 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-DreamBooth: Protecting users from personalized text-to-image synthesis
Mar 27, 2023Text-to-image diffusion models are nothing but a revolution, allowing anyone, even without design skills, to create realistic images from simple text inputs. With powerful personalization tools like DreamBooth, they can generate images of a specific person just by learning from his/her few reference images. However, when misused, such a powerful and convenient tool can produce fake news or disturbing content targeting any individual victim, posing a severe negative social impact. In this paper, we explore a defense system called Anti-DreamBooth against such malicious use of DreamBooth. The system aims to add subtle noise perturbation to each user's image before publishing in order to disrupt the generation quality of any DreamBooth model trained on these perturbed images. We investigate a wide range of algorithms for perturbation optimization and extensively evaluate them on two facial datasets over various text-to-image model versions. Despite the complicated formulation of DreamBooth and Diffusion-based text-to-image models, our methods effectively defend users from the malicious use of those models. Their effectiveness withstands even adverse conditions, such as model or prompt/term mismatching between training and testing. Our code will be available at \href{https://github.com/VinAIResearch/Anti-DreamBooth.git}{https://github.com/VinAIResearch/Anti-DreamBooth.git}.
Stochastic Multiple Target Sampling Gradient Descent
Jun 04, 2022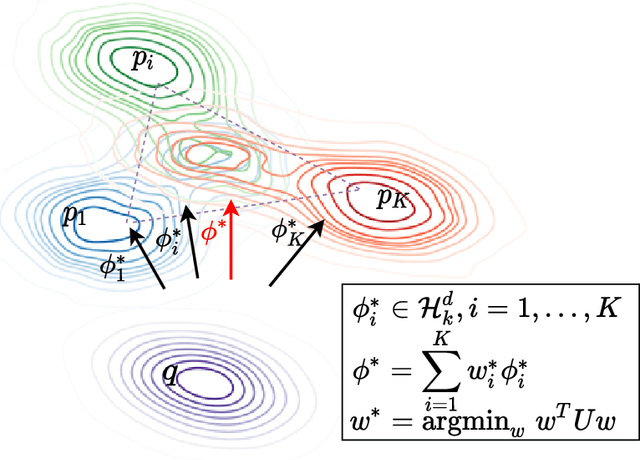

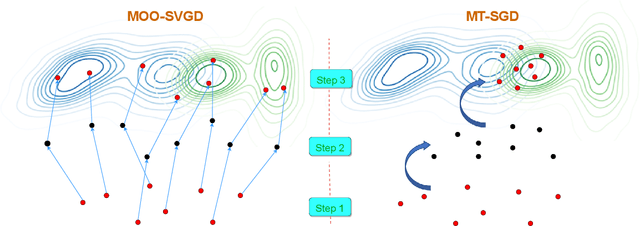
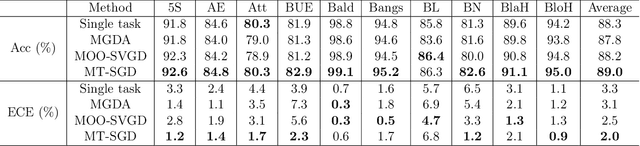
Sampling from an unnormalized target distribution is an essential problem with many applications in probabilistic inference. Stein Variational Gradient Descent (SVGD) has been shown to be a powerful method that iteratively updates a set of particles to approximate the distribution of interest. Furthermore, when analysing its asymptotic properties, SVGD reduces exactly to a single-objective optimization problem and can be viewed as a probabilistic version of this single-objective optimization problem. A natural question then arises: "Can we derive a probabilistic version of the multi-objective optimization?". To answer this question, we propose Stochastic Multiple Target Sampling Gradient Descent (MT-SGD), enabling us to sample from multiple unnormalized target distributions. Specifically, our MT-SGD conducts a flow of intermediate distributions gradually orienting to multiple target distributions, which allows the sampled particles to move to the joint high-likelihood region of the target distributions. Interestingly, the asymptotic analysis shows that our approach reduces exactly to the multiple-gradient descent algorithm for multi-objective optimization, as expected. Finally, we conduct comprehensive experiments to demonstrate the merit of our approach to multi-task learning.
Stochastic geometry to generalize the Mondrian Process
Feb 03, 2020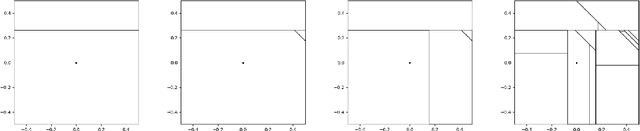
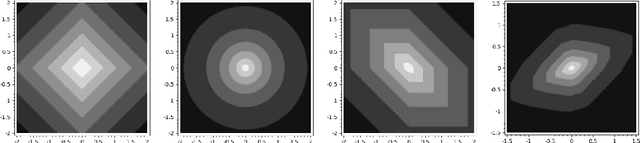
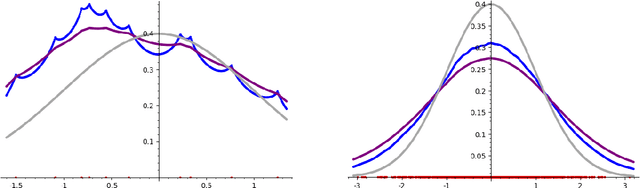
The Mondrian process is a stochastic process that produces a recursive partition of space with random axis-aligned cuts. Random forests and Laplace kernel approximations built from the Mondrian process have led to efficient online learning methods and Bayesian optimization. By viewing the Mondrian process as a special case of the stable under iterated tessellation (STIT) process, we utilize tools from stochastic geometry to resolve three fundamental questions concern generalizability of the Mondrian process in machine learning. First, we show that the Mondrian process with general cut directions can be efficiently simulated, but it is unlikely to give rise to better classification or regression algorithms. Second, we characterize all possible kernels that generalizations of the Mondrian process can approximate. This includes, for instance, various forms of the weighted Laplace kernel and the exponential kernel. Third, we give an explicit formula for the density estimator arising from a Mondrian forest. This allows for precise comparisons between the Mondrian forest, the Mondrian kernel and the Laplace kernel in density estimation. Our paper calls for further developments at the novel intersection of stochastic geometry and machine learning.
Does BLEU Score Work for Code Migration?
Jun 12, 2019

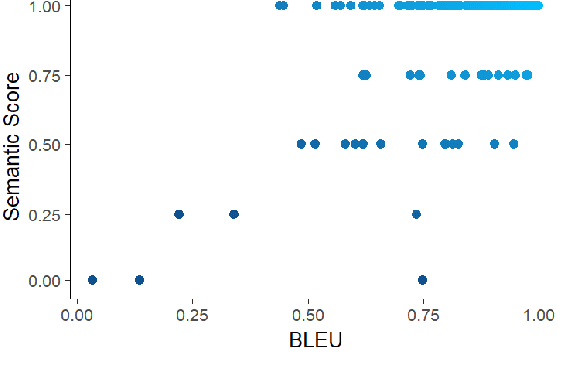

Statistical machine translation (SMT) is a fast-growing sub-field of computational linguistics. Until now, the most popular automatic metric to measure the quality of SMT is BiLingual Evaluation Understudy (BLEU) score. Lately, SMT along with the BLEU metric has been applied to a Software Engineering task named code migration. (In)Validating the use of BLEU score could advance the research and development of SMT-based code migration tools. Unfortunately, there is no study to approve or disapprove the use of BLEU score for source code. In this paper, we conducted an empirical study on BLEU score to (in)validate its suitability for the code migration task due to its inability to reflect the semantics of source code. In our work, we use human judgment as the ground truth to measure the semantic correctness of the migrated code. Our empirical study demonstrates that BLEU does not reflect translation quality due to its weak correlation with the semantic correctness of translated code. We provided counter-examples to show that BLEU is ineffective in comparing the translation quality between SMT-based models. Due to BLEU's ineffectiveness for code migration task, we propose an alternative metric RUBY, which considers lexical, syntactical, and semantic representations of source code. We verified that RUBY achieves a higher correlation coefficient with the semantic correctness of migrated code, 0.775 in comparison with 0.583 of BLEU score. We also confirmed the effectiveness of RUBY in reflecting the changes in translation quality of SMT-based translation models. With its advantages, RUBY can be used to evaluate SMT-based code migration models.