 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Conformal Prediction using Conditional Interquantile Intervals
Jan 06, 2026We introduce Conformal Interquantile Regression (CIR), a conformal regression method that efficiently constructs near-minimal prediction intervals with guaranteed coverage. CIR leverages black-box machine learning models to estimate outcome distributions through interquantile ranges, transforming these estimates into compact prediction intervals while achieving approximate conditional coverage. We further propose CIR+ (Conditional Interquantile Regression with More Comparison), which enhances CIR by incorporating a width-based selection rule for interquantile intervals. This refinement yields narrower prediction intervals while maintaining comparable coverage, though at the cost of slightly increased computational time. Both methods address key limitations of existing distributional conformal prediction approaches: they handle skewed distributions more effectively than Conformalized Quantile Regression, and they achieve substantially higher computational efficiency than Conformal Histogram Regression by eliminating the need for histogram construction. Extensive experiments on synthetic and real-world datasets demonstrate that our methods optimally balance predictive accuracy and computational efficiency compared to existing approaches.
Enhancing Adversarial Robustness with Conformal Prediction: A Framework for Guaranteed Model Reliability
Jun 09, 2025As deep learning models are increasingly deployed in high-risk applications, robust defenses against adversarial attacks and reliable performance guarantees become paramount. Moreover, accuracy alone does not provide sufficient assurance or reliable uncertainty estimates for these models. This study advances adversarial training by leveraging principles from Conformal Prediction. Specifically, we develop an adversarial attack method, termed OPSA (OPtimal Size Attack), designed to reduce the efficiency of conformal prediction at any significance level by maximizing model uncertainty without requiring coverage guarantees. Correspondingly, we introduce OPSA-AT (Adversarial Training), a defense strategy that integrates OPSA within a novel conformal training paradigm. Experimental evaluations demonstrate that our OPSA attack method induces greater uncertainty compared to baseline approaches for various defenses. Conversely, our OPSA-AT defensive model significantly enhances robustness not only against OPSA but also other adversarial attacks, and maintains reliable prediction. Our findings highlight the effectiveness of this integrated approach for developing trustworthy and resilient deep learning models for safety-critical domains. Our code is available at https://github.com/bjbbbb/Enhancing-Adversarial-Robustness-with-Conformal-Prediction.
Residual Reweighted Conformal Prediction for Graph Neural Networks
Jun 09, 2025Graph Neural Networks (GNNs) excel at modeling relational data but face significant challenges in high-stakes domains due to unquantified uncertainty. Conformal prediction (CP) offers statistical coverage guarantees, but existing methods often produce overly conservative prediction intervals that fail to account for graph heteroscedasticity and structural biases. While residual reweighting CP variants address some of these limitations, they neglect graph topology, cluster-specific uncertainties, and risk data leakage by reusing training sets. To address these issues, we propose Residual Reweighted GNN (RR-GNN), a framework designed to generate minimal prediction sets with provable marginal coverage guarantees. RR-GNN introduces three major innovations to enhance prediction performance. First, it employs Graph-Structured Mondrian CP to partition nodes or edges into communities based on topological features, ensuring cluster-conditional coverage that reflects heterogeneity. Second, it uses Residual-Adaptive Nonconformity Scores by training a secondary GNN on a held-out calibration set to estimate task-specific residuals, dynamically adjusting prediction intervals according to node or edge uncertainty. Third, it adopts a Cross-Training Protocol, which alternates the optimization of the primary GNN and the residual predictor to prevent information leakage while maintaining graph dependencies. We validate RR-GNN on 15 real-world graphs across diverse tasks, including node classification, regression, and edge weight prediction. Compared to CP baselines, RR-GNN achieves improved efficiency over state-of-the-art methods, with no loss of coverage.
Conditional Conformal Risk Adaptation
Apr 10, 2025


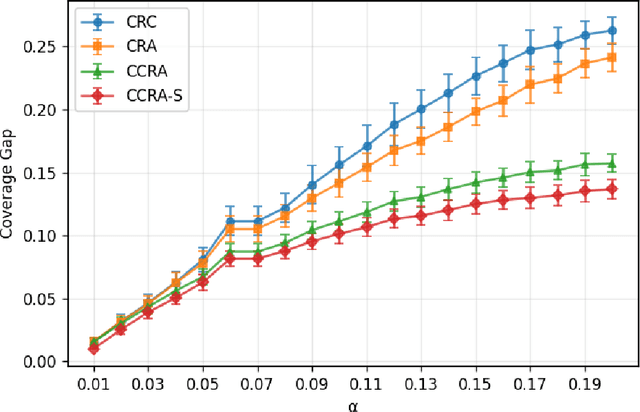
Uncertainty quantification is becoming increasingly important in image segmentation, especially for high-stakes applications like medical imaging. While conformal risk control generalizes conformal prediction beyond standard miscoverage to handle various loss functions such as false negative rate, its application to segmentation often yields inadequate conditional risk control: some images experience very high false negative rates while others have negligibly small ones. We develop Conformal Risk Adaptation (CRA), which introduces a new score function for creating adaptive prediction sets that significantly improve conditional risk control for segmentation tasks. We establish a novel theoretical framework that demonstrates a fundamental connection between conformal risk control and conformal prediction through a weighted quantile approach, applicable to any score function. To address the challenge of poorly calibrated probabilities in segmentation models, we introduce a specialized probability calibration framework that enhances the reliability of pixel-wise inclusion estimates. Using these calibrated probabilities, we propose Calibrated Conformal Risk Adaptation (CCRA) and a stratified variant (CCRA-S) that partitions images based on their characteristics and applies group-specific thresholds to further enhance conditional risk control. Our experiments on polyp segmentation demonstrate that all three methods (CRA, CCRA, and CCRA-S) provide valid marginal risk control and deliver more consistent conditional risk control across diverse images compared to standard approaches, offering a principled approach to uncertainty quantification that is particularly valuable for high-stakes and personalized segmentation applications.
Enhanced Route Planning with Calibrated Uncertainty Set
Mar 13, 2025This paper investigates the application of probabilistic prediction methodologies in route planning within a road network context. Specifically, we introduce the Conformalized Quantile Regression for Graph Autoencoders (CQR-GAE), which leverages the conformal prediction technique to offer a coverage guarantee, thus improving the reliability and robustness of our predictions. By incorporating uncertainty sets derived from CQR-GAE, we substantially improve the decision-making process in route planning under a robust optimization framework. We demonstrate the effectiveness of our approach by applying the CQR-GAE model to a real-world traffic scenario. The results indicate that our model significantly outperforms baseline methods, offering a promising avenue for advancing intelligent transportation systems.
Volume-Sorted Prediction Set: Efficient Conformal Prediction for Multi-Target Regression
Mar 04, 2025We introduce Volume-Sorted Prediction Set (VSPS), a novel method for uncertainty quantification in multi-target regression that uses conditional normalizing flows with conformal calibration. This approach constructs flexible, non-convex predictive regions with guaranteed coverage probabilities, overcoming limitations of traditional methods. By learning a transformation where the conditional distribution of responses follows a known form, VSPS identifies dense regions in the original space using the Jacobian determinant. This enables the creation of prediction regions that adapt to the true underlying distribution, focusing on areas of high probability density. Experimental results demonstrate that VSPS produces smaller, more informative prediction regions while maintaining robust coverage guarantees, enhancing uncertainty modeling in complex, high-dimensional settings.
Enhancing Trustworthiness of Graph Neural Networks with Rank-Based Conformal Training
Jan 06, 2025



Graph Neural Networks (GNNs) has been widely used in a variety of fields because of their great potential in representing graph-structured data. However, lacking of rigorous uncertainty estimations limits their application in high-stakes. Conformal Prediction (CP) can produce statistically guaranteed uncertainty estimates by using the classifier's probability estimates to obtain prediction sets, which contains the true class with a user-specified probability. In this paper, we propose a Rank-based CP during training framework to GNNs (RCP-GNN) for reliable uncertainty estimates to enhance the trustworthiness of GNNs in the node classification scenario. By exploiting rank information of the classifier's outcome, prediction sets with desired coverage rate can be efficiently constructed. The strategy of CP during training with differentiable rank-based conformity loss function is further explored to adapt prediction sets according to network topology information. In this way, the composition of prediction sets can be guided by the goal of jointly reducing inefficiency and probability estimation errors. Extensive experiments on several real-world datasets show that our model achieves any pre-defined target marginal coverage while significantly reducing the inefficiency compared with state-of-the-art methods.
Structure-Aware Stylized Image Synthesis for Robust Medical Image Segmentation
Dec 05, 2024



Accurate medical image segmentation is essential for effective diagnosis and treatment planning but is often challenged by domain shifts caused by variations in imaging devices, acquisition conditions, and patient-specific attributes. Traditional domain generalization methods typically require inclusion of parts of the test domain within the training set, which is not always feasible in clinical settings with limited diverse data. Additionally, although diffusion models have demonstrated strong capabilities in image generation and style transfer, they often fail to preserve the critical structural information necessary for precise medical analysis. To address these issues, we propose a novel medical image segmentation method that combines diffusion models and Structure-Preserving Network for structure-aware one-shot image stylization. Our approach effectively mitigates domain shifts by transforming images from various sources into a consistent style while maintaining the location, size, and shape of lesions. This ensures robust and accurate segmentation even when the target domain is absent from the training data. Experimental evaluations on colonoscopy polyp segmentation and skin lesion segmentation datasets show that our method enhances the robustness and accuracy of segmentation models, achieving superior performance metrics compared to baseline models without style transfer. This structure-aware stylization framework offers a practical solution for improving medical image segmentation across diverse domains, facilitating more reliable clinical diagnoses.
Game-Theoretic Defenses for Robust Conformal Prediction Against Adversarial Attacks in Medical Imaging
Nov 07, 2024

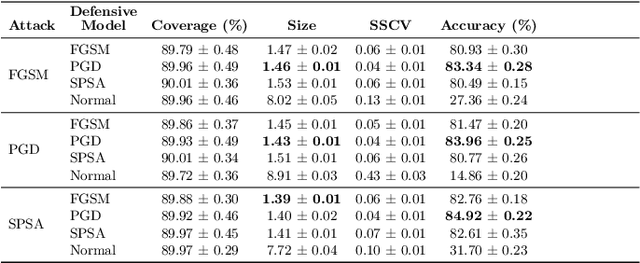

Adversarial attacks pose significant threats to the reliability and safety of deep learning models, especially in critical domains such as medical imaging. This paper introduces a novel framework that integrates conformal prediction with game-theoretic defensive strategies to enhance model robustness against both known and unknown adversarial perturbations. We address three primary research questions: constructing valid and efficient conformal prediction sets under known attacks (RQ1), ensuring coverage under unknown attacks through conservative thresholding (RQ2), and determining optimal defensive strategies within a zero-sum game framework (RQ3). Our methodology involves training specialized defensive models against specific attack types and employing maximum and minimum classifiers to aggregate defenses effectively. Extensive experiments conducted on the MedMNIST datasets, including PathMNIST, OrganAMNIST, and TissueMNIST, demonstrate that our approach maintains high coverage guarantees while minimizing prediction set sizes. The game-theoretic analysis reveals that the optimal defensive strategy often converges to a singular robust model, outperforming uniform and simple strategies across all evaluated datasets. This work advances the state-of-the-art in uncertainty quantification and adversarial robustness, providing a reliable mechanism for deploying deep learning models in adversarial environments.
Adaptive Conformal Inference by Particle Filtering under Hidden Markov Models
Nov 03, 2024Conformal inference is a statistical method used to construct prediction sets for point predictors, providing reliable uncertainty quantification with probability guarantees. This method utilizes historical labeled data to estimate the conformity or nonconformity between predictions and true labels. However, conducting conformal inference for hidden states under hidden Markov models (HMMs) presents a significant challenge, as the hidden state data is unavailable, resulting in the absence of a true label set to serve as a conformal calibration set. This paper proposes an adaptive conformal inference framework that leverages a particle filtering approach to address this issue. Rather than directly focusing on the unobservable hidden state, we innovatively use weighted particles as an approximation of the actual posterior distribution of the hidden state. Our goal is to produce prediction sets that encompass these particles to achieve a specific aggregate weight sum, referred to as the aggregated coverage level. The proposed framework can adapt online to the time-varying distribution of data and achieve the defined marginal aggregated coverage level in both one-step and multi-step inference over the long term. We verify the effectiveness of this approach through a real-time target localization simulation study.