 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUITAR: Gradient Pruning toward Fast Neural Ranking
Dec 28, 2023With the continuous popularity of deep learning and representation learning, fast vector search becomes a vital task in various ranking/retrieval based applications, say recommendation, ads ranking and question answering. Neural network based ranking is widely adopted due to its powerful capacity in modeling complex relationships, such as between users and items, questions and answers. However, it is usually exploited in offline or re-ranking manners for it is time-consuming in computations. Online neural network ranking--so called fast neural ranking--is considered challenging because neural network measures are usually non-convex and asymmetric. Traditional Approximate Nearest Neighbor (ANN) search which usually focuses on metric ranking measures, is not applicable to these advanced measures. In this paper, we introduce a novel graph searching framework to accelerate the searching in the fast neural ranking problem. The proposed graph searching algorithm is bi-level: we first construct a probable candidate set; then we only evaluate the neural network measure over the probable candidate set instead of evaluating the neural network over all neighbors. Specifically, we propose a gradient-based algorithm that approximates the rank of the neural network matching score to construct the probable candidate set; and we present an angle-based heuristic procedure to adaptively identify the proper size of the probable candidate set. Empirical results on public data confirm the effectiveness of our proposed algorithms.
Constrained Approximate Similarity Search on Proximity Graph
Nov 08, 2022Search engines and recommendation systems are built to efficiently display relevant information from those massive amounts of candidates. Typically a three-stage mechanism is employed in those systems: (i) a small collection of items are first retrieved by (e.g.,) approximate near neighbor search algorithms; (ii) then a collection of constraints are applied on the retrieved items; (iii) a fine-grained ranking neural network is employed to determine the final recommendation. We observe a major defect of the original three-stage pipeline: Although we only target to retrieve $k$ vectors in the final recommendation, we have to preset a sufficiently large $s$ ($s > k$) for each query, and ``hope'' the number of survived vectors after the filtering is not smaller than $k$. That is, at least $k$ vectors in the $s$ similar candidates satisfy the query constraints. In this paper, we investigate this constrained similarity search problem and attempt to merge the similarity search stage and the filtering stage into one single search operation. We introduce AIRSHIP, a system that integrates a user-defined function filtering into the similarity search framework. The proposed system does not need to build extra indices nor require prior knowledge of the query constraints. We propose three optimization strategies: (1) starting point selection, (2) multi-direction search, and (3) biased priority queue selection. Experimental evaluations on both synthetic and real data confirm the effectiveness of the proposed AIRSHIP algorithm. We focus on constrained graph-based approximate near neighbor (ANN) search in this study, in part because graph-based ANN is known to achieve excellent performance. We believe it is also possible to develop constrained hashing-based ANN or constrained quantization-based ANN.
Asymmetric Hashing for Fast Ranking via Neural Network Measures
Nov 01, 2022Fast item ranking is an important task in recommender systems. In previous works, graph-based Approximate Nearest Neighbor (ANN) approaches have demonstrated good performance on item ranking tasks with generic searching/matching measures (including complex measures such as neural network measures). However, since these ANN approaches must go through the neural measures several times during ranking, the computation is not practical if the neural measure is a large network. On the other hand, fast item ranking using existing hashing-based approaches, such as Locality Sensitive Hashing (LSH), only works with a limited set of measures. Previous learning-to-hash approaches are also not suitable to solve the fast item ranking problem since they can take a significant amount of time and computation to train the hash functions. Hashing approaches, however, are attractive because they provide a principle and efficient way to retrieve candidate items. In this paper, we propose a simple and effective learning-to-hash approach for the fast item ranking problem that can be used for any type of measure, including neural network measures. Specifically, we solve this problem with an asymmetric hashing framework based on discrete inner product fitting. We learn a pair of related hash functions that map heterogeneous objects (e.g., users and items) into a common discrete space where the inner product of their binary codes reveals their true similarity defined via the original searching measure. The fast ranking problem is reduced to an ANN search via this asymmetric hashing scheme. Then, we propose a sampling strategy to efficiently select relevant and contrastive samples to train the hashing model. We empirically validate the proposed method against the existing state-of-the-art fast item ranking methods in several combinations of non-linear searching functions and prominent datasets.
Proximity Graph Maintenance for Fast Online Nearest Neighbor Search
Jun 22, 2022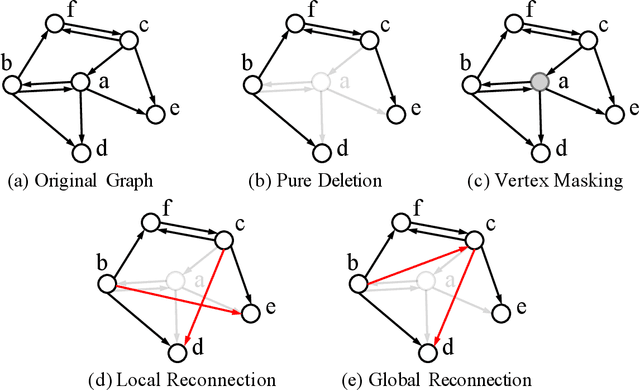
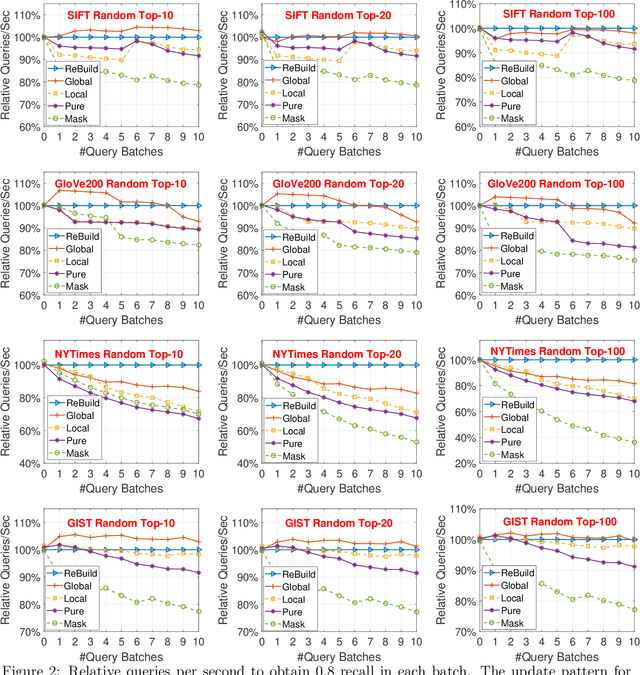
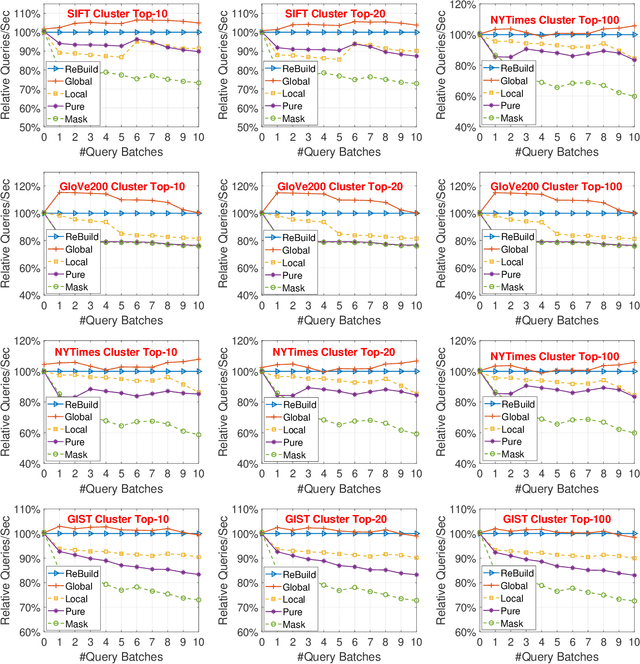
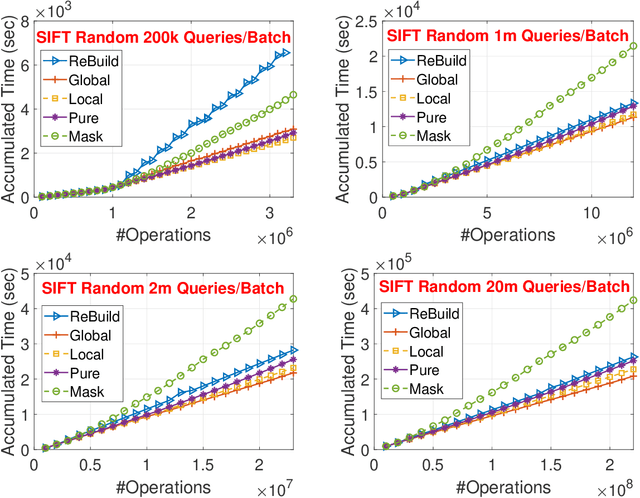
Approximate Nearest Neighbor (ANN) search is a fundamental technique for (e.g.,) the deployment of recommender systems. Recent studies bring proximity graph-based methods into practitioners' attention -- proximity graph-based methods outperform other solutions such as quantization, hashing, and tree-based ANN algorithm families. In current recommendation systems, data point insertions, deletions, and queries are streamed into the system in an online fashion as users and items change dynamically. As proximity graphs are constructed incrementally by inserting data points as new vertices into the graph, online insertions and queries are well-supported in proximity graph. However, a data point deletion incurs removing a vertex from the proximity graph index, while no proper graph index updating mechanisms are discussed in previous studies. To tackle the challenge, we propose an incremental proximity graph maintenance (IPGM) algorithm for online ANN. IPGM supports both vertex deletion and insertion on proximity graphs. Given a vertex deletion request, we thoroughly investigate solutions to update the connections of the vertex. The proposed updating scheme eliminates the performance drop in online ANN methods on proximity graphs, making the algorithm suitable for practical systems.