 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of the Instantaneous Phase in Detecting Faces with Convolutional Neural Networks
Aug 03, 2022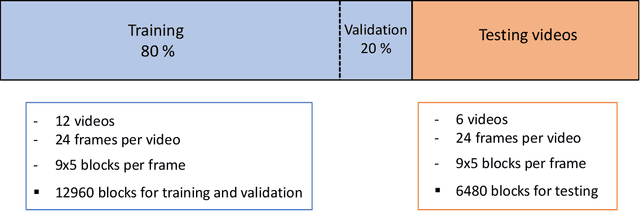

Convolutional Neural Networks (CNN) have provided new and accurate methods for processing digital images and videos. Yet, training CNNs is extremely demanding in terms of computational resources. Also, for specific applications, the standard use of transfer learning also tends to require far more resources than what may be needed. Furthermore, the final systems tend to operate as black boxes that are difficult to interpret. The current thesis considers the problem of detecting faces from the AOLME video dataset. The AOLME dataset consists of a large video collection of group interactions that are recorded in unconstrained classroom environments. For the thesis, still image frames were extracted at every minute from 18 24-minute videos. Then, each video frame was divided into 9x5 blocks with 50x50 pixels each. For each of the 19440 blocks, the percentage of face pixels was set as ground truth. Face detection was then defined as a regression problem for determining the face pixel percentage for each block. For testing different methods, 12 videos were used for training and validation. The remaining 6 videos were used for testing. The thesis examines the impact of using the instantaneous phase for the AOLME block-based face detection application. For comparison, the thesis compares the use of the Frequency Modulation image based on the instantaneous phase, the use of the instantaneous amplitude, and the original gray scale image. To generate the FM and AM inputs, the thesis uses dominant component analysis that aims to decrease the training overhead while maintaining interpretability.
The Importance of the Instantaneous Phase for classification using Convolutional Neural Networks
Jul 01, 2022



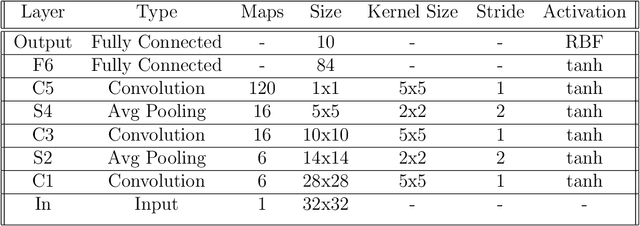
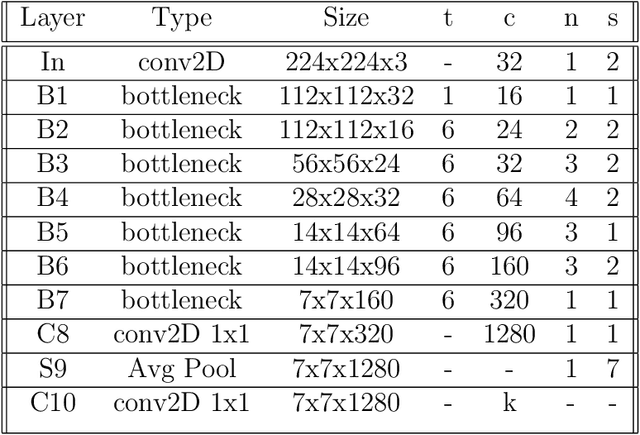
Large-scale training of Convolutional Neural Networks (CNN) is extremely demanding in terms of computational resources. Also, for specific applications, the standard use of transfer learning also tends to require far more resources than what may be needed. This work examines the impact of using AM-FM representations as input images for CNN classification applications. A comparison was made between AM-FM components combinations and grayscale images as inputs for reduced and complete networks. The results showed that only the phase component produced significant predictions within a simple network. Neither IA or gray scale image were able to induce any learning in the system. Furthermore, the FM results were 7x faster during training and used 123x less parameters compared to state-of-the-art MobileNetV2 architecture, while maintaining comparable performance (AUC of 0.78 vs 0.79).
Bilingual Speech Recognition by Estimating Speaker Geometry from Video Data
Dec 26, 2021
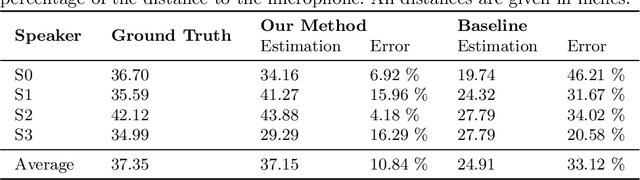
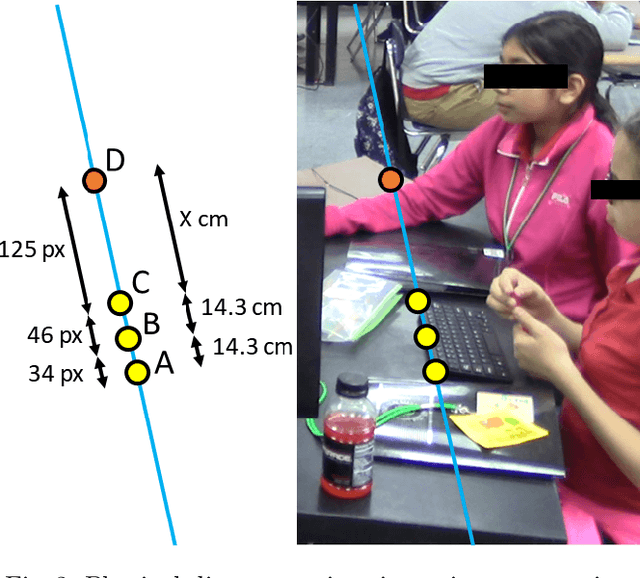
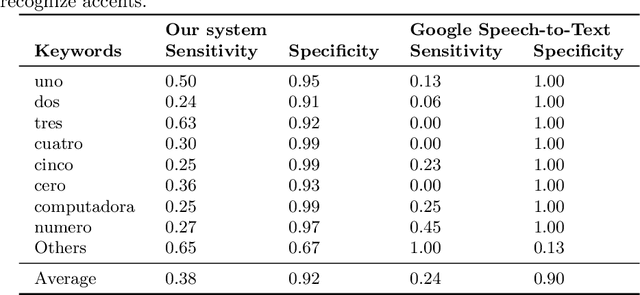
Speech recognition is very challenging in student learning environments that are characterized by significant cross-talk and background noise. To address this problem, we present a bilingual speech recognition system that uses an interactive video analysis system to estimate the 3D speaker geometry for realistic audio simulations. We demonstrate the use of our system in generating a complex audio dataset that contains significant cross-talk and background noise that approximate real-life classroom recordings. We then test our proposed system with real-life recordings. In terms of the distance of the speakers from the microphone, our interactive video analysis system obtained a better average error rate of 10.83% compared to 33.12% for a baseline approach. Our proposed system gave an accuracy of 27.92% that is 1.5% better than Google Speech-to-text on the same dataset. In terms of 9 important keywords, our approach gave an average sensitivity of 38% compared to 24% for Google Speech-to-text, while both methods maintained high average specificity of 90% and 92%. On average, sensitivity improved from 24% to 38% for our proposed approach. On the other hand, specificity remained high for both methods (90% to 92%).
* 11 pages, 6 figures