 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Routing as Reasoning: A MaxSAT View
Mar 13, 2026Routing a query through an appropriate LLM is challenging, particularly when user preferences are expressed in natural language and model attributes are only partially observable. We propose a constraint-based interpretation of language-conditioned LLM routing, formulating it as a weighted MaxSAT/MaxSMT problem in which natural language feedback induces hard and soft constraints over model attributes. Under this view, routing corresponds to selecting models that approximately maximize satisfaction of feedback-conditioned clauses. Empirical analysis on a 25-model benchmark shows that language feedback produces near-feasible recommendation sets, while no-feedback scenarios reveal systematic priors. Our results suggest that LLM routing can be understood as structured constraint optimization under language-conditioned preferences.
A Multi-Agent Framework for Code-Guided, Modular, and Verifiable Automated Machine Learning
Feb 15, 2026Automated Machine Learning (AutoML) has revolutionized the development of data-driven solutions; however, traditional frameworks often function as "black boxes", lacking the flexibility and transparency required for complex, real-world engineering tasks. Recent Large Language Model (LLM)-based agents have shifted toward code-driven approaches. However, they frequently suffer from hallucinated logic and logic entanglement, where monolithic code generation leads to unrecoverable runtime failures. In this paper, we present iML, a novel multi-agent framework designed to shift AutoML from black-box prompting to a code-guided, modular, and verifiable architectural paradigm. iML introduces three main ideas: (1) Code-Guided Planning, which synthesizes a strategic blueprint grounded in autonomous empirical profiling to eliminate hallucination; (2) Code-Modular Implementation, which decouples preprocessing and modeling into specialized components governed by strict interface contracts; and (3) Code-Verifiable Integration, which enforces physical feasibility through dynamic contract verification and iterative self-correction. We evaluate iML across MLE-BENCH and the newly introduced iML-BENCH, comprising a diverse range of real-world Kaggle competitions. The experimental results show iML's superiority over state-of-the-art agents, achieving a valid submission rate of 85% and a competitive medal rate of 45% on MLE-BENCH, with an average standardized performance score (APS) of 0.77. On iML-BENCH, iML significantly outperforms the other approaches by 38%-163% in APS. Furthermore, iML maintains a robust 70% success rate even under stripped task descriptions, effectively filling information gaps through empirical profiling. These results highlight iML's potential to bridge the gap between stochastic generation and reliable engineering, marking a meaningful step toward truly AutoML.
BRIDGE: Budget-aware Reasoning via Intermediate Distillation with Guided Examples
Dec 23, 2025Distilling knowledge from large proprietary models (e.g., GPT-4) to tiny deployable models (less than 1B parameters) faces a critical capacity-budget trap: the 1000x capacity gap between teachers and students prevents effective direct transfer, while API costs prohibit extensive data collection. We introduce BRIDGE (Budget-Aware Reasoning via Intermediate Distillation), a two-phase framework that resolves these constraints through strategic intermediation and budget asymmetry. In Phase 1, a mid-sized Teacher Assistant (TA; e.g., about 7B) learns from the black-box teacher on a strictly limited subset of data (e.g., 3-5%), selected via a zero-API-cost pipeline that balances entropic difficulty and semantic diversity using only local TA inference. In Phase 2, we exploit this asymmetry-teacher queries are expensive, whereas TA inference is free to amplify supervision: the refined TA generates synthetic rationales for the full dataset to train the tiny student. Crucially, we apply an instruction-tuning curriculum to establish behavioral alignment in the tiny student before transferring reasoning. Our theoretical analysis shows that BRIDGE yields tighter generalization bounds than direct distillation when data is abundant. Experiments across medical, legal, and financial benchmarks demonstrate consistent improvements: BRIDGE delivers student performance gains of 28-41%, closing the capability gap with proprietary teachers by 12-16% while using 10x fewer teacher queries. Notably, BRIDGE defies the conventional cost-performance frontier, surpassing direct distillation baselines that use 100% of the budget while consuming only 5% of the resources.
Improving Adaptive Moment Optimization via Preconditioner Diagonalization
Feb 11, 2025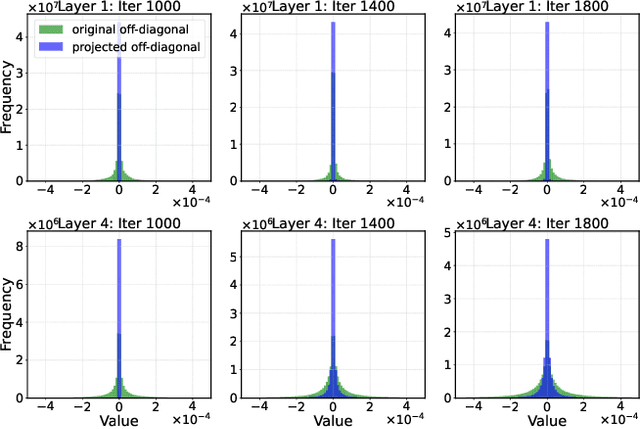
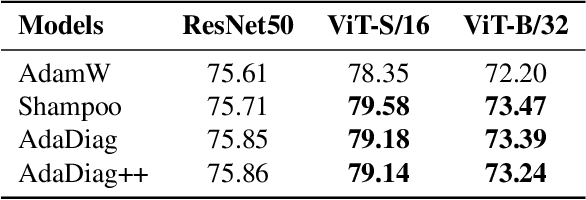
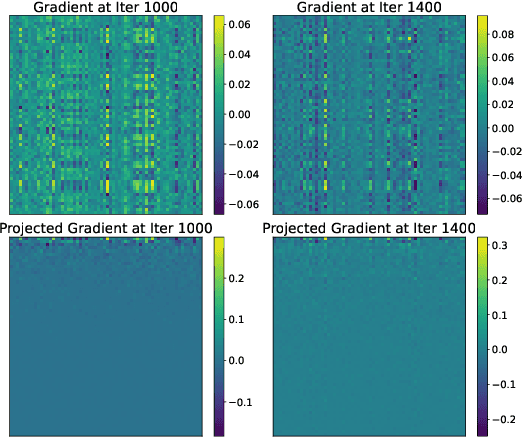
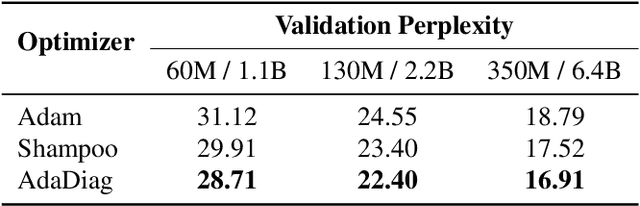
Modern adaptive optimization methods, such as Adam and its variants, have emerged as the most widely used tools in deep learning over recent years. These algorithms offer automatic mechanisms for dynamically adjusting the update step based on estimates of gradient statistics. Compared to traditional algorithms like Stochastic Gradient Descent, these adaptive methods are typically more robust to model scale and hyperparameter tuning. However, the gradient statistics employed by these methods often do not leverage sufficient gradient covariance information, leading to suboptimal updates in certain directions of the parameter space and potentially slower convergence. In this work, we keep track of such covariance statistics in the form of a structured preconditioner matrix. Unlike other works, our approach does not apply direct approximations to estimate this matrix. We instead implement an invertible transformation that maps the preconditioner matrix into a new space where it becomes approximately diagonal. This enables a diagonal approximation of the preconditioner matrix in the transformed space, offering several computational advantages. Empirical results show that our approach can substantially enhance the convergence speed of modern adaptive optimizers. Notably, for large language models like LLaMA, we can achieve a speedup of 2x compared to the baseline Adam. Additionally, our method can be integrated with memory-efficient optimizers like Adafactor to manage computational overhead.
Generating Critical Scenarios for Testing Automated Driving Systems
Dec 03, 2024



Autonomous vehicles (AVs) have demonstrated significant potential in revolutionizing transportation, yet ensuring their safety and reliability remains a critical challenge, especially when exposed to dynamic and unpredictable environments. Real-world testing of an Autonomous Driving System (ADS) is both expensive and risky, making simulation-based testing a preferred approach. In this paper, we propose AVASTRA, a Reinforcement Learning (RL)-based approach to generate realistic critical scenarios for testing ADSs in simulation environments. To capture the complexity of driving scenarios, AVASTRA comprehensively represents the environment by both the internal states of an ADS under-test (e.g., the status of the ADS's core components, speed, or acceleration) and the external states of the surrounding factors in the simulation environment (e.g., weather, traffic flow, or road condition). AVASTRA trains the RL agent to effectively configure the simulation environment that places the AV in dangerous situations and potentially leads it to collisions. We introduce a diverse set of actions that allows the RL agent to systematically configure both environmental conditions and traffic participants. Additionally, based on established safety requirements, we enforce heuristic constraints to ensure the realism and relevance of the generated test scenarios. AVASTRA is evaluated on two popular simulation maps with four different road configurations. Our results show AVASTRA's ability to outperform the state-of-the-art approach by generating 30% to 115% more collision scenarios. Compared to the baseline based on Random Search, AVASTRA achieves up to 275% better performance. These results highlight the effectiveness of AVASTRA in enhancing the safety testing of AVs through realistic comprehensive critical scenario generation.
Mixed Effects Deep Learning for the interpretable analysis of single cell RNA sequencing data by quantifying and visualizing batch effects
Nov 13, 2024
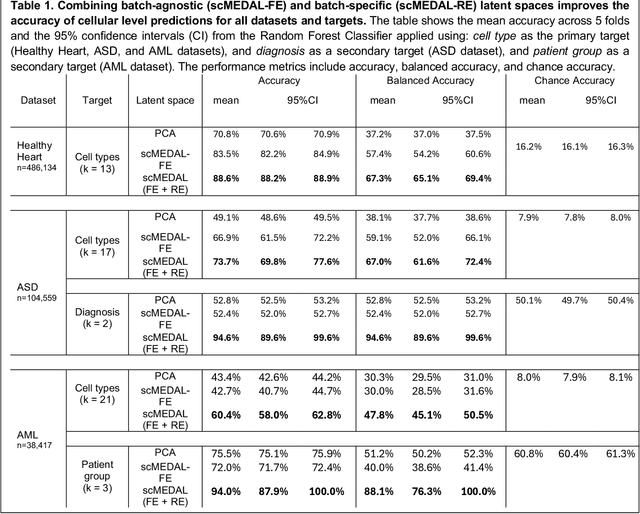


Single-cell RNA sequencing (scRNA-seq) data are often confounded by technical or biological batch effects. Existing deep learning models mitigate these effects but often discard batch-specific information, potentially losing valuable biological insights. We propose a Mixed Effects Deep Learning (MEDL) autoencoder framework that separately models batch-invariant (fixed effects) and batch-specific (random effects) components. By decoupling batch-invariant biological states from batch variations, our framework integrates both into predictive models. Our approach also generates 2D visualizations of how the same cell appears across batches, enhancing interpretability. Retaining both fixed and random effect latent spaces improves classification accuracy. We applied our framework to three datasets spanning the cardiovascular system (Healthy Heart), Autism Spectrum Disorder (ASD), and Acute Myeloid Leukemia (AML). With 147 batches in the Healthy Heart dataset, far exceeding typical numbers, we tested our framework's ability to handle many batches. In the ASD dataset, our approach captured donor heterogeneity between autistic and healthy individuals. In the AML dataset, it distinguished donor heterogeneity despite missing cell types and diseased donors exhibiting both healthy and malignant cells. These results highlight our framework's ability to characterize fixed and random effects, enhance batch effect visualization, and improve prediction accuracy across diverse datasets.
An Empirical Study on Capability of Large Language Models in Understanding Code Semantics
Jul 04, 2024Large Language Models for Code (code LLMs) have demonstrated remarkable performance across various software engineering (SE) tasks, increasing the application of code LLMs in software development. Despite the success of code LLMs, there remain significant concerns about the actual capabilities and reliability of these models, "whether these models really learn the semantics of code from the training data and leverage the learned knowledge to perform the SE tasks". In this paper, we introduce EMPICA, a comprehensive framework designed to systematically and empirically evaluate the capabilities of code LLMs in understanding code semantics. Specifically, EMPICA systematically introduces controlled modifications/transformations into the input code and examines the models' responses. Generally, code LLMs must be robust to semantically equivalent code inputs and be sensitive to non-equivalent ones for all SE tasks. Specifically, for every SE task, given an input code snippet c and its semantic equivalent variants, code LLMs must robustly produce consistent/equivalent outputs while they are expected to generate different outputs for c and its semantic non-equivalent variants. Our experimental results on three representative code understanding tasks, including code summarization, method name prediction, and output prediction, reveal that the robustness and sensitivity of the state-of-the-art code LLMs to code transformations vary significantly across tasks and transformation operators. In addition, the code LLMs exhibit better robustness to the semantic preserving transformations than their sensitivity to the semantic non-preserving transformations. These results highlight a need to enhance the model's capabilities of understanding code semantics, especially the sensitivity property.
Venomancer: Towards Imperceptible and Target-on-Demand Backdoor Attacks in Federated Learning
Jul 03, 2024



Federated Learning (FL) is a distributed machine learning approach that maintains data privacy by training on decentralized data sources. Similar to centralized machine learning, FL is also susceptible to backdoor attacks. Most backdoor attacks in FL assume a predefined target class and require control over a large number of clients or knowledge of benign clients' information. Furthermore, they are not imperceptible and are easily detected by human inspection due to clear artifacts left on the poison data. To overcome these challenges, we propose Venomancer, an effective backdoor attack that is imperceptible and allows target-on-demand. Specifically, imperceptibility is achieved by using a visual loss function to make the poison data visually indistinguishable from the original data. Target-on-demand property allows the attacker to choose arbitrary target classes via conditional adversarial training. Additionally, experiments showed that the method is robust against state-of-the-art defenses such as Norm Clipping, Weak DP, Krum, and Multi-Krum. The source code is available at https://anonymous.4open.science/r/Venomancer-3426.
H-Fac: Memory-Efficient Optimization with Factorized Hamiltonian Descent
Jun 17, 2024



In this study, we introduce a novel adaptive optimizer, H-Fac, which incorporates a factorized approach to momentum and scaling parameters. Our algorithm demonstrates competitive performances on both ResNets and Vision Transformers, while achieving sublinear memory costs through the use of rank-1 parameterizations for moment estimators. We develop our algorithms based on principles derived from Hamiltonian dynamics, providing robust theoretical underpinnings. These optimization algorithms are designed to be both straightforward and adaptable, facilitating easy implementation in diverse settings.
Instance Segmentation under Occlusions via Location-aware Copy-Paste Data Augmentation
Oct 27, 2023Occlusion is a long-standing problem in computer vision, particularly in instance segmentation. ACM MMSports 2023 DeepSportRadar has introduced a dataset that focuses on segmenting human subjects within a basketball context and a specialized evaluation metric for occlusion scenarios. Given the modest size of the dataset and the highly deformable nature of the objects to be segmented, this challenge demands the application of robust data augmentation techniques and wisely-chosen deep learning architectures. Our work (ranked 1st in the competition) first proposes a novel data augmentation technique, capable of generating more training samples with wider distribution. Then, we adopt a new architecture - Hybrid Task Cascade (HTC) framework with CBNetV2 as backbone and MaskIoU head to improve segmentation performance. Furthermore, we employ a Stochastic Weight Averaging (SWA) training strategy to improve the model's generalization. As a result, we achieve a remarkable occlusion score (OM) of 0.533 on the challenge dataset, securing the top-1 position on the leaderboard. Source code is available at this https://github.com/nguyendinhson-kaist/MMSports23-Seg-AutoID.