 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDETRPose: Real-time end-to-end transformer model for multi-person pose estimation
Jun 16, 2025Multi-person pose estimation (MPPE) estimates keypoints for all individuals present in an image. MPPE is a fundamental task for several applications in computer vision and virtual reality. Unfortunately, there are currently no transformer-based models that can perform MPPE in real time. The paper presents a family of transformer-based models capable of performing multi-person 2D pose estimation in real-time. Our approach utilizes a modified decoder architecture and keypoint similarity metrics to generate both positive and negative queries, thereby enhancing the quality of the selected queries within the architecture. Compared to state-of-the-art models, our proposed models train much faster, using 5 to 10 times fewer epochs, with competitive inference times without requiring quantization libraries to speed up the model. Furthermore, our proposed models provide competitive results or outperform alternative models, often using significantly fewer parameters.
LINEA: Fast and Accurate Line Detection Using Scalable Transformers
May 22, 2025Line detection is a basic digital image processing operation used by higher-level processing methods. Recently, transformer-based methods for line detection have proven to be more accurate than methods based on CNNs, at the expense of significantly lower inference speeds. As a result, video analysis methods that require low latencies cannot benefit from current transformer-based methods for line detection. In addition, current transformer-based models require pretraining attention mechanisms on large datasets (e.g., COCO or Object360). This paper develops a new transformer-based method that is significantly faster without requiring pretraining the attention mechanism on large datasets. We eliminate the need to pre-train the attention mechanism using a new mechanism, Deformable Line Attention (DLA). We use the term LINEA to refer to our new transformer-based method based on DLA. Extensive experiments show that LINEA is significantly faster and outperforms previous models on sAP in out-of-distribution dataset testing.
DT-LSD: Deformable Transformer-based Line Segment Detection
Nov 20, 2024



Line segment detection is a fundamental low-level task in computer vision, and improvements in this task can impact more advanced methods that depend on it. Most new methods developed for line segment detection are based on Convolutional Neural Networks (CNNs). Our paper seeks to address challenges that prevent the wider adoption of transformer-based methods for line segment detection. More specifically, we introduce a new model called Deformable Transformer-based Line Segment Detection (DT-LSD) that supports cross-scale interactions and can be trained quickly. This work proposes a novel Deformable Transformer-based Line Segment Detector (DT-LSD) that addresses LETR's drawbacks. For faster training, we introduce Line Contrastive DeNoising (LCDN), a technique that stabilizes the one-to-one matching process and speeds up training by 34$\times$. We show that DT-LSD is faster and more accurate than its predecessor transformer-based model (LETR) and outperforms all CNN-based models in terms of accuracy. In the Wireframe dataset, DT-LSD achieves 71.7 for $sAP^{10}$ and 73.9 for $sAP^{15}$; while 33.2 for $sAP^{10}$ and 35.1 for $sAP^{15}$ in the YorkUrban dataset.
Bilingual Speech Recognition by Estimating Speaker Geometry from Video Data
Dec 26, 2021
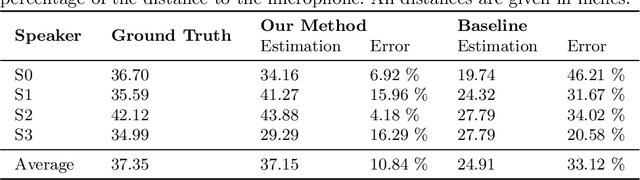
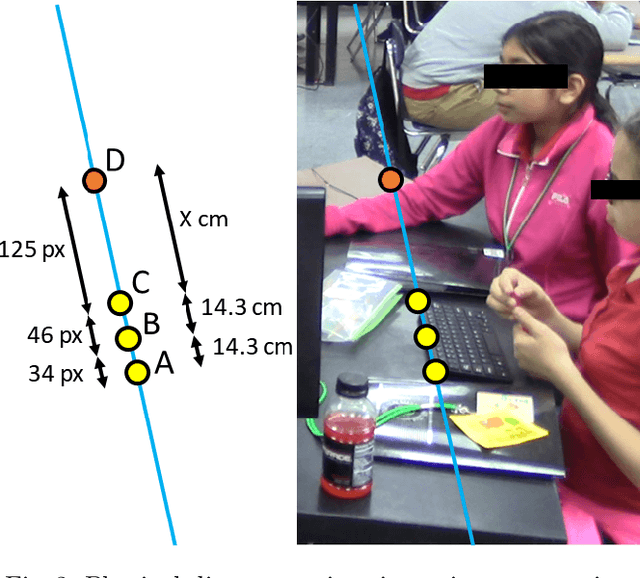
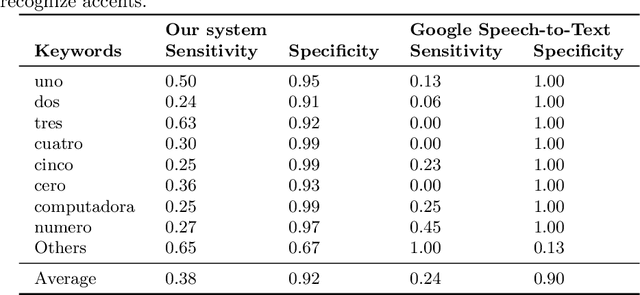
Speech recognition is very challenging in student learning environments that are characterized by significant cross-talk and background noise. To address this problem, we present a bilingual speech recognition system that uses an interactive video analysis system to estimate the 3D speaker geometry for realistic audio simulations. We demonstrate the use of our system in generating a complex audio dataset that contains significant cross-talk and background noise that approximate real-life classroom recordings. We then test our proposed system with real-life recordings. In terms of the distance of the speakers from the microphone, our interactive video analysis system obtained a better average error rate of 10.83% compared to 33.12% for a baseline approach. Our proposed system gave an accuracy of 27.92% that is 1.5% better than Google Speech-to-text on the same dataset. In terms of 9 important keywords, our approach gave an average sensitivity of 38% compared to 24% for Google Speech-to-text, while both methods maintained high average specificity of 90% and 92%. On average, sensitivity improved from 24% to 38% for our proposed approach. On the other hand, specificity remained high for both methods (90% to 92%).
* 11 pages, 6 figures
Fast 2D Convolutions and Cross-Correlations Using Scalable Architectures
Dec 24, 2021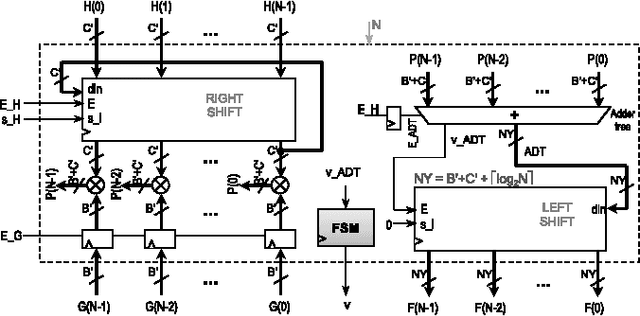

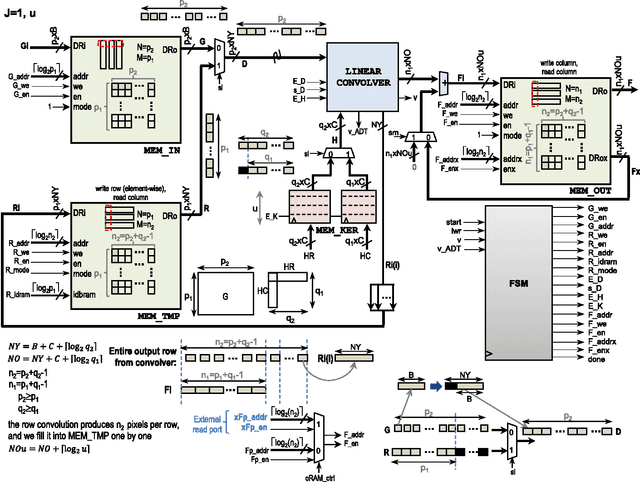
The manuscript describes fast and scalable architectures and associated algorithms for computing convolutions and cross-correlations. The basic idea is to map 2D convolutions and cross-correlations to a collection of 1D convolutions and cross-correlations in the transform domain. This is accomplished through the use of the Discrete Periodic Radon Transform (DPRT) for general kernels and the use of SVD-LU decompositions for low-rank kernels. The approach uses scalable architectures that can be fitted into modern FPGA and Zynq-SOC devices. Based on different types of available resources, for $P\times P$ blocks, 2D convolutions and cross-correlations can be computed in just $O(P)$ clock cycles up to $O(P^2)$ clock cycles. Thus, there is a trade-off between performance and required numbers and types of resources. We provide implementations of the proposed architectures using modern programmable devices (Virtex-7 and Zynq-SOC). Based on the amounts and types of required resources, we show that the proposed approaches significantly outperform current methods.
* The paper develops the fastest known methods for computing 2D convolutions in hardware
Fast and Scalable Computation of the Forward and Inverse Discrete Periodic Radon Transform
Dec 24, 2021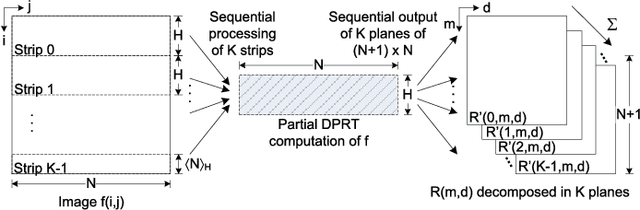
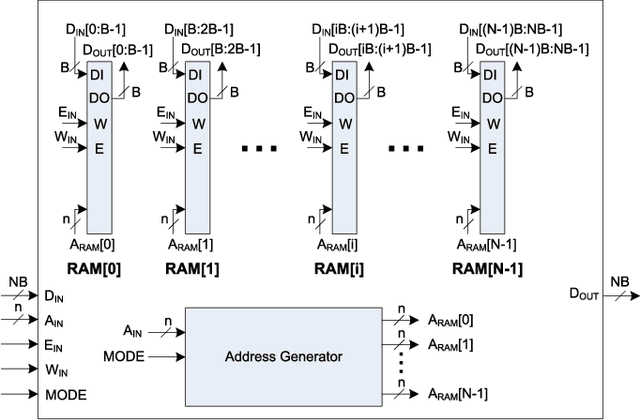

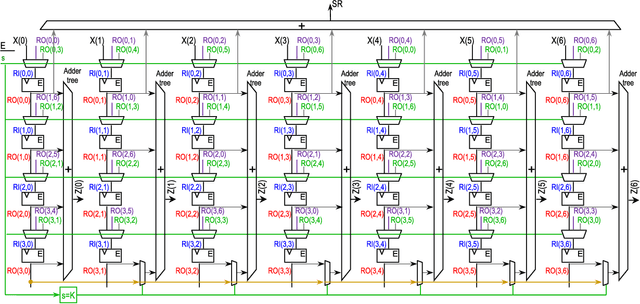
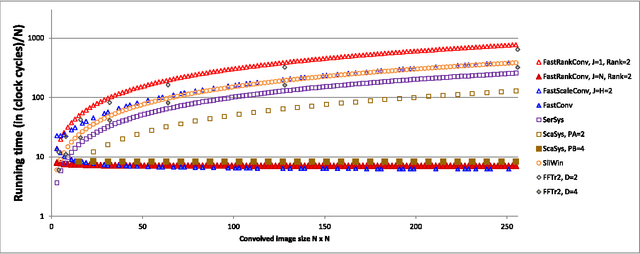
The Discrete Periodic Radon Transform (DPRT) has been extensively used in applications that involve image reconstructions from projections. This manuscript introduces a fast and scalable approach for computing the forward and inverse DPRT that is based on the use of: (i) a parallel array of fixed-point adder trees, (ii) circular shift registers to remove the need for accessing external memory components when selecting the input data for the adder trees, (iii) an image block-based approach to DPRT computation that can fit the proposed architecture to available resources, and (iv) fast transpositions that are computed in one or a few clock cycles that do not depend on the size of the input image. As a result, for an $N\times N$ image ($N$ prime), the proposed approach can compute up to $N^{2}$ additions per clock cycle. Compared to previous approaches, the scalable approach provides the fastest known implementations for different amounts of computational resources. For example, for a $251\times 251$ image, for approximately $25\%$ fewer flip-flops than required for a systolic implementation, we have that the scalable DPRT is computed 36 times faster. For the fastest case, we introduce optimized architectures that can compute the DPRT and its inverse in just $2N+\left\lceil \log_{2}N\right\rceil+1$ and $2N+3\left\lceil \log_{2}N\right\rceil+B+2$ cycles respectively, where $B$ is the number of bits used to represent each input pixel. On the other hand, the scalable DPRT approach requires more 1-bit additions than for the systolic implementation and provides a trade-off between speed and additional 1-bit additions. All of the proposed DPRT architectures were implemented in VHDL and validated using an FPGA implementation.
* This paper has been published as follows: C. Carranza, D. Llamocca, and M. Pattichis. "Fast and scalable computation of the forward and inverse discrete periodic radon transform", IEEE Transactions on Image Processing, 25(1):119-133, Jan 2016
Facial Recognition in Collaborative Learning Videos
Oct 25, 2021
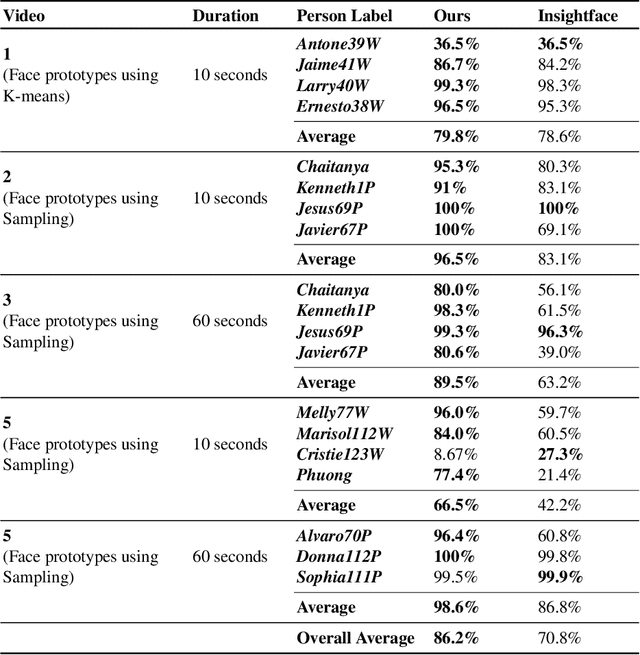
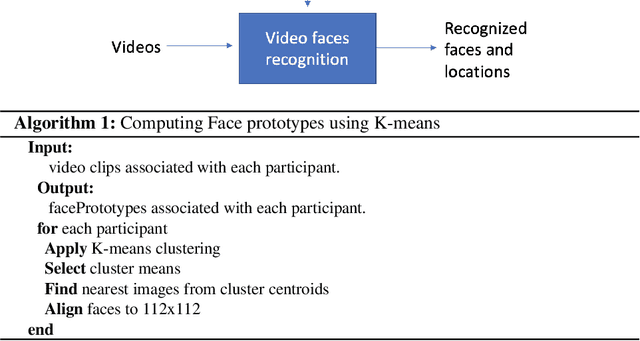
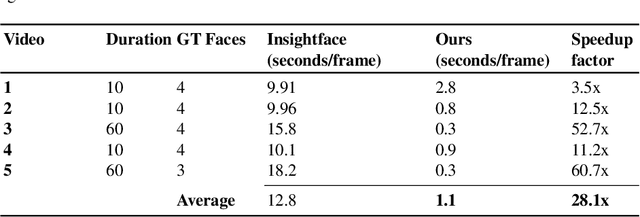
Face recognition in collaborative learning videos presents many challenges. In collaborative learning videos, students sit around a typical table at different positions to the recording camera, come and go, move around, get partially or fully occluded. Furthermore, the videos tend to be very long, requiring the development of fast and accurate methods. We develop a dynamic system of recognizing participants in collaborative learning systems. We address occlusion and recognition failures by using past information about the face detection history. We address the need for detecting faces from different poses and the need for speed by associating each participant with a collection of prototype faces computed through sampling or K-means clustering. Our results show that the proposed system is proven to be very fast and accurate. We also compare our system against a baseline system that uses InsightFace [2] and the original training video segments. We achieved an average accuracy of 86.2% compared to 70.8% for the baseline system. On average, our recognition rate was 28.1 times faster than the baseline system.
Adaptive Video Encoding For Different Video Codecs
May 17, 2021



By 2022, we expect video traffic to reach 82% of the total internet traffic. Undoubtedly, the abundance of video-driven applications will likely lead internet video traffic percentage to a further increase in the near future, enabled by associate advances in video devices' capabilities. In response to this ever-growing demand, the Alliance for Open Media (AOM) and the Joint Video Experts Team (JVET) have demonstrated strong and renewed interest in developing new video codecs. In the fast-changing video codecs' landscape, there is thus, a genuine need to develop adaptive methods that can be universally applied to different codecs. In this study, we formulate video encoding as a multi-objective optimization process where video quality (as a function of VMAF and PSNR), bitrate demands, and encoding rate (in encoded frames per second) are jointly optimized, going beyond the standard video encoding approaches that focus on rate control targeting specific bandwidths. More specifically, we create a dense video encoding space (offline) and then employ regression to generate forward prediction models for each one of the afore-described optimization objectives, using only Pareto-optimal points. We demonstrate our adaptive video encoding approach that leverages the generated forward prediction models that qualify for real-time adaptation using different codecs (e.g., SVT-AV1 and x265) for a variety of video datasets and resolutions. To motivate our approach and establish the promise for future fast VVC encoders, we also perform a comparative performance evaluation using both subjective and objective metrics and report on bitrate savings among all possible pairs between VVC, SVT-AV1, x265, and VP9 codecs.
* Video codecs, Video signal processing, Video coding, Video compression, Video quality, Video streaming, Adaptive video streaming, Versatile Video Coding, AV1, HEVC
Interpretable Neural Networks for Predicting Mortality Risk using Multi-modal Electronic Health Records
Jan 23, 2019
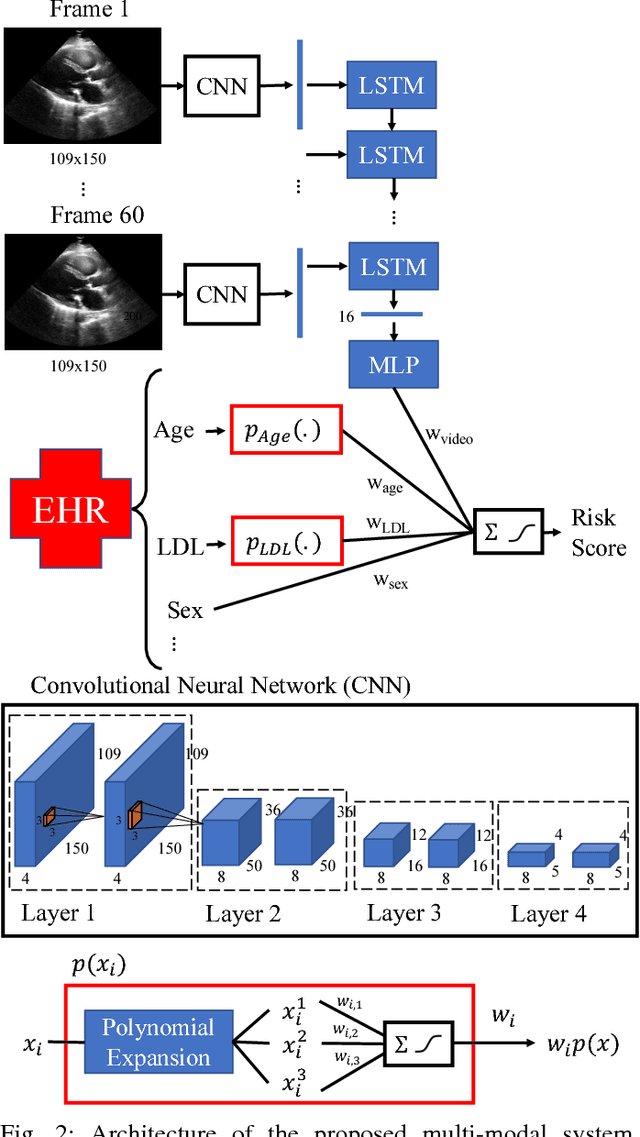

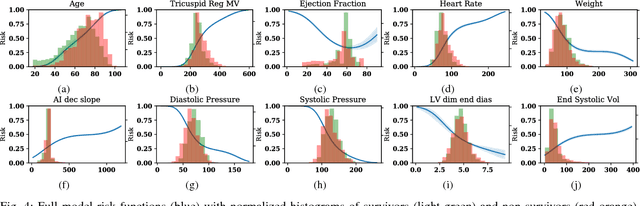
We present an interpretable neural network for predicting an important clinical outcome (1-year mortality) from multi-modal Electronic Health Record (EHR) data. Our approach builds on prior multi-modal machine learning models by now enabling visualization of how individual factors contribute to the overall outcome risk, assuming other factors remain constant, which was previously impossible. We demonstrate the value of this approach using a large multi-modal clinical dataset including both EHR data and 31,278 echocardiographic videos of the heart from 26,793 patients. We generated separate models for (i) clinical data only (CD) (e.g. age, sex, diagnoses and laboratory values), (ii) numeric variables derived from the videos, which we call echocardiography-derived measures (EDM), and (iii) CD+EDM+raw videos (pixel data). The interpretable multi-modal model maintained performance compared to non-interpretable models (Random Forest, XGBoost), and also performed significantly better than a model using a single modality (average AUC=0.82). Clinically relevant insights and multi-modal variable importance rankings were also facilitated by the new model, which have previously been impossible.