 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Aware Contrastive Optimization for Imbalanced Text Classification
Oct 29, 2024The unique characteristics of text data make classification tasks a complex problem. Advances in unsupervised and semi-supervised learning and autoencoder architectures addressed several challenges. However, they still struggle with imbalanced text classification tasks, a common scenario in real-world applications, demonstrating a tendency to produce embeddings with unfavorable properties, such as class overlap. In this paper, we show that leveraging class-aware contrastive optimization combined with denoising autoencoders can successfully tackle imbalanced text classification tasks, achieving better performance than the current state-of-the-art. Concretely, our proposal combines reconstruction loss with contrastive class separation in the embedding space, allowing a better balance between the truthfulness of the generated embeddings and the model's ability to separate different classes. Compared with an extensive set of traditional and state-of-the-art competing methods, our proposal demonstrates a notable increase in performance across a wide variety of text datasets.
Venomancer: Towards Imperceptible and Target-on-Demand Backdoor Attacks in Federated Learning
Jul 03, 2024



Federated Learning (FL) is a distributed machine learning approach that maintains data privacy by training on decentralized data sources. Similar to centralized machine learning, FL is also susceptible to backdoor attacks. Most backdoor attacks in FL assume a predefined target class and require control over a large number of clients or knowledge of benign clients' information. Furthermore, they are not imperceptible and are easily detected by human inspection due to clear artifacts left on the poison data. To overcome these challenges, we propose Venomancer, an effective backdoor attack that is imperceptible and allows target-on-demand. Specifically, imperceptibility is achieved by using a visual loss function to make the poison data visually indistinguishable from the original data. Target-on-demand property allows the attacker to choose arbitrary target classes via conditional adversarial training. Additionally, experiments showed that the method is robust against state-of-the-art defenses such as Norm Clipping, Weak DP, Krum, and Multi-Krum. The source code is available at https://anonymous.4open.science/r/Venomancer-3426.
Cold-start Recommendation by Personalized Embedding Region Elicitation
Jun 03, 2024
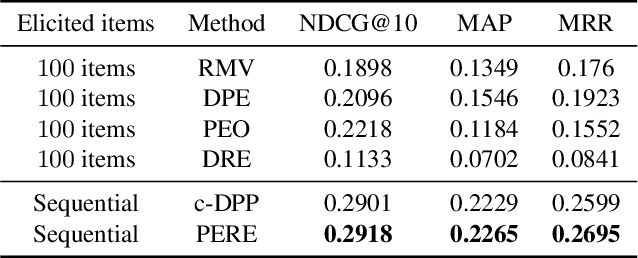
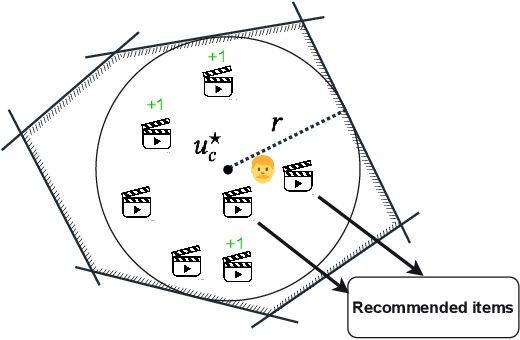
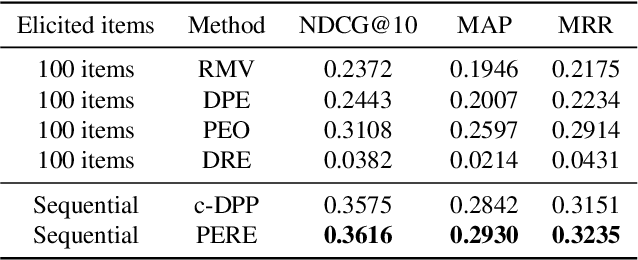
Rating elicitation is a success element for recommender systems to perform well at cold-starting, in which the systems need to recommend items to a newly arrived user with no prior knowledge about the user's preference. Existing elicitation methods employ a fixed set of items to learn the user's preference and then infer the users' preferences on the remaining items. Using a fixed seed set can limit the performance of the recommendation system since the seed set is unlikely optimal for all new users with potentially diverse preferences. This paper addresses this challenge using a 2-phase, personalized elicitation scheme. First, the elicitation scheme asks users to rate a small set of popular items in a ``burn-in'' phase. Second, it sequentially asks the user to rate adaptive items to refine the preference and the user's representation. Throughout the process, the system represents the user's embedding value not by a point estimate but by a region estimate. The value of information obtained by asking the user's rating on an item is quantified by the distance from the region center embedding space that contains with high confidence the true embedding value of the user. Finally, the recommendations are successively generated by considering the preference region of the user. We show that each subproblem in the elicitation scheme can be efficiently implemented. Further, we empirically demonstrate the effectiveness of the proposed method against existing rating-elicitation methods on several prominent datasets.
Backdoor Attacks and Defenses in Federated Learning: Survey, Challenges and Future Research Directions
Mar 03, 2023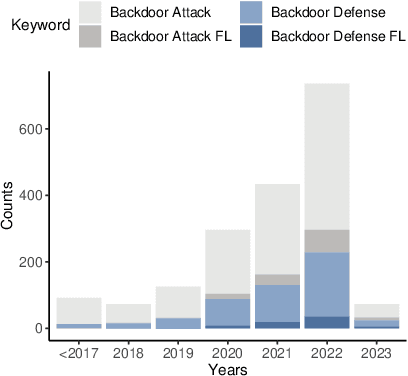
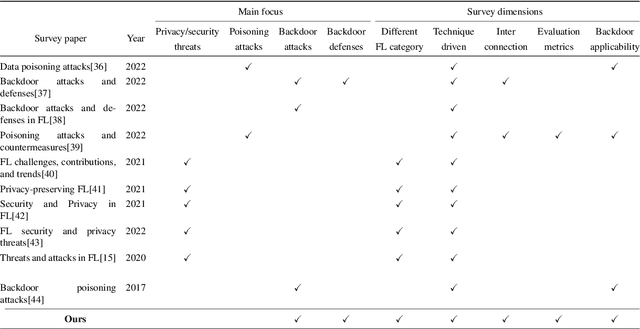
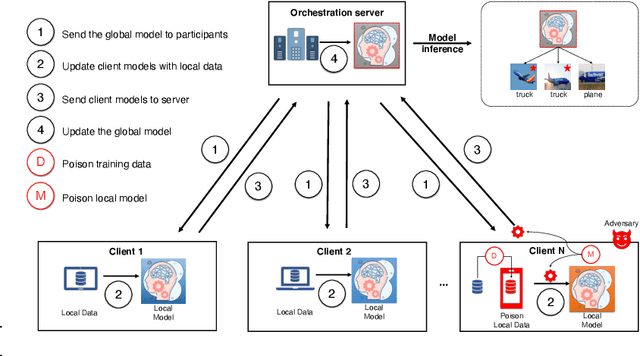
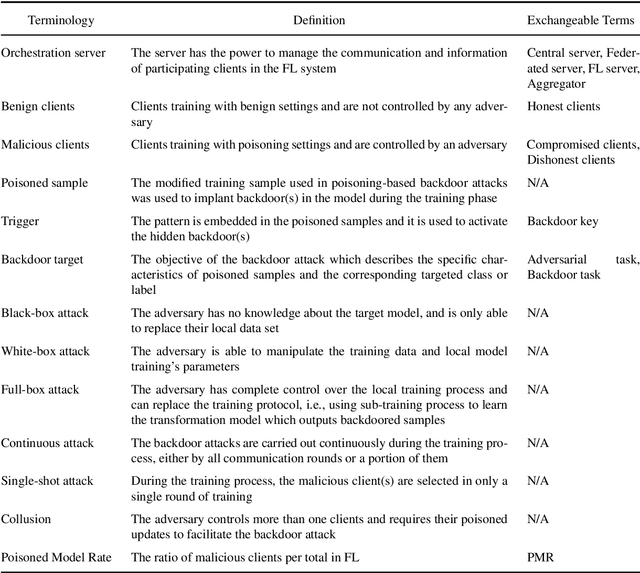
Federated learning (FL) is a machine learning (ML) approach that allows the use of distributed data without compromising personal privacy. However, the heterogeneous distribution of data among clients in FL can make it difficult for the orchestration server to validate the integrity of local model updates, making FL vulnerable to various threats, including backdoor attacks. Backdoor attacks involve the insertion of malicious functionality into a targeted model through poisoned updates from malicious clients. These attacks can cause the global model to misbehave on specific inputs while appearing normal in other cases. Backdoor attacks have received significant attention in the literature due to their potential to impact real-world deep learning applications. However, they have not been thoroughly studied in the context of FL. In this survey, we provide a comprehensive survey of current backdoor attack strategies and defenses in FL, including a comprehensive analysis of different approaches. We also discuss the challenges and potential future directions for attacks and defenses in the context of FL.
Asymmetric Hashing for Fast Ranking via Neural Network Measures
Nov 01, 2022Fast item ranking is an important task in recommender systems. In previous works, graph-based Approximate Nearest Neighbor (ANN) approaches have demonstrated good performance on item ranking tasks with generic searching/matching measures (including complex measures such as neural network measures). However, since these ANN approaches must go through the neural measures several times during ranking, the computation is not practical if the neural measure is a large network. On the other hand, fast item ranking using existing hashing-based approaches, such as Locality Sensitive Hashing (LSH), only works with a limited set of measures. Previous learning-to-hash approaches are also not suitable to solve the fast item ranking problem since they can take a significant amount of time and computation to train the hash functions. Hashing approaches, however, are attractive because they provide a principle and efficient way to retrieve candidate items. In this paper, we propose a simple and effective learning-to-hash approach for the fast item ranking problem that can be used for any type of measure, including neural network measures. Specifically, we solve this problem with an asymmetric hashing framework based on discrete inner product fitting. We learn a pair of related hash functions that map heterogeneous objects (e.g., users and items) into a common discrete space where the inner product of their binary codes reveals their true similarity defined via the original searching measure. The fast ranking problem is reduced to an ANN search via this asymmetric hashing scheme. Then, we propose a sampling strategy to efficiently select relevant and contrastive samples to train the hashing model. We empirically validate the proposed method against the existing state-of-the-art fast item ranking methods in several combinations of non-linear searching functions and prominent datasets.
Regression via Implicit Models and Optimal Transport Cost Minimization
Mar 03, 2020
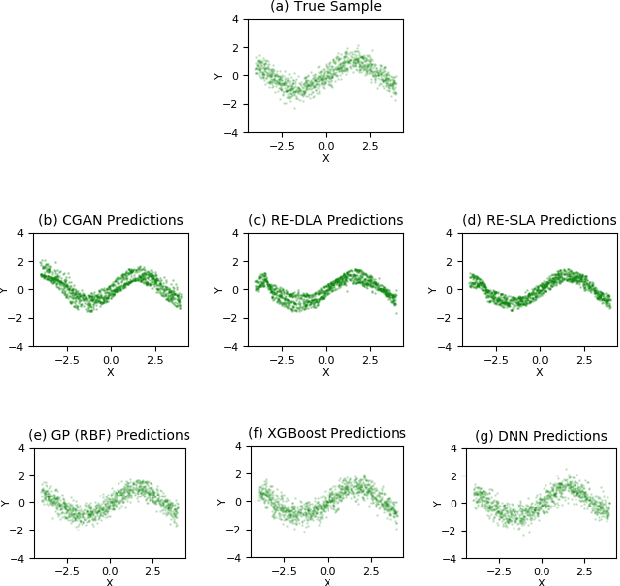
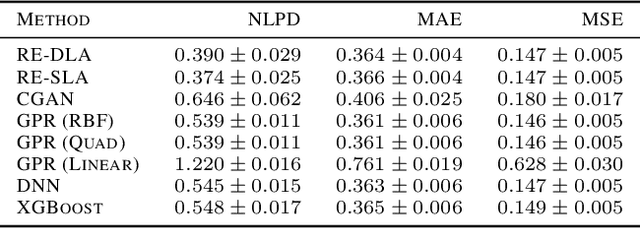
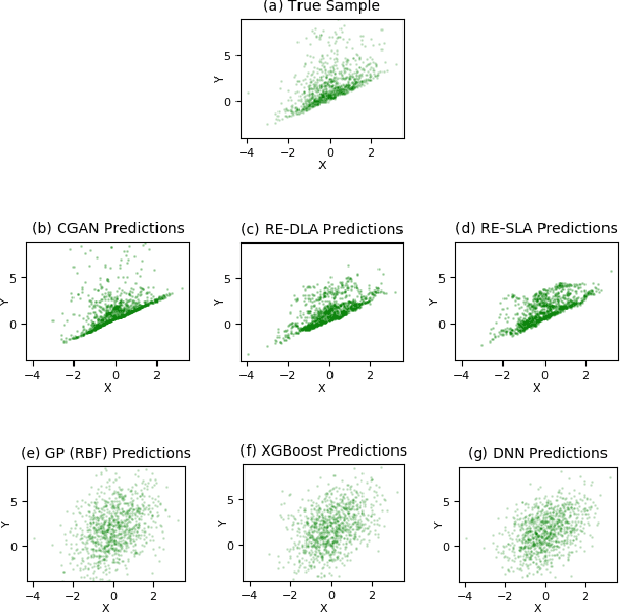
This paper addresses the classic problem of regression, which involves the inductive learning of a map, $y=f(x,z)$, $z$ denoting noise, $f:\mathbb{R}^n\times \mathbb{R}^k \rightarrow \mathbb{R}^m$. Recently, Conditional GAN (CGAN) has been applied for regression and has shown to be advantageous over the other standard approaches like Gaussian Process Regression, given its ability to implicitly model complex noise forms. However, the current CGAN implementation for regression uses the classical generator-discriminator architecture with the minimax optimization approach, which is notorious for being difficult to train due to issues like training instability or failure to converge. In this paper, we take another step towards regression models that implicitly model the noise, and propose a solution which directly optimizes the optimal transport cost between the true probability distribution $p(y|x)$ and the estimated distribution $\hat{p}(y|x)$ and does not suffer from the issues associated with the minimax approach. On a variety of synthetic and real-world datasets, our proposed solution achieves state-of-the-art results. The code accompanying this paper is available at "https://github.com/gurdaspuriya/ot_regression".
Targeted display advertising: the case of preferential attachment
Feb 07, 2020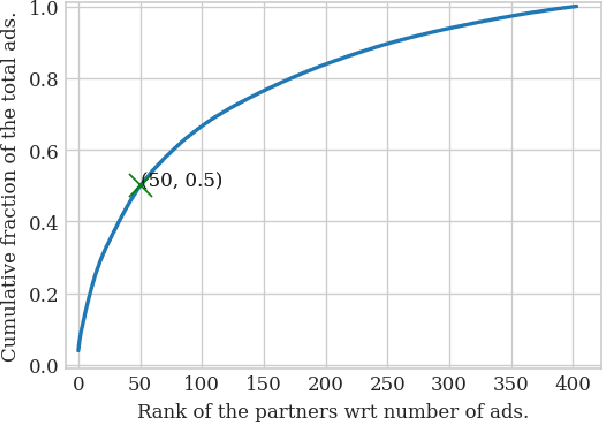
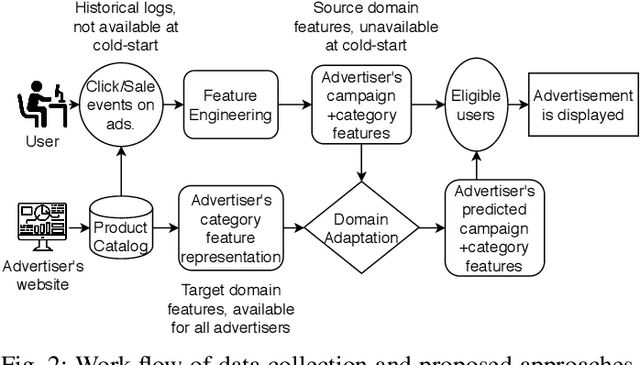
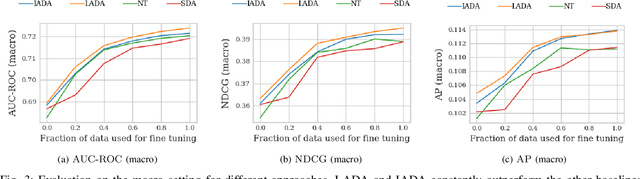
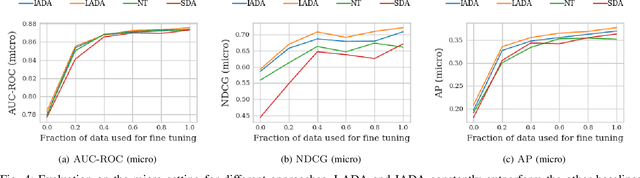
An average adult is exposed to hundreds of digital advertisements daily (https://www.mediadynamicsinc.com/uploads/files/PR092214-Note-only-150-Ads-2mk.pdf), making the digital advertisement industry a classic example of a big-data-driven platform. As such, the ad-tech industry relies on historical engagement logs (clicks or purchases) to identify potentially interested users for the advertisement campaign of a partner (a seller who wants to target users for its products). The number of advertisements that are shown for a partner, and hence the historical campaign data available for a partner depends upon the budget constraints of the partner. Thus, enough data can be collected for the high-budget partners to make accurate predictions, while this is not the case with the low-budget partners. This skewed distribution of the data leads to "preferential attachment" of the targeted display advertising platforms towards the high-budget partners. In this paper, we develop "domain-adaptation" approaches to address the challenge of predicting interested users for the partners with insufficient data, i.e., the tail partners. Specifically, we develop simple yet effective approaches that leverage the similarity among the partners to transfer information from the partners with sufficient data to cold-start partners, i.e., partners without any campaign data. Our approaches readily adapt to the new campaign data by incremental fine-tuning, and hence work at varying points of a campaign, and not just the cold-start. We present an experimental analysis on the historical logs of a major display advertising platform (https://www.criteo.com/). Specifically, we evaluate our approaches across 149 partners, at varying points of their campaigns. Experimental results show that the proposed approaches outperform the other "domain-adaptation" approaches at different time points of the campaigns.