 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast 2D Convolutions and Cross-Correlations Using Scalable Architectures
Dec 24, 2021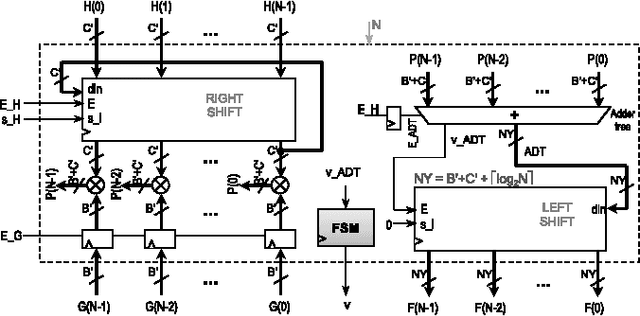

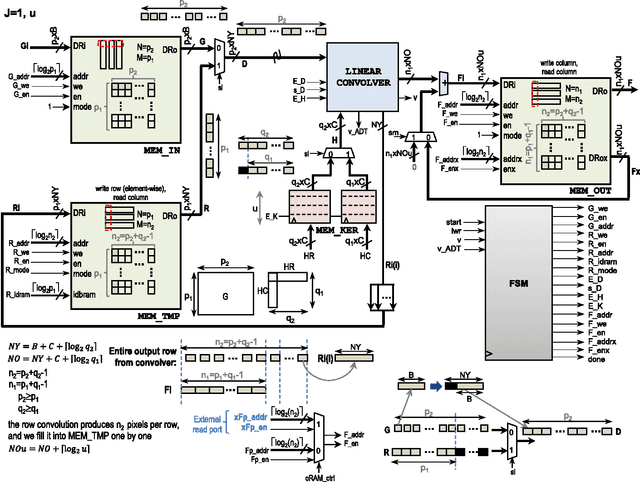
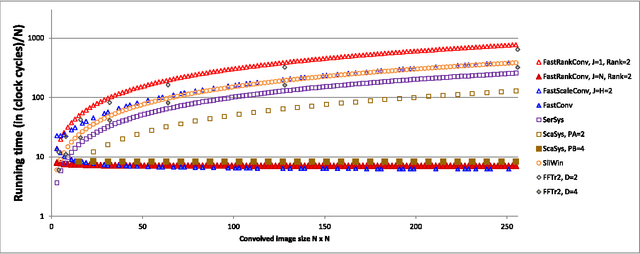
The manuscript describes fast and scalable architectures and associated algorithms for computing convolutions and cross-correlations. The basic idea is to map 2D convolutions and cross-correlations to a collection of 1D convolutions and cross-correlations in the transform domain. This is accomplished through the use of the Discrete Periodic Radon Transform (DPRT) for general kernels and the use of SVD-LU decompositions for low-rank kernels. The approach uses scalable architectures that can be fitted into modern FPGA and Zynq-SOC devices. Based on different types of available resources, for $P\times P$ blocks, 2D convolutions and cross-correlations can be computed in just $O(P)$ clock cycles up to $O(P^2)$ clock cycles. Thus, there is a trade-off between performance and required numbers and types of resources. We provide implementations of the proposed architectures using modern programmable devices (Virtex-7 and Zynq-SOC). Based on the amounts and types of required resources, we show that the proposed approaches significantly outperform current methods.
* The paper develops the fastest known methods for computing 2D convolutions in hardware
Fast and Scalable Computation of the Forward and Inverse Discrete Periodic Radon Transform
Dec 24, 2021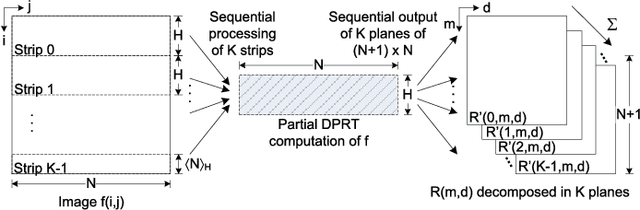
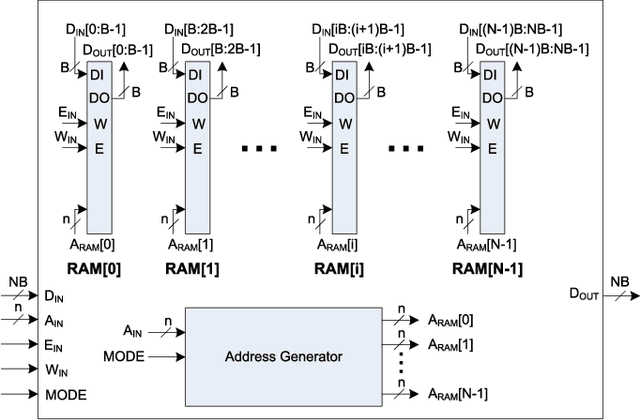

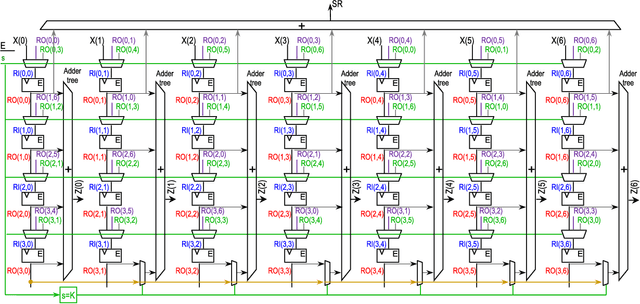
The Discrete Periodic Radon Transform (DPRT) has been extensively used in applications that involve image reconstructions from projections. This manuscript introduces a fast and scalable approach for computing the forward and inverse DPRT that is based on the use of: (i) a parallel array of fixed-point adder trees, (ii) circular shift registers to remove the need for accessing external memory components when selecting the input data for the adder trees, (iii) an image block-based approach to DPRT computation that can fit the proposed architecture to available resources, and (iv) fast transpositions that are computed in one or a few clock cycles that do not depend on the size of the input image. As a result, for an $N\times N$ image ($N$ prime), the proposed approach can compute up to $N^{2}$ additions per clock cycle. Compared to previous approaches, the scalable approach provides the fastest known implementations for different amounts of computational resources. For example, for a $251\times 251$ image, for approximately $25\%$ fewer flip-flops than required for a systolic implementation, we have that the scalable DPRT is computed 36 times faster. For the fastest case, we introduce optimized architectures that can compute the DPRT and its inverse in just $2N+\left\lceil \log_{2}N\right\rceil+1$ and $2N+3\left\lceil \log_{2}N\right\rceil+B+2$ cycles respectively, where $B$ is the number of bits used to represent each input pixel. On the other hand, the scalable DPRT approach requires more 1-bit additions than for the systolic implementation and provides a trade-off between speed and additional 1-bit additions. All of the proposed DPRT architectures were implemented in VHDL and validated using an FPGA implementation.
* This paper has been published as follows: C. Carranza, D. Llamocca, and M. Pattichis. "Fast and scalable computation of the forward and inverse discrete periodic radon transform", IEEE Transactions on Image Processing, 25(1):119-133, Jan 2016