real world observational studies, however, are often ill-conditioned: the observations can be noisy, not assuming the luxury of relatively complete and equally spaced like those in time series. Such conditions make it difficult to learn reasonable representations in the high dimensional longitudinal data set by way of Gaussian Process Latent Variable Model as well as other dimensionality reduction procedures. In this study, we approach the inference of Gaussian Process Dynamical Systems in Longitudinal scenario by augmenting the bound in the variational approximation to include systematic samples of the unseen observations. We demonstrate the usefulness of this approach on synthetic as well as the human motion capture data set.