 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Surveillance Camera FOV Quality via Semantic Line Detection and Classification with Deep Hough Transform
Jan 17, 2024The quality of recorded videos and images is significantly influenced by the camera's field of view (FOV). In critical applications like surveillance systems and self-driving cars, an inadequate FOV can give rise to severe safety and security concerns, including car accidents and thefts due to the failure to detect individuals and objects. The conventional methods for establishing the correct FOV heavily rely on human judgment and lack automated mechanisms to assess video and image quality based on FOV. In this paper, we introduce an innovative approach that harnesses semantic line detection and classification alongside deep Hough transform to identify semantic lines, thus ensuring a suitable FOV by understanding 3D view through parallel lines. Our approach yields an effective F1 score of 0.729 on the public EgoCart dataset, coupled with a notably high median score in the line placement metric. We illustrate that our method offers a straightforward means of assessing the quality of the camera's field of view, achieving a classification accuracy of 83.8\%. This metric can serve as a proxy for evaluating the potential performance of video and image quality applications.
Human Attention Detection Using AM-FM Representations
Mar 09, 2022
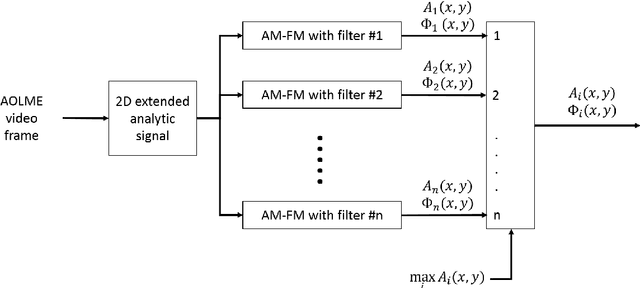
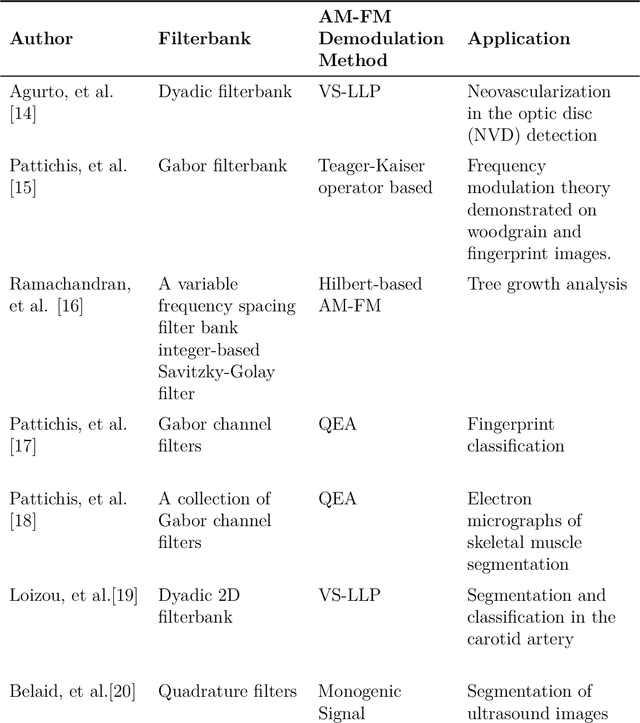

Human activity detection from digital videos presents many challenges to the computer vision and image processing communities. Recently, many methods have been developed to detect human activities with varying degree of success. Yet, the general human activity detection problem remains very challenging, especially when the methods need to work 'in the wild' (e.g., without having precise control over the imaging geometry). The thesis explores phase-based solutions for (i) detecting faces, (ii) back of the heads, (iii) joint detection of faces and back of the heads, and (iv) whether the head is looking to the left or the right, using standard video cameras without any control on the imaging geometry. The proposed phase-based approach is based on the development of simple and robust methods that rely on the use of Amplitude Modulation- Frequency Modulation (AM-FM) models. The approach is validated using video frames extracted from the Advancing Out-of-school Learning in Mathematics and Engineering (AOLME) project. The dataset consisted of 13,265 images from ten students looking at the camera, and 6,122 images from five students looking away from the camera. For the students facing the camera, the method was able to correctly classify 97.1% of them looking to the left and 95.9% of them looking to the right. For the students facing the back of the camera, the method was able to correctly classify 87.6% of them looking to the left and 93.3% of them looking to the right. The results indicate that AM-FM based methods hold great promise for analyzing human activity videos.
Person Detection in Collaborative Group Learning Environments Using Multiple Representations
Dec 22, 2021
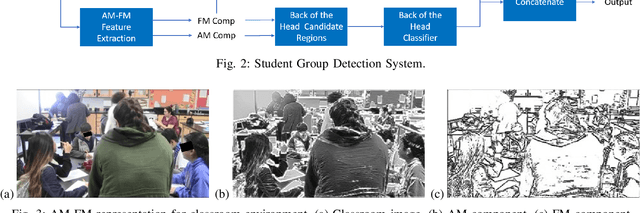
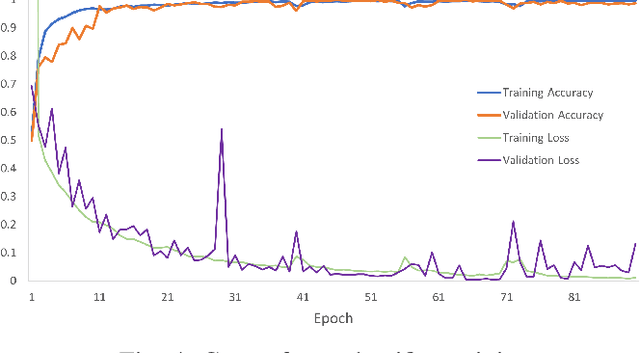
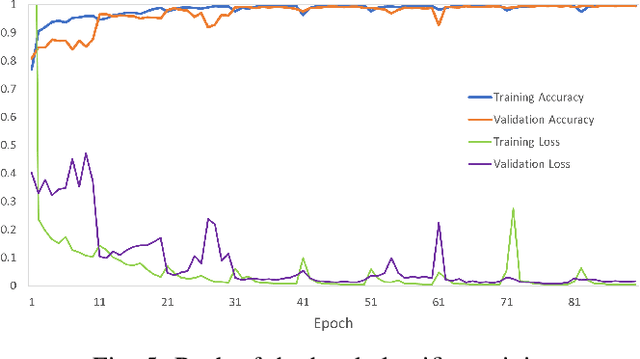
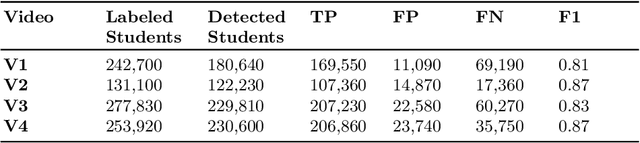
We introduce the problem of detecting a group of students from classroom videos. The problem requires the detection of students from different angles and the separation of the group from other groups in long videos (one to one and a half hours). We use multiple image representations to solve the problem. We use FM components to separate each group from background groups, AM-FM components for detecting the back-of-the-head, and YOLO for face detection. We use classroom videos from four different groups to validate our approach. Our use of multiple representations is shown to be significantly more accurate than the use of YOLO alone.
Talking Detection In Collaborative Learning Environments
Oct 14, 2021
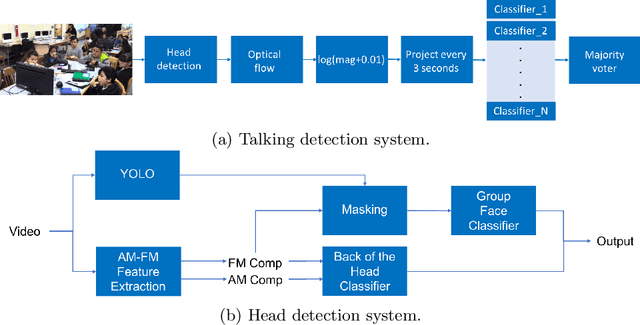

We study the problem of detecting talking activities in collaborative learning videos. Our approach uses head detection and projections of the log-magnitude of optical flow vectors to reduce the problem to a simple classification of small projection images without the need for training complex, 3-D activity classification systems. The small projection images are then easily classified using a simple majority vote of standard classifiers. For talking detection, our proposed approach is shown to significantly outperform single activity systems. We have an overall accuracy of 59% compared to 42% for Temporal Segment Network (TSN) and 45% for Convolutional 3D (C3D). In addition, our method is able to detect multiple talking instances from multiple speakers, while also detecting the speakers themselves.