 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Effects Deep Learning for the interpretable analysis of single cell RNA sequencing data by quantifying and visualizing batch effects
Nov 13, 2024
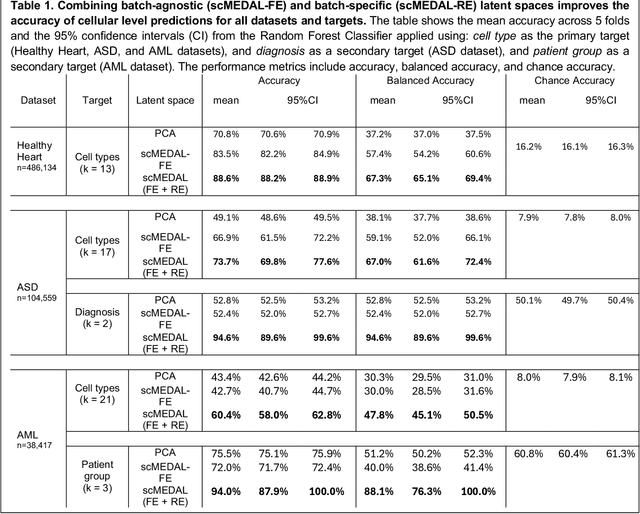


Single-cell RNA sequencing (scRNA-seq) data are often confounded by technical or biological batch effects. Existing deep learning models mitigate these effects but often discard batch-specific information, potentially losing valuable biological insights. We propose a Mixed Effects Deep Learning (MEDL) autoencoder framework that separately models batch-invariant (fixed effects) and batch-specific (random effects) components. By decoupling batch-invariant biological states from batch variations, our framework integrates both into predictive models. Our approach also generates 2D visualizations of how the same cell appears across batches, enhancing interpretability. Retaining both fixed and random effect latent spaces improves classification accuracy. We applied our framework to three datasets spanning the cardiovascular system (Healthy Heart), Autism Spectrum Disorder (ASD), and Acute Myeloid Leukemia (AML). With 147 batches in the Healthy Heart dataset, far exceeding typical numbers, we tested our framework's ability to handle many batches. In the ASD dataset, our approach captured donor heterogeneity between autistic and healthy individuals. In the AML dataset, it distinguished donor heterogeneity despite missing cell types and diseased donors exhibiting both healthy and malignant cells. These results highlight our framework's ability to characterize fixed and random effects, enhance batch effect visualization, and improve prediction accuracy across diverse datasets.
Fairness-enhancing mixed effects deep learning improves fairness on in- and out-of-distribution clustered (non-iid) data
Oct 04, 2023Traditional deep learning (DL) suffers from two core problems. Firstly, it assumes training samples are independent and identically distributed. However, numerous real-world datasets group samples by shared measurements (e.g., study participants or cells), violating this assumption. In these scenarios, DL can show compromised performance, limited generalization, and interpretability issues, coupled with cluster confounding causing Type 1 and 2 errors. Secondly, models are typically trained for overall accuracy, often neglecting underrepresented groups and introducing biases in crucial areas like loan approvals or determining health insurance rates, such biases can significantly impact one's quality of life. To address both of these challenges simultaneously, we present a mixed effects deep learning (MEDL) framework. MEDL separately quantifies cluster-invariant fixed effects (FE) and cluster-specific random effects (RE) through the introduction of: 1) a cluster adversary which encourages the learning of cluster-invariant FE, 2) a Bayesian neural network which quantifies the RE, and a mixing function combining the FE an RE into a mixed-effect prediction. We marry this MEDL with adversarial debiasing, which promotes equality-of-odds fairness across FE, RE, and ME predictions for fairness-sensitive variables. We evaluated our approach using three datasets: two from census/finance focusing on income classification and one from healthcare predicting hospitalization duration, a regression task. Our framework notably enhances fairness across all sensitive variables-increasing fairness up to 82% for age, 43% for race, 86% for sex, and 27% for marital-status. Besides promoting fairness, our method maintains the robust performance and clarity of MEDL. It's versatile, suitable for various dataset types and tasks, making it broadly applicable. Our GitHub repository houses the implementation.
UQ-ARMED: Uncertainty quantification of adversarially-regularized mixed effects deep learning for clustered non-iid data
Nov 29, 2022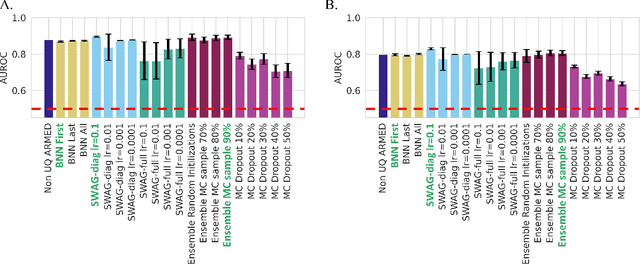
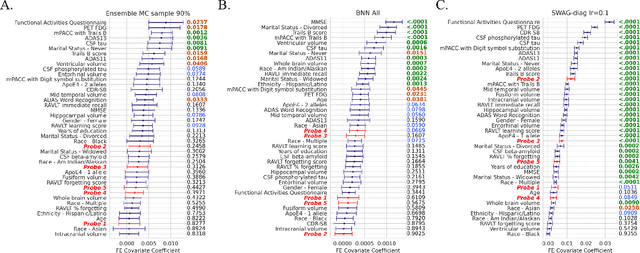
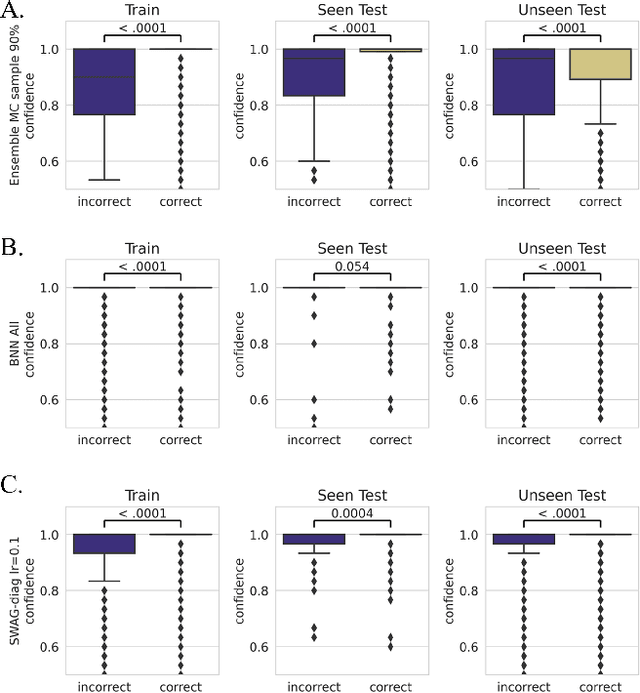
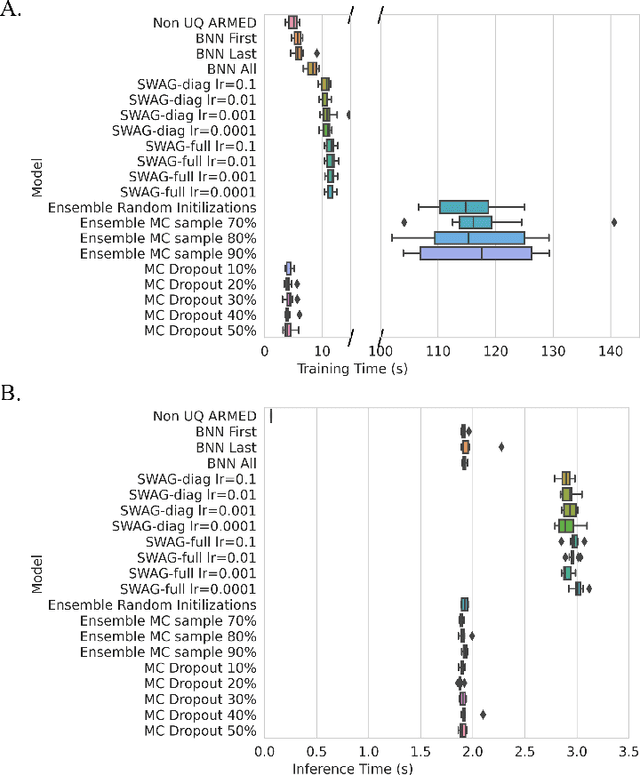
This work demonstrates the ability to produce readily interpretable statistical metrics for model fit, fixed effects covariance coefficients, and prediction confidence. Importantly, this work compares 4 suitable and commonly applied epistemic UQ approaches, BNN, SWAG, MC dropout, and ensemble approaches in their ability to calculate these statistical metrics for the ARMED MEDL models. In our experiment for AD prognosis, not only do the UQ methods provide these benefits, but several UQ methods maintain the high performance of the original ARMED method, some even provide a modest (but not statistically significant) performance improvement. The ensemble models, especially the ensemble method with a 90% subsampling, performed well across all metrics we tested with (1) high performance that was comparable to the non-UQ ARMED model, (2) properly deweights the confounds probes and assigns them statistically insignificant p-values, (3) attains relatively high calibration of the output prediction confidence. Based on the results, the ensemble approaches, especially with a subsampling of 90%, provided the best all-round performance for prediction and uncertainty estimation, and achieved our goals to provide statistical significance for model fit, statistical significance covariate coefficients, and confidence in prediction, while maintaining the baseline performance of MEDL using ARMED
Adversarially-regularized mixed effects deep learning (ARMED) models for improved interpretability, performance, and generalization on clustered data
Mar 28, 2022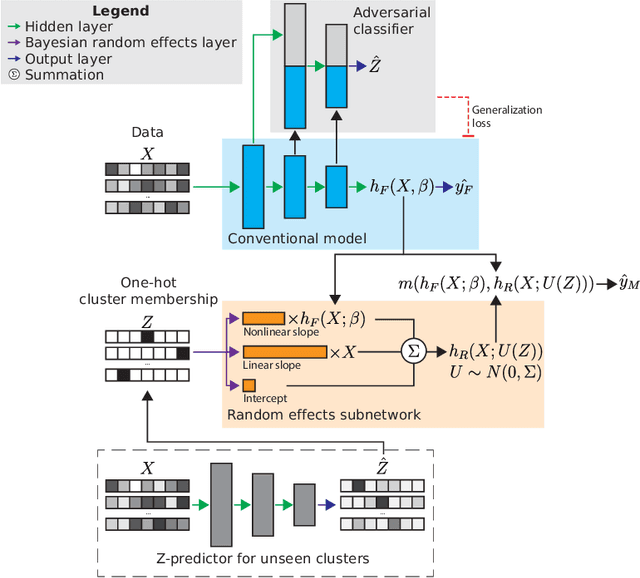
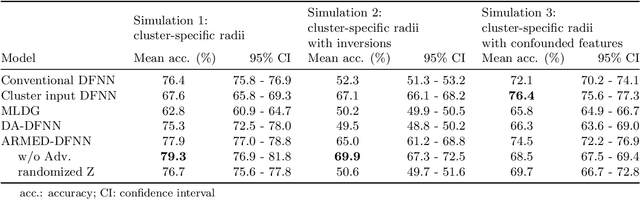
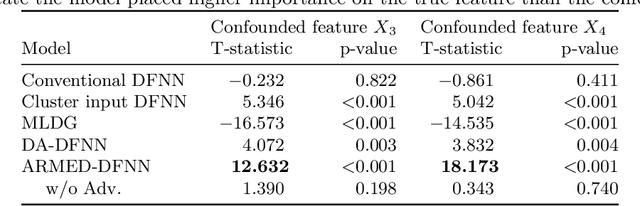
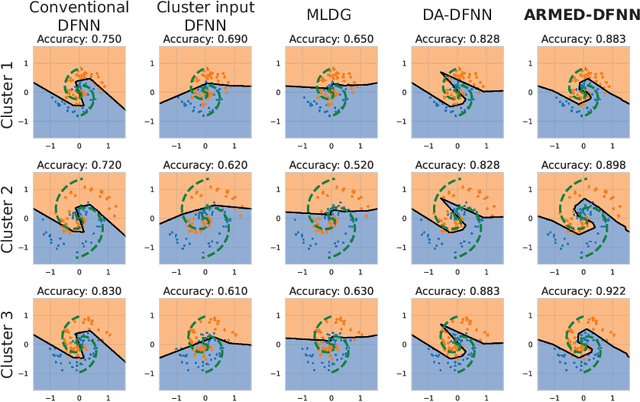
Data in the natural sciences frequently violate assumptions of independence. Such datasets have samples with inherent clustering (eg by study site, subject, experimental batch), leading to spurious associations, poor model fitting, and confounded analyses. While largely unaddressed in deep learning, this problem has been handled in the statistics community through mixed effects models. These models separate cluster-invariant, population-level fixed effects from cluster-specific random effects. We propose a general-purpose framework for Adversarially-Regularized Mixed Effects Deep learning (ARMED) models through three non-intrusive additions to existing neural networks: 1) a domain adversarial classifier constraining the original model to learn only cluster-invariant features, 2) a random effects subnetwork capturing cluster-specific features, and 3) an approach to apply random effects to clusters unseen during training. We apply ARMED to dense feedforward neural networks, convolutional neural networks, and autoencoders on 4 applications including classification of synthesized nonlinear data, dementia prognosis and diagnosis, and live-cell microscopy image analysis. We compare to conventional models, domain adversarial-only models, and the inclusion of cluster membership as an input covariate. ARMED models better distinguish confounded from true associations in synthetic data and emphasize more biologically plausible features in clinical applications. They also quantify inter-cluster variance in clinical data and can visualize batch effects in cell images. Finally, ARMED improves accuracy on data from clusters seen during training (up to 28% vs conventional models) and generalization to unseen clusters (up to 9% vs conventional models). By incorporating powerful mixed effects modeling into deep learning, ARMED increases interpretability, performance, and generalization on clustered data.
DC and SA: Robust and Efficient Hyperparameter Optimization of Multi-subnetwork Deep Learning Models
Feb 24, 2022
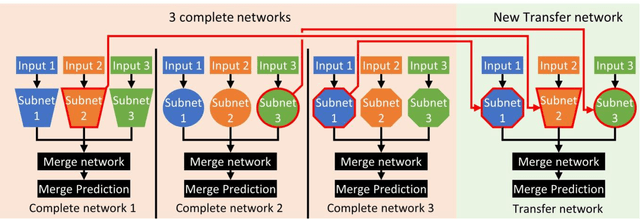

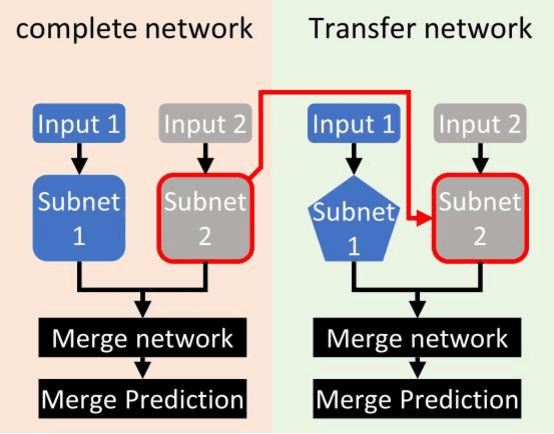
We present two novel hyperparameter optimization strategies for optimization of deep learning models with a modular architecture constructed of multiple subnetworks. As complex networks with multiple subnetworks become more frequently applied in machine learning, hyperparameter optimization methods are required to efficiently optimize their hyperparameters. Existing hyperparameter searches are general, and can be used to optimize such networks, however, by exploiting the multi-subnetwork architecture, these searches can be sped up substantially. The proposed methods offer faster convergence to a better-performing final model. To demonstrate this, we propose 2 independent approaches to enhance these prior algorithms: 1) a divide-and-conquer approach, in which the best subnetworks of top-performing models are combined, allowing for more rapid sampling of the hyperparameter search space. 2) A subnetwork adaptive approach that distributes computational resources based on the importance of each subnetwork, allowing more intelligent resource allocation. These approaches can be flexibily applied to many hyperparameter optimization algorithms. To illustrate this, we combine our approaches with the commonly-used Bayesian optimization method. Our approaches are then tested against both synthetic examples and real-world examples and applied to multiple network types including convolutional neural networks and dense feed forward neural networks. Our approaches show an increased optimization efficiency of up to 23.62x, and a final performance boost of up to 3.5% accuracy for classification and 4.4 MSE for regression, when compared to comparable BO approach.
Architectural configurations, atlas granularity and functional connectivity with diagnostic value in Autism Spectrum Disorder
Nov 25, 2019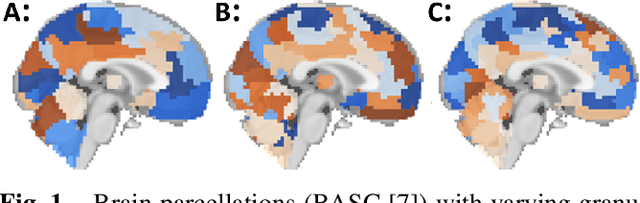
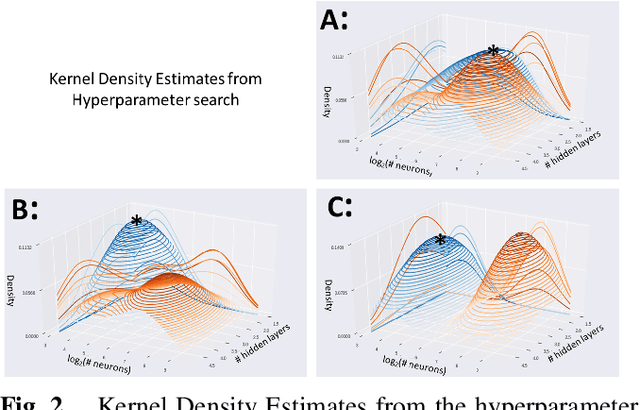


Currently, the diagnosis of Autism Spectrum Disorder (ASD) is dependent upon a subjective, time-consuming evaluation of behavioral tests by an expert clinician. Non-invasive functional MRI (fMRI) characterizes brain connectivity and may be used to inform diagnoses and democratize medicine. However, successful construction of deep learning models from fMRI requires addressing key choices about the model's architecture, including the number of layers and number of neurons per layer. Meanwhile, deriving functional connectivity (FC) features from fMRI requires choosing an atlas with an appropriate level of granularity. Once a model has been built, it is vital to determine which features are predictive of ASD and if similar features are learned across atlas granularity levels. To identify aptly suited architectural configurations, probability distributions of the configurations of high versus low performing models are compared. To determine the effect of atlas granularity, connectivity features are derived from atlases with 3 levels of granularity and important features are ranked with permutation feature importance. Results show the highest performing models use between 2-4 hidden layers and 16-64 neurons per layer, granularity dependent. Connectivity features identified as important across all 3 atlas granularity levels include FC to the supplementary motor gyrus and language association cortex, regions associated with deficits in social and sensory processing in ASD. Importantly, the cerebellum, often not included in functional analyses, is also identified as a region whose abnormal connectivity is highly predictive of ASD. Results of this study identify important regions to include in future studies of ASD, help assist in the selection of network architectures, and help identify appropriate levels of granularity to facilitate the development of accurate diagnostic models of ASD.
Prediction of individual progression rate in Parkinson's disease using clinical measures and biomechanical measures of gait and postural stability
Nov 22, 2019
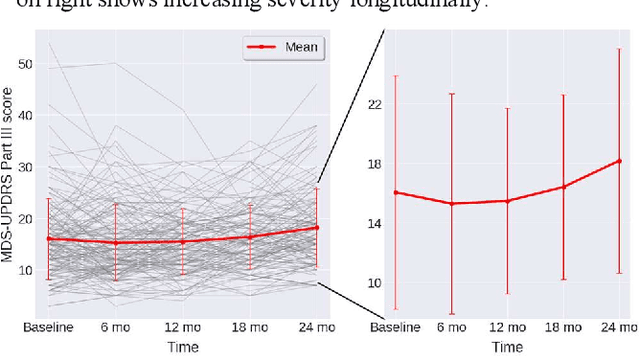


Parkinson's disease (PD) is a common neurological disorder characterized by gait impairment. PD has no cure, and an impediment to developing a treatment is the lack of any accepted method to predict disease progression rate. The primary aim of this study was to develop a model using clinical measures and biomechanical measures of gait and postural stability to predict an individual's PD progression over two years. Data from 160 PD subjects were utilized. Machine learning models, including XGBoost and Feed Forward Neural Networks, were developed using extensive model optimization and cross-validation. The highest performing model was a neural network that used a group of clinical measures, achieved a PPV of 71% in identifying fast progressors, and explained a large portion (37%) of the variance in an individual's progression rate on held-out test data. This demonstrates the potential to predict individual PD progression rate and enrich trials by analyzing clinical and biomechanical measures with machine learning.
Anatomically-Informed Data Augmentation for functional MRI with Applications to Deep Learning
Oct 17, 2019

The application of deep learning to build accurate predictive models from functional neuroimaging data is often hindered by limited dataset sizes. Though data augmentation can help mitigate such training obstacles, most data augmentation methods have been developed for natural images as in computer vision tasks such as CIFAR, not for medical images. This work helps to fills in this gap by proposing a method for generating new functional Magnetic Resonance Images (fMRI) with realistic brain morphology. This method is tested on a challenging task of predicting antidepressant treatment response from pre-treatment task-based fMRI and demonstrates a 26% improvement in performance in predicting response using augmented images. This improvement compares favorably to state-of-the-art augmentation methods for natural images. Through an ablative test, augmentation is also shown to substantively improve performance when applied before hyperparameter optimization. These results suggest the optimal order of operations and support the role of data augmentation method for improving predictive performance in tasks using fMRI.