 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Sinkhorn Routing for Improved Sparse Mixture of Experts
Nov 12, 2025



Sparse Mixture-of-Experts (SMoE) has gained prominence as a scalable and computationally efficient architecture, enabling significant growth in model capacity without incurring additional inference costs. However, existing SMoE models often rely on auxiliary losses (e.g., z-loss, load balancing) and additional trainable parameters (e.g., noisy gating) to encourage expert diversity, leading to objective misalignment and increased model complexity. Moreover, existing Sinkhorn-based methods suffer from significant training overhead due to their heavy reliance on the computationally expensive Sinkhorn algorithm. In this work, we formulate token-to-expert assignment as an optimal transport problem, incorporating constraints to ensure balanced expert utilization. We demonstrate that introducing a minimal degree of optimal transport-based routing enhances SMoE performance without requiring auxiliary balancing losses. Unlike previous methods, our approach derives gating scores directly from the transport map, enabling more effective token-to-expert balancing, supported by both theoretical analysis and empirical results. Building on these insights, we propose Selective Sinkhorn Routing (SSR), a routing mechanism that replaces auxiliary loss with lightweight Sinkhorn-based routing. SSR promotes balanced token assignments while preserving flexibility in expert selection. Across both language modeling and image classification tasks, SSR achieves faster training, higher accuracy, and greater robustness to input corruption.
Angular Steering: Behavior Control via Rotation in Activation Space
Oct 30, 2025Controlling specific behaviors in large language models while preserving their general capabilities is a central challenge for safe and reliable artificial intelligence deployment. Current steering methods, such as vector addition and directional ablation, are constrained within a two-dimensional subspace defined by the activation and feature direction, making them sensitive to chosen parameters and potentially affecting unrelated features due to unintended interactions in activation space. We introduce Angular Steering, a novel and flexible method for behavior modulation that operates by rotating activations within a fixed two-dimensional subspace. By formulating steering as a geometric rotation toward or away from a target behavior direction, Angular Steering provides continuous, fine-grained control over behaviors such as refusal and compliance. We demonstrate this method using refusal steering emotion steering as use cases. Additionally, we propose Adaptive Angular Steering, a selective variant that rotates only activations aligned with the target feature, further enhancing stability and coherence. Angular Steering generalizes existing addition and orthogonalization techniques under a unified geometric rotation framework, simplifying parameter selection and maintaining model stability across a broader range of adjustments. Experiments across multiple model families and sizes show that Angular Steering achieves robust behavioral control while maintaining general language modeling performance, underscoring its flexibility, generalization, and robustness compared to prior approaches. Code and artifacts are available at https://github.com/lone17/angular-steering/.
Activation Steering with a Feedback Controller
Oct 05, 2025



Controlling the behaviors of large language models (LLM) is fundamental to their safety alignment and reliable deployment. However, existing steering methods are primarily driven by empirical insights and lack theoretical performance guarantees. In this work, we develop a control-theoretic foundation for activation steering by showing that popular steering methods correspond to the proportional (P) controllers, with the steering vector serving as the feedback signal. Building on this finding, we propose Proportional-Integral-Derivative (PID) Steering, a principled framework that leverages the full PID controller for activation steering in LLMs. The proportional (P) term aligns activations with target semantic directions, the integral (I) term accumulates errors to enforce persistent corrections across layers, and the derivative (D) term mitigates overshoot by counteracting rapid activation changes. This closed-loop design yields interpretable error dynamics and connects activation steering to classical stability guarantees in control theory. Moreover, PID Steering is lightweight, modular, and readily integrates with state-of-the-art steering methods. Extensive experiments across multiple LLM families and benchmarks demonstrate that PID Steering consistently outperforms existing approaches, achieving more robust and reliable behavioral control.
The Blessing and Curse of Dimensionality in Safety Alignment
Jul 27, 2025The focus on safety alignment in large language models (LLMs) has increased significantly due to their widespread adoption across different domains. The scale of LLMs play a contributing role in their success, and the growth in parameter count follows larger hidden dimensions. In this paper, we hypothesize that while the increase in dimensions has been a key advantage, it may lead to emergent problems as well. These problems emerge as the linear structures in the activation space can be exploited, in the form of activation engineering, to circumvent its safety alignment. Through detailed visualizations of linear subspaces associated with different concepts, such as safety, across various model scales, we show that the curse of high-dimensional representations uniquely impacts LLMs. Further substantiating our claim, we demonstrate that projecting the representations of the model onto a lower dimensional subspace can preserve sufficient information for alignment while avoiding those linear structures. Empirical results confirm that such dimensional reduction significantly reduces susceptibility to jailbreaking through representation engineering. Building on our empirical validations, we provide theoretical insights into these linear jailbreaking methods relative to a model's hidden dimensions. Broadly speaking, our work posits that the high dimensions of a model's internal representations can be both a blessing and a curse in safety alignment.
Revisiting Transformers with Insights from Image Filtering
Jun 12, 2025The self-attention mechanism, a cornerstone of Transformer-based state-of-the-art deep learning architectures, is largely heuristic-driven and fundamentally challenging to interpret. Establishing a robust theoretical foundation to explain its remarkable success and limitations has therefore become an increasingly prominent focus in recent research. Some notable directions have explored understanding self-attention through the lens of image denoising and nonparametric regression. While promising, existing frameworks still lack a deeper mechanistic interpretation of various architectural components that enhance self-attention, both in its original formulation and subsequent variants. In this work, we aim to advance this understanding by developing a unifying image processing framework, capable of explaining not only the self-attention computation itself but also the role of components such as positional encoding and residual connections, including numerous later variants. We also pinpoint potential distinctions between the two concepts building upon our framework, and make effort to close this gap. We introduce two independent architectural modifications within transformers. While our primary objective is interpretability, we empirically observe that image processing-inspired modifications can also lead to notably improved accuracy and robustness against data contamination and adversaries across language and vision tasks as well as better long sequence understanding.
Tree-Sliced Wasserstein Distance with Nonlinear Projection
May 02, 2025Tree-Sliced methods have recently emerged as an alternative to the traditional Sliced Wasserstein (SW) distance, replacing one-dimensional lines with tree-based metric spaces and incorporating a splitting mechanism for projecting measures. This approach enhances the ability to capture the topological structures of integration domains in Sliced Optimal Transport while maintaining low computational costs. Building on this foundation, we propose a novel nonlinear projectional framework for the Tree-Sliced Wasserstein (TSW) distance, substituting the linear projections in earlier versions with general projections, while ensuring the injectivity of the associated Radon Transform and preserving the well-definedness of the resulting metric. By designing appropriate projections, we construct efficient metrics for measures on both Euclidean spaces and spheres. Finally, we validate our proposed metric through extensive numerical experiments for Euclidean and spherical datasets. Applications include gradient flows, self-supervised learning, and generative models, where our methods demonstrate significant improvements over recent SW and TSW variants.
MoLEx: Mixture of Layer Experts for Finetuning with Sparse Upcycling
Mar 14, 2025Large-scale pre-training of deep models, followed by fine-tuning them, has become the cornerstone of natural language processing (NLP). The prevalence of data coupled with computational resources has led to large models with a considerable number of parameters. While the massive size of these models has led to remarkable success in many NLP tasks, a detriment is the expense required to retrain all the base model's parameters for the adaptation to each task or domain. Parameter Efficient Fine-Tuning (PEFT) provides an effective solution for this challenge by minimizing the number of parameters required to be fine-tuned while maintaining the quality of the model. While existing methods have achieved impressive results, they mainly focus on adapting a subset of parameters, weight reparameterization, and prompt engineering. In this paper, we study layers as extractors of different types of linguistic information that are valuable when used in conjunction. We then propose the Mixture of Layer Experts (MoLEx), a novel sparse mixture of experts (SMoE) whose experts are layers in the pre-trained model. It performs a conditional computation of a mixture of layers during fine-tuning to provide the model with more structural knowledge about the data. By providing an avenue for information exchange between layers, MoLEx enables the model to make a more well-informed prediction for the downstream task, leading to better fine-tuning results with the same number of effective parameters. As experts can be processed in parallel, MoLEx introduces minimal additional computational overhead. We empirically corroborate the advantages of MoLEx when combined with popular PEFT baseline methods on a variety of downstream fine-tuning tasks, including the popular GLUE benchmark as well as the End-to-End Challenge (E2E). The code is publicly available at https://github.com/rachtsy/molex.
Distance-Based Tree-Sliced Wasserstein Distance
Mar 14, 2025To overcome computational challenges of Optimal Transport (OT), several variants of Sliced Wasserstein (SW) has been developed in the literature. These approaches exploit the closed-form expression of the univariate OT by projecting measures onto (one-dimensional) lines. However, projecting measures onto low-dimensional spaces can lead to a loss of topological information. Tree-Sliced Wasserstein distance on Systems of Lines (TSW-SL) has emerged as a promising alternative that replaces these lines with a more advanced structure called tree systems. The tree structures enhance the ability to capture topological information of the metric while preserving computational efficiency. However, at the core of TSW-SL, the splitting maps, which serve as the mechanism for pushing forward measures onto tree systems, focus solely on the position of the measure supports while disregarding the projecting domains. Moreover, the specific splitting map used in TSW-SL leads to a metric that is not invariant under Euclidean transformations, a typically expected property for OT on Euclidean space. In this work, we propose a novel class of splitting maps that generalizes the existing one studied in TSW-SL enabling the use of all positional information from input measures, resulting in a novel Distance-based Tree-Sliced Wasserstein (Db-TSW) distance. In addition, we introduce a simple tree sampling process better suited for Db-TSW, leading to an efficient GPU-friendly implementation for tree systems, similar to the original SW. We also provide a comprehensive theoretical analysis of proposed class of splitting maps to verify the injectivity of the corresponding Radon Transform, and demonstrate that Db-TSW is an Euclidean invariant metric. We empirically show that Db-TSW significantly improves accuracy compared to recent SW variants while maintaining low computational cost via a wide range of experiments.
Spherical Tree-Sliced Wasserstein Distance
Mar 14, 2025



Sliced Optimal Transport (OT) simplifies the OT problem in high-dimensional spaces by projecting supports of input measures onto one-dimensional lines and then exploiting the closed-form expression of the univariate OT to reduce the computational burden of OT. Recently, the Tree-Sliced method has been introduced to replace these lines with more intricate structures, known as tree systems. This approach enhances the ability to capture topological information of integration domains in Sliced OT while maintaining low computational cost. Inspired by this approach, in this paper, we present an adaptation of tree systems on OT problems for measures supported on a sphere. As a counterpart to the Radon transform variant on tree systems, we propose a novel spherical Radon transform with a new integration domain called spherical trees. By leveraging this transform and exploiting the spherical tree structures, we derive closed-form expressions for OT problems on the sphere. Consequently, we obtain an efficient metric for measures on the sphere, named Spherical Tree-Sliced Wasserstein (STSW) distance. We provide an extensive theoretical analysis to demonstrate the topology of spherical trees and the well-definedness and injectivity of our Radon transform variant, which leads to an orthogonally invariant distance between spherical measures. Finally, we conduct a wide range of numerical experiments, including gradient flows and self-supervised learning, to assess the performance of our proposed metric, comparing it to recent benchmarks.
CAMEx: Curvature-aware Merging of Experts
Feb 26, 2025

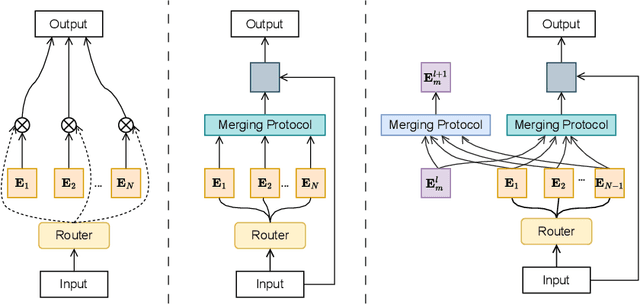

Existing methods for merging experts during model training and fine-tuning predominantly rely on Euclidean geometry, which assumes a flat parameter space. This assumption can limit the model's generalization ability, especially during the pre-training phase, where the parameter manifold might exhibit more complex curvature. Curvature-aware merging methods typically require additional information and computational resources to approximate the Fisher Information Matrix, adding memory overhead. In this paper, we introduce CAMEx (\textbf{C}urvature-\textbf{A}ware \textbf{M}erging of \textbf{Ex}perts), a novel expert merging protocol that incorporates natural gradients to account for the non-Euclidean curvature of the parameter manifold. By leveraging natural gradients, CAMEx adapts more effectively to the structure of the parameter space, improving alignment between model updates and the manifold's geometry. This approach enhances both pre-training and fine-tuning, resulting in better optimization trajectories and improved generalization without the substantial memory overhead typically associated with curvature-aware methods. Our contributions are threefold: (1) CAMEx significantly outperforms traditional Euclidean-based expert merging techniques across various natural language processing tasks, leading to enhanced performance during pre-training and fine-tuning; (2) we introduce a dynamic merging architecture that optimizes resource utilization, achieving high performance while reducing computational costs, facilitating efficient scaling of large language models; and (3) we provide both theoretical and empirical evidence to demonstrate the efficiency of our proposed method.