 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Neural Network Systems for Image Analysis using Vector Spaces and Inverse Maps
Feb 01, 2024


There is strong interest in developing mathematical methods that can be used to understand complex neural networks used in image analysis. In this paper, we introduce techniques from Linear Algebra to model neural network layers as maps between signal spaces. First, we demonstrate how signal spaces can be used to visualize weight spaces and convolutional layer kernels. We also demonstrate how residual vector spaces can be used to further visualize information lost at each layer. Second, we introduce the concept of invertible networks and an algorithm for computing input images that yield specific outputs. We demonstrate our approach on two invertible networks and ResNet18.
A Review of Machine Learning Methods Applied to Video Analysis Systems
Dec 08, 2023The paper provides a survey of the development of machine-learning techniques for video analysis. The survey provides a summary of the most popular deep learning methods used for human activity recognition. We discuss how popular architectures perform on standard datasets and highlight the differences from real-life datasets dominated by multiple activities performed by multiple participants over long periods. For real-life datasets, we describe the use of low-parameter models (with 200X or 1,000X fewer parameters) that are trained to detect a single activity after the relevant objects have been successfully detected. Our survey then turns to a summary of machine learning methods that are specifically developed for working with a small number of labeled video samples. Our goal here is to describe modern techniques that are specifically designed so as to minimize the amount of ground truth that is needed for training and testing video analysis systems. We provide summaries of the development of self-supervised learning, semi-supervised learning, active learning, and zero-shot learning for applications in video analysis. For each method, we provide representative examples.
The Importance of the Instantaneous Phase for classification using Convolutional Neural Networks
Jul 01, 2022



Large-scale training of Convolutional Neural Networks (CNN) is extremely demanding in terms of computational resources. Also, for specific applications, the standard use of transfer learning also tends to require far more resources than what may be needed. This work examines the impact of using AM-FM representations as input images for CNN classification applications. A comparison was made between AM-FM components combinations and grayscale images as inputs for reduced and complete networks. The results showed that only the phase component produced significant predictions within a simple network. Neither IA or gray scale image were able to induce any learning in the system. Furthermore, the FM results were 7x faster during training and used 123x less parameters compared to state-of-the-art MobileNetV2 architecture, while maintaining comparable performance (AUC of 0.78 vs 0.79).
Person Detection in Collaborative Group Learning Environments Using Multiple Representations
Dec 22, 2021
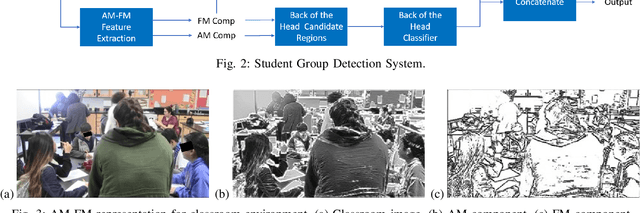
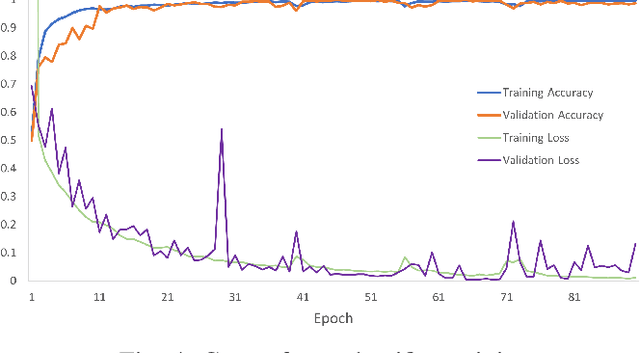
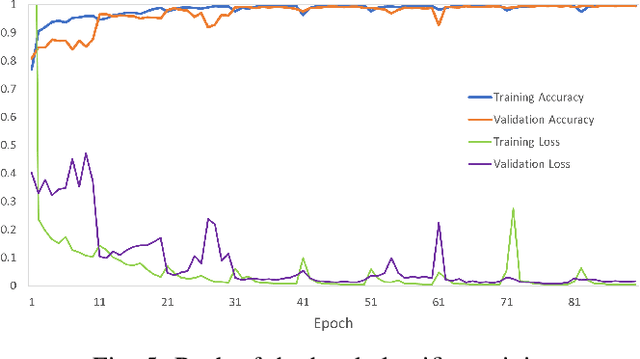
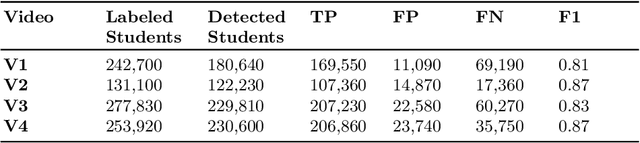
We introduce the problem of detecting a group of students from classroom videos. The problem requires the detection of students from different angles and the separation of the group from other groups in long videos (one to one and a half hours). We use multiple image representations to solve the problem. We use FM components to separate each group from background groups, AM-FM components for detecting the back-of-the-head, and YOLO for face detection. We use classroom videos from four different groups to validate our approach. Our use of multiple representations is shown to be significantly more accurate than the use of YOLO alone.
Talking Detection In Collaborative Learning Environments
Oct 14, 2021
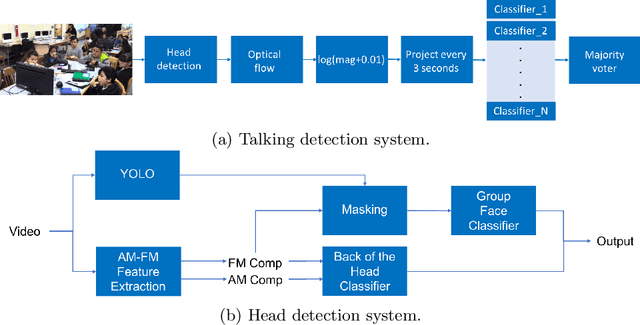

We study the problem of detecting talking activities in collaborative learning videos. Our approach uses head detection and projections of the log-magnitude of optical flow vectors to reduce the problem to a simple classification of small projection images without the need for training complex, 3-D activity classification systems. The small projection images are then easily classified using a simple majority vote of standard classifiers. For talking detection, our proposed approach is shown to significantly outperform single activity systems. We have an overall accuracy of 59% compared to 42% for Temporal Segment Network (TSN) and 45% for Convolutional 3D (C3D). In addition, our method is able to detect multiple talking instances from multiple speakers, while also detecting the speakers themselves.
Fast Hand Detection in Collaborative Learning Environments
Oct 13, 2021

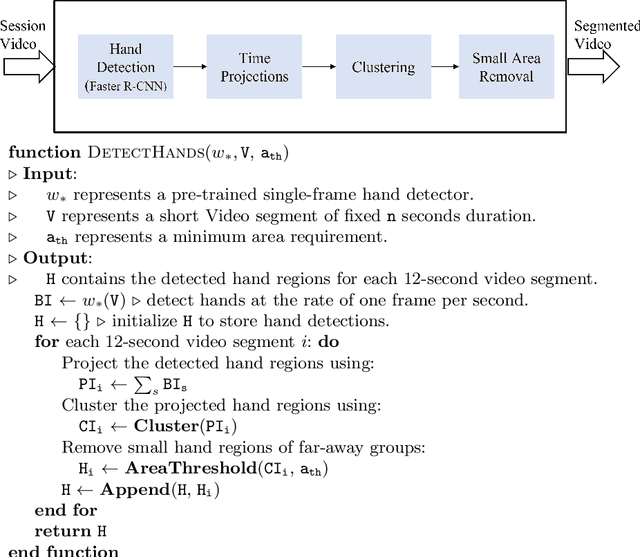

Long-term object detection requires the integration of frame-based results over several seconds. For non-deformable objects, long-term detection is often addressed using object detection followed by video tracking. Unfortunately, tracking is inapplicable to objects that undergo dramatic changes in appearance from frame to frame. As a related example, we study hand detection over long video recordings in collaborative learning environments. More specifically, we develop long-term hand detection methods that can deal with partial occlusions and dramatic changes in appearance. Our approach integrates object-detection, followed by time projections, clustering, and small region removal to provide effective hand detection over long videos. The hand detector achieved average precision (AP) of 72% at 0.5 intersection over union (IoU). The detection results were improved to 81% by using our optimized approach for data augmentation. The method runs at 4.7x the real-time with AP of 81% at 0.5 intersection over the union. Our method reduced the number of false-positive hand detections by 80% by improving IoU ratios from 0.2 to 0.5. The overall hand detection system runs at 4x real-time.
Multidataset Independent Subspace Analysis with Application to Multimodal Fusion
Nov 11, 2019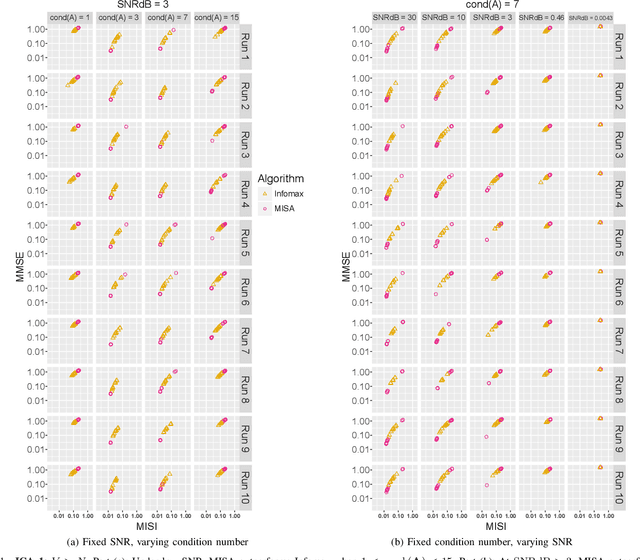
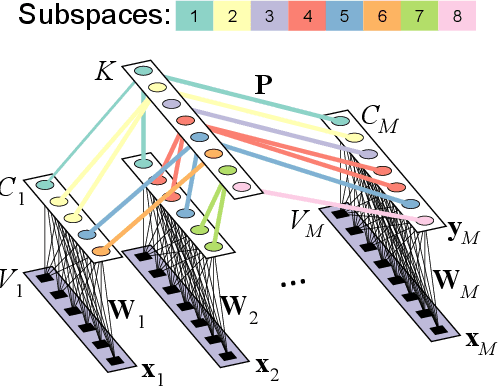
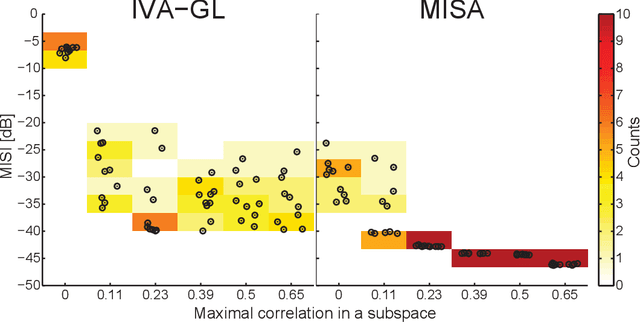
In the last two decades, unsupervised latent variable models---blind source separation (BSS) especially---have enjoyed a strong reputation for the interpretable features they produce. Seldom do these models combine the rich diversity of information available in multiple datasets. Multidatasets, on the other hand, yield joint solutions otherwise unavailable in isolation, with a potential for pivotal insights into complex systems. To take advantage of the complex multidimensional subspace structures that capture underlying modes of shared and unique variability across and within datasets, we present a direct, principled approach to multidataset combination. We design a new method called multidataset independent subspace analysis (MISA) that leverages joint information from multiple heterogeneous datasets in a flexible and synergistic fashion. Methodological innovations exploiting the Kotz distribution for subspace modeling in conjunction with a novel combinatorial optimization for evasion of local minima enable MISA to produce a robust generalization of independent component analysis (ICA), independent vector analysis (IVA), and independent subspace analysis (ISA) in a single unified model. We highlight the utility of MISA for multimodal information fusion, including sample-poor regimes and low signal-to-noise ratio scenarios, promoting novel applications in both unimodal and multimodal brain imaging data.