 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of the Instantaneous Phase in Detecting Faces with Convolutional Neural Networks
Paper and Code
Aug 03, 2022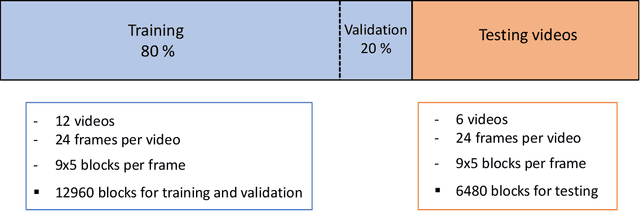

Convolutional Neural Networks (CNN) have provided new and accurate methods for processing digital images and videos. Yet, training CNNs is extremely demanding in terms of computational resources. Also, for specific applications, the standard use of transfer learning also tends to require far more resources than what may be needed. Furthermore, the final systems tend to operate as black boxes that are difficult to interpret. The current thesis considers the problem of detecting faces from the AOLME video dataset. The AOLME dataset consists of a large video collection of group interactions that are recorded in unconstrained classroom environments. For the thesis, still image frames were extracted at every minute from 18 24-minute videos. Then, each video frame was divided into 9x5 blocks with 50x50 pixels each. For each of the 19440 blocks, the percentage of face pixels was set as ground truth. Face detection was then defined as a regression problem for determining the face pixel percentage for each block. For testing different methods, 12 videos were used for training and validation. The remaining 6 videos were used for testing. The thesis examines the impact of using the instantaneous phase for the AOLME block-based face detection application. For comparison, the thesis compares the use of the Frequency Modulation image based on the instantaneous phase, the use of the instantaneous amplitude, and the original gray scale image. To generate the FM and AM inputs, the thesis uses dominant component analysis that aims to decrease the training overhead while maintaining interpretability.