 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Language Barriers: Equitable Performance in Multilingual Language Models
Aug 18, 2025Cutting-edge LLMs have emerged as powerful tools for multilingual communication and understanding. However, LLMs perform worse in Common Sense Reasoning (CSR) tasks when prompted in low-resource languages (LRLs) like Hindi or Swahili compared to high-resource languages (HRLs) like English. Equalizing this inconsistent access to quality LLM outputs is crucial to ensure fairness for speakers of LRLs and across diverse linguistic communities. In this paper, we propose an approach to bridge this gap in LLM performance. Our approach involves fine-tuning an LLM on synthetic code-switched text generated using controlled language-mixing methods. We empirically demonstrate that fine-tuning LLMs on synthetic code-switched datasets leads to substantial improvements in LRL model performance while preserving or enhancing performance in HRLs. Additionally, we present a new dataset of synthetic code-switched text derived from the CommonSenseQA dataset, featuring three distinct language ratio configurations.
Do Multimodal Large Language Models Understand Welding?
Mar 18, 2025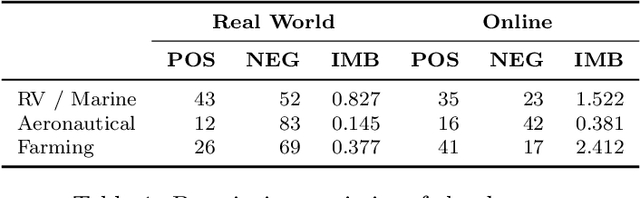
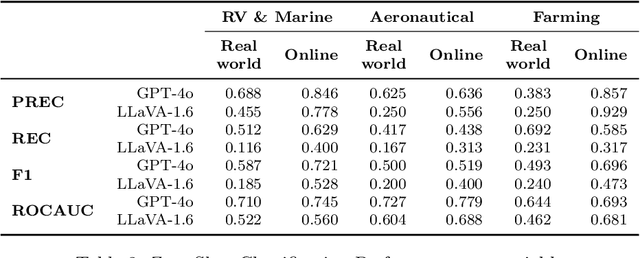
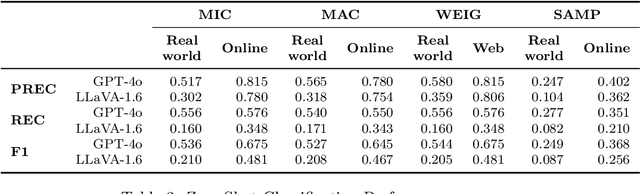
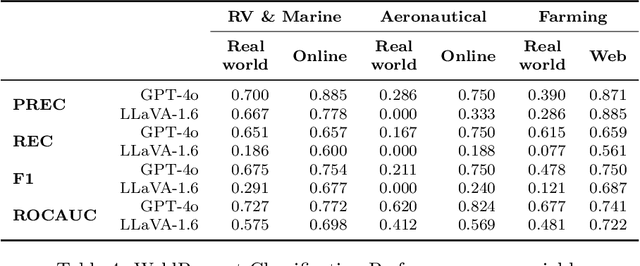
This paper examines the performance of Multimodal LLMs (MLLMs) in skilled production work, with a focus on welding. Using a novel data set of real-world and online weld images, annotated by a domain expert, we evaluate the performance of two state-of-the-art MLLMs in assessing weld acceptability across three contexts: RV \& Marine, Aeronautical, and Farming. While both models perform better on online images, likely due to prior exposure or memorization, they also perform relatively well on unseen, real-world weld images. Additionally, we introduce WeldPrompt, a prompting strategy that combines Chain-of-Thought generation with in-context learning to mitigate hallucinations and improve reasoning. WeldPrompt improves model recall in certain contexts but exhibits inconsistent performance across others. These results underscore the limitations and potentials of MLLMs in high-stakes technical domains and highlight the importance of fine-tuning, domain-specific data, and more sophisticated prompting strategies to improve model reliability. The study opens avenues for further research into multimodal learning in industry applications.
Class-Aware Contrastive Optimization for Imbalanced Text Classification
Oct 29, 2024The unique characteristics of text data make classification tasks a complex problem. Advances in unsupervised and semi-supervised learning and autoencoder architectures addressed several challenges. However, they still struggle with imbalanced text classification tasks, a common scenario in real-world applications, demonstrating a tendency to produce embeddings with unfavorable properties, such as class overlap. In this paper, we show that leveraging class-aware contrastive optimization combined with denoising autoencoders can successfully tackle imbalanced text classification tasks, achieving better performance than the current state-of-the-art. Concretely, our proposal combines reconstruction loss with contrastive class separation in the embedding space, allowing a better balance between the truthfulness of the generated embeddings and the model's ability to separate different classes. Compared with an extensive set of traditional and state-of-the-art competing methods, our proposal demonstrates a notable increase in performance across a wide variety of text datasets.