 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Learning of Myocardial Displacements for Myocardial Infarction Detection in Echocardiography
Mar 12, 2023



Early detection and localization of myocardial infarction (MI) can reduce the severity of cardiac damage through timely treatment interventions. In recent years, deep learning techniques have shown promise for detecting MI in echocardiographic images. However, there has been no examination of how segmentation accuracy affects MI classification performance and the potential benefits of using ensemble learning approaches. Our study investigates this relationship and introduces a robust method that combines features from multiple segmentation models to improve MI classification performance by leveraging ensemble learning. Our method combines myocardial segment displacement features from multiple segmentation models, which are then input into a typical classifier to estimate the risk of MI. We validated the proposed approach on two datasets: the public HMC-QU dataset (109 echocardiograms) for training and validation, and an E-Hospital dataset (60 echocardiograms) from a local clinical site in Vietnam for independent testing. Model performance was evaluated based on accuracy, sensitivity, and specificity. The proposed approach demonstrated excellent performance in detecting MI. The results showed that the proposed approach outperformed the state-of-the-art feature-based method. Further research is necessary to determine its potential use in clinical settings as a tool to assist cardiologists and technicians with objective assessments and reduce dependence on operator subjectivity. Our research codes are available on GitHub at https://github.com/vinuni-vishc/mi-detection-echo.
Fast Video-based Face Recognition in Collaborative Learning Environments
Oct 26, 2021
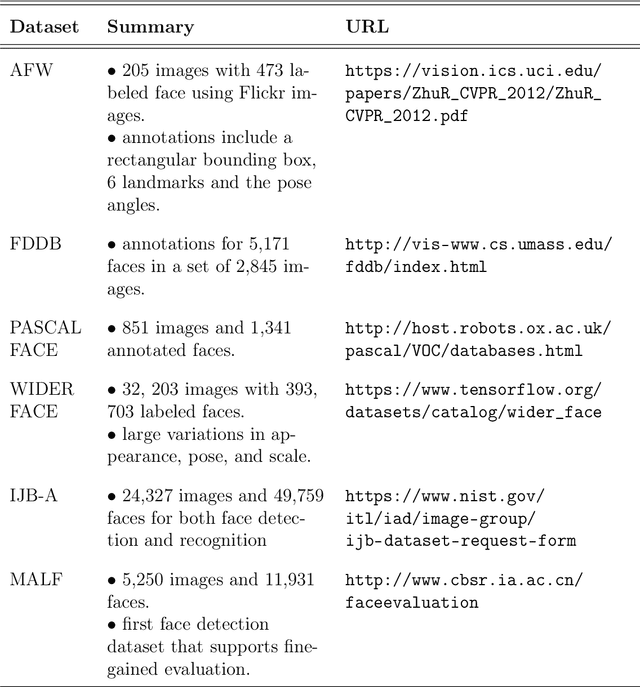


Face recognition is a classical problem in Computer Vision that has experienced significant progress. Yet, in digital videos, face recognition is complicated by occlusion, pose and lighting variations, and persons entering/leaving the scene. The thesis's goal is to develop a fast method for face recognition in digital videos that is applicable to large datasets. The thesis introduces several methods to address the problems associated with video face recognition. First, to address issues associated with pose and lighting variations, a collection of face prototypes is associated with each student. Second, to speed up the process, sampling, K-means Clustering, and a combination of both are used to reduce the number of face prototypes per student. Third, the videos are processed at different frame rates. Fourth, the thesis proposes the use of active sets to address occlusion and to eliminate face recognition application on video frames with slow face motions. Fifth, the thesis develops a group face detector that recognizes students within a collaborative learning group, while rejecting out-of-group face detections. Sixth, the thesis introduces a face DeID for protecting the students' identities. Seventh, the thesis uses data augmentation to increase the training set's size. The different methods are combined using multi-objective optimization to guarantee that the full method remains fast without sacrificing accuracy. To test the approach, the thesis develops the AOLME dataset of 138 student faces (81 boys and 57 girls) of ages 10 to 14, who are predominantly Latina/o students. Compared to the baseline method, the final optimized method resulted in fast recognition times with significant improvements in face recognition accuracy. Using face prototype sampling only, the proposed method achieved an accuracy of 71.8% compared to 62.3% for the baseline system, while running 11.6 times faster.
Facial Recognition in Collaborative Learning Videos
Oct 25, 2021
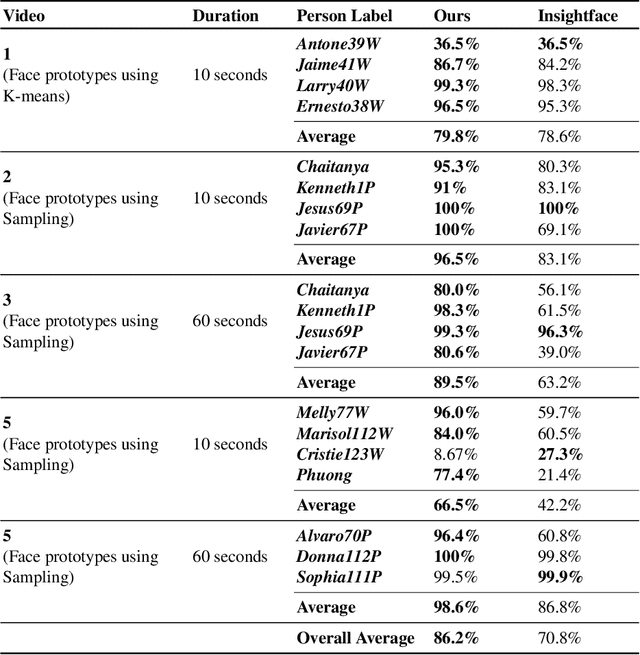
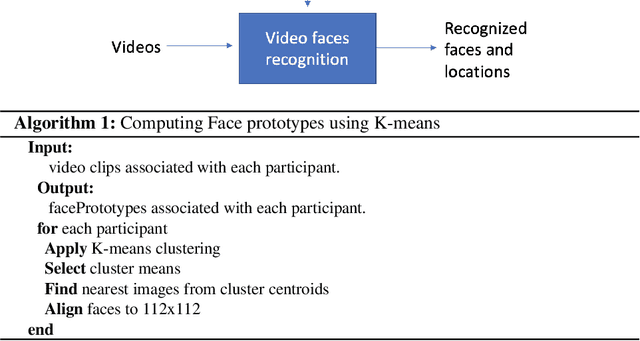
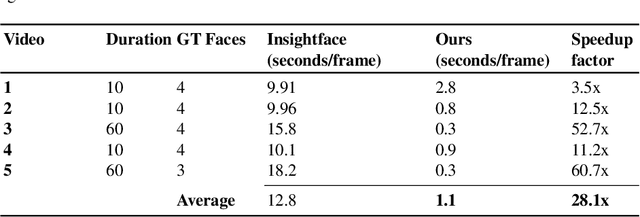
Face recognition in collaborative learning videos presents many challenges. In collaborative learning videos, students sit around a typical table at different positions to the recording camera, come and go, move around, get partially or fully occluded. Furthermore, the videos tend to be very long, requiring the development of fast and accurate methods. We develop a dynamic system of recognizing participants in collaborative learning systems. We address occlusion and recognition failures by using past information about the face detection history. We address the need for detecting faces from different poses and the need for speed by associating each participant with a collection of prototype faces computed through sampling or K-means clustering. Our results show that the proposed system is proven to be very fast and accurate. We also compare our system against a baseline system that uses InsightFace [2] and the original training video segments. We achieved an average accuracy of 86.2% compared to 70.8% for the baseline system. On average, our recognition rate was 28.1 times faster than the baseline system.