 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Multimodal Large Language Models Understand Welding?
Paper and Code
Mar 18, 2025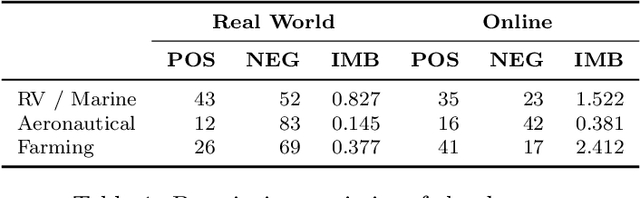
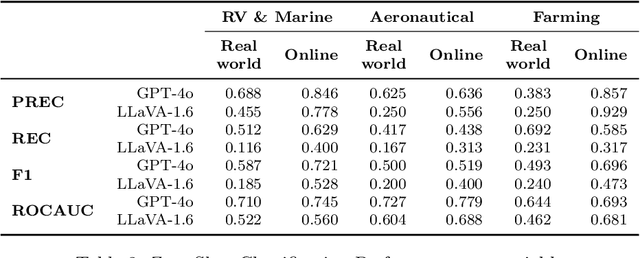
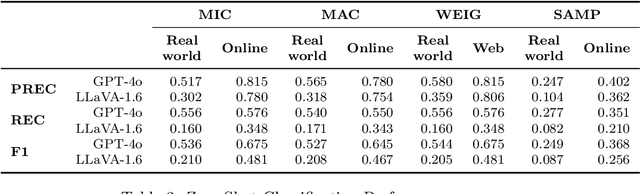
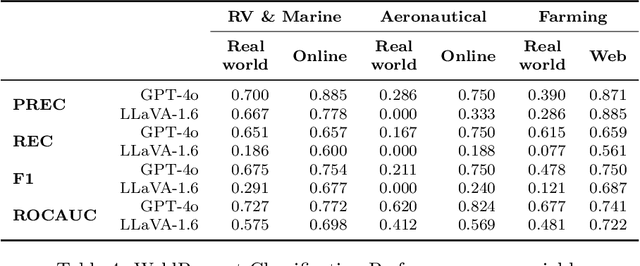
This paper examines the performance of Multimodal LLMs (MLLMs) in skilled production work, with a focus on welding. Using a novel data set of real-world and online weld images, annotated by a domain expert, we evaluate the performance of two state-of-the-art MLLMs in assessing weld acceptability across three contexts: RV \& Marine, Aeronautical, and Farming. While both models perform better on online images, likely due to prior exposure or memorization, they also perform relatively well on unseen, real-world weld images. Additionally, we introduce WeldPrompt, a prompting strategy that combines Chain-of-Thought generation with in-context learning to mitigate hallucinations and improve reasoning. WeldPrompt improves model recall in certain contexts but exhibits inconsistent performance across others. These results underscore the limitations and potentials of MLLMs in high-stakes technical domains and highlight the importance of fine-tuning, domain-specific data, and more sophisticated prompting strategies to improve model reliability. The study opens avenues for further research into multimodal learning in industry applications.