 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Low-parameter Video Activity Localization in Collaborative Learning Environments
Mar 02, 2024
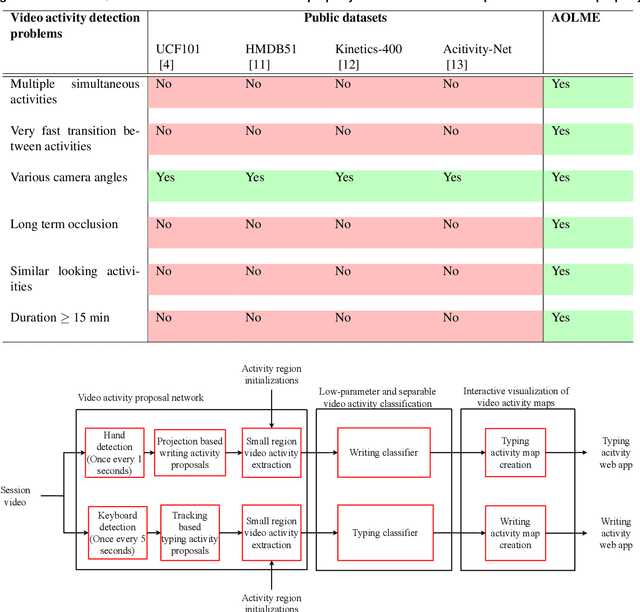


Research on video activity detection has primarily focused on identifying well-defined human activities in short video segments. The majority of the research on video activity recognition is focused on the development of large parameter systems that require training on large video datasets. This paper develops a low-parameter, modular system with rapid inferencing capabilities that can be trained entirely on limited datasets without requiring transfer learning from large-parameter systems. The system can accurately detect and associate specific activities with the students who perform the activities in real-life classroom videos. Additionally, the paper develops an interactive web-based application to visualize human activity maps over long real-life classroom videos.
A Review of Machine Learning Methods Applied to Video Analysis Systems
Dec 08, 2023The paper provides a survey of the development of machine-learning techniques for video analysis. The survey provides a summary of the most popular deep learning methods used for human activity recognition. We discuss how popular architectures perform on standard datasets and highlight the differences from real-life datasets dominated by multiple activities performed by multiple participants over long periods. For real-life datasets, we describe the use of low-parameter models (with 200X or 1,000X fewer parameters) that are trained to detect a single activity after the relevant objects have been successfully detected. Our survey then turns to a summary of machine learning methods that are specifically developed for working with a small number of labeled video samples. Our goal here is to describe modern techniques that are specifically designed so as to minimize the amount of ground truth that is needed for training and testing video analysis systems. We provide summaries of the development of self-supervised learning, semi-supervised learning, active learning, and zero-shot learning for applications in video analysis. For each method, we provide representative examples.
Automatic Segmentation of Coronal Holes in Solar Images and Solar Prediction Map Classification
Jul 20, 2022
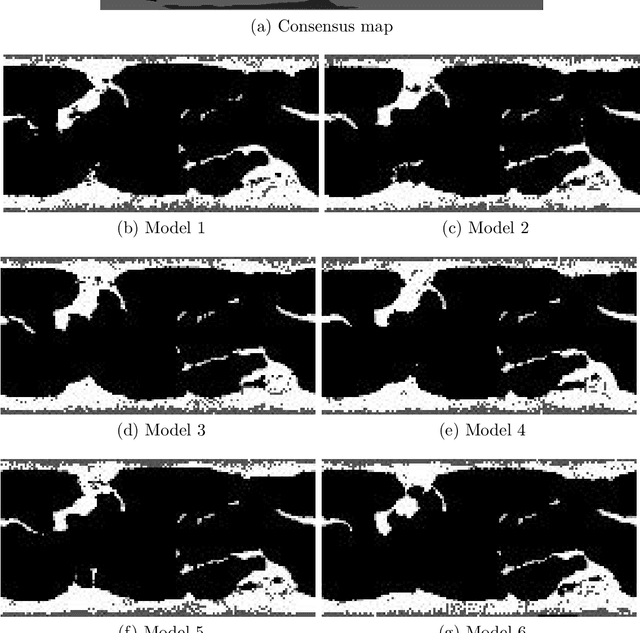

Solar image analysis relies on the detection of coronal holes for predicting disruptions to earth's magnetic field. The coronal holes act as sources of solar wind that can reach the earth. Thus, coronal holes are used in physical models for predicting the evolution of solar wind and its potential for interfering with the earth's magnetic field. Due to inherent uncertainties in the physical models, there is a need for a classification system that can be used to select the physical models that best match the observed coronal holes. The physical model classification problem is decomposed into three subproblems. First, he thesis develops a method for coronal hole segmentation. Second, the thesis develops methods for matching coronal holes from different maps. Third, based on the matching results, the thesis develops a physical map classification system. A level-set segmentation method is used for detecting coronal holes that are observed in extreme ultra-violet images (EUVI) and magnetic field images. For validating the segmentation approach, two independent manual segmentations were combined to produce 46 consensus maps. Overall, the level-set segmentation approach produces significant improvements over current approaches. Physical map classification is based on coronal hole matching between the physical maps and (i) the consensus maps (semi-automated), or (ii) the segmented maps (fully-automated). Based on the matching results, the system uses area differences,shortest distances between matched clusters, number and areas of new and missing coronal hole clusters to classify each map. The results indicate that the automated segmentation and classification system performs better than individual humans.
Bilingual Speech Recognition by Estimating Speaker Geometry from Video Data
Dec 26, 2021
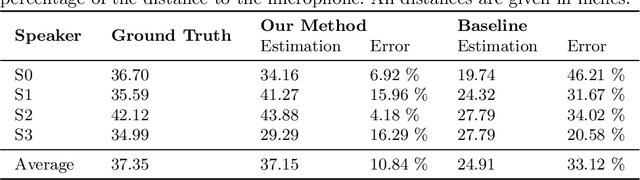
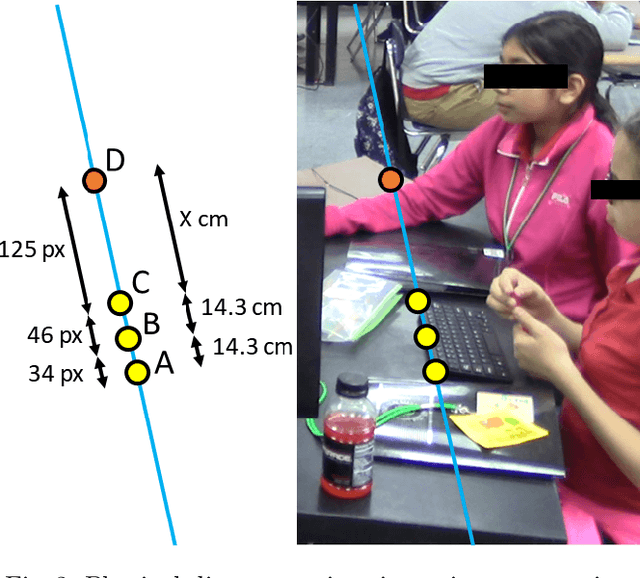
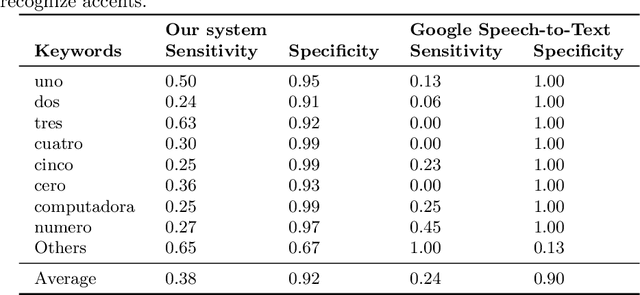
Speech recognition is very challenging in student learning environments that are characterized by significant cross-talk and background noise. To address this problem, we present a bilingual speech recognition system that uses an interactive video analysis system to estimate the 3D speaker geometry for realistic audio simulations. We demonstrate the use of our system in generating a complex audio dataset that contains significant cross-talk and background noise that approximate real-life classroom recordings. We then test our proposed system with real-life recordings. In terms of the distance of the speakers from the microphone, our interactive video analysis system obtained a better average error rate of 10.83% compared to 33.12% for a baseline approach. Our proposed system gave an accuracy of 27.92% that is 1.5% better than Google Speech-to-text on the same dataset. In terms of 9 important keywords, our approach gave an average sensitivity of 38% compared to 24% for Google Speech-to-text, while both methods maintained high average specificity of 90% and 92%. On average, sensitivity improved from 24% to 38% for our proposed approach. On the other hand, specificity remained high for both methods (90% to 92%).
* 11 pages, 6 figures
Fast Hand Detection in Collaborative Learning Environments
Oct 13, 2021

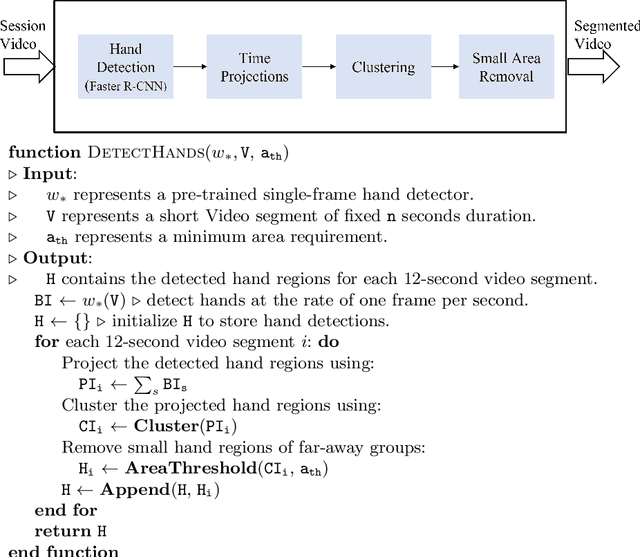

Long-term object detection requires the integration of frame-based results over several seconds. For non-deformable objects, long-term detection is often addressed using object detection followed by video tracking. Unfortunately, tracking is inapplicable to objects that undergo dramatic changes in appearance from frame to frame. As a related example, we study hand detection over long video recordings in collaborative learning environments. More specifically, we develop long-term hand detection methods that can deal with partial occlusions and dramatic changes in appearance. Our approach integrates object-detection, followed by time projections, clustering, and small region removal to provide effective hand detection over long videos. The hand detector achieved average precision (AP) of 72% at 0.5 intersection over union (IoU). The detection results were improved to 81% by using our optimized approach for data augmentation. The method runs at 4.7x the real-time with AP of 81% at 0.5 intersection over the union. Our method reduced the number of false-positive hand detections by 80% by improving IoU ratios from 0.2 to 0.5. The overall hand detection system runs at 4x real-time.
Adaptive Video Encoding For Different Video Codecs
May 17, 2021



By 2022, we expect video traffic to reach 82% of the total internet traffic. Undoubtedly, the abundance of video-driven applications will likely lead internet video traffic percentage to a further increase in the near future, enabled by associate advances in video devices' capabilities. In response to this ever-growing demand, the Alliance for Open Media (AOM) and the Joint Video Experts Team (JVET) have demonstrated strong and renewed interest in developing new video codecs. In the fast-changing video codecs' landscape, there is thus, a genuine need to develop adaptive methods that can be universally applied to different codecs. In this study, we formulate video encoding as a multi-objective optimization process where video quality (as a function of VMAF and PSNR), bitrate demands, and encoding rate (in encoded frames per second) are jointly optimized, going beyond the standard video encoding approaches that focus on rate control targeting specific bandwidths. More specifically, we create a dense video encoding space (offline) and then employ regression to generate forward prediction models for each one of the afore-described optimization objectives, using only Pareto-optimal points. We demonstrate our adaptive video encoding approach that leverages the generated forward prediction models that qualify for real-time adaptation using different codecs (e.g., SVT-AV1 and x265) for a variety of video datasets and resolutions. To motivate our approach and establish the promise for future fast VVC encoders, we also perform a comparative performance evaluation using both subjective and objective metrics and report on bitrate savings among all possible pairs between VVC, SVT-AV1, x265, and VP9 codecs.
* Video codecs, Video signal processing, Video coding, Video compression, Video quality, Video streaming, Adaptive video streaming, Versatile Video Coding, AV1, HEVC