 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Blessing and Curse of Dimensionality in Safety Alignment
Jul 27, 2025The focus on safety alignment in large language models (LLMs) has increased significantly due to their widespread adoption across different domains. The scale of LLMs play a contributing role in their success, and the growth in parameter count follows larger hidden dimensions. In this paper, we hypothesize that while the increase in dimensions has been a key advantage, it may lead to emergent problems as well. These problems emerge as the linear structures in the activation space can be exploited, in the form of activation engineering, to circumvent its safety alignment. Through detailed visualizations of linear subspaces associated with different concepts, such as safety, across various model scales, we show that the curse of high-dimensional representations uniquely impacts LLMs. Further substantiating our claim, we demonstrate that projecting the representations of the model onto a lower dimensional subspace can preserve sufficient information for alignment while avoiding those linear structures. Empirical results confirm that such dimensional reduction significantly reduces susceptibility to jailbreaking through representation engineering. Building on our empirical validations, we provide theoretical insights into these linear jailbreaking methods relative to a model's hidden dimensions. Broadly speaking, our work posits that the high dimensions of a model's internal representations can be both a blessing and a curse in safety alignment.
Revisiting Transformers with Insights from Image Filtering
Jun 12, 2025The self-attention mechanism, a cornerstone of Transformer-based state-of-the-art deep learning architectures, is largely heuristic-driven and fundamentally challenging to interpret. Establishing a robust theoretical foundation to explain its remarkable success and limitations has therefore become an increasingly prominent focus in recent research. Some notable directions have explored understanding self-attention through the lens of image denoising and nonparametric regression. While promising, existing frameworks still lack a deeper mechanistic interpretation of various architectural components that enhance self-attention, both in its original formulation and subsequent variants. In this work, we aim to advance this understanding by developing a unifying image processing framework, capable of explaining not only the self-attention computation itself but also the role of components such as positional encoding and residual connections, including numerous later variants. We also pinpoint potential distinctions between the two concepts building upon our framework, and make effort to close this gap. We introduce two independent architectural modifications within transformers. While our primary objective is interpretability, we empirically observe that image processing-inspired modifications can also lead to notably improved accuracy and robustness against data contamination and adversaries across language and vision tasks as well as better long sequence understanding.
Tight Clusters Make Specialized Experts
Feb 21, 2025

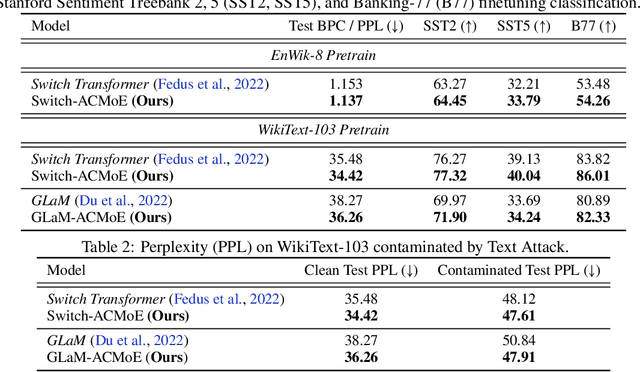
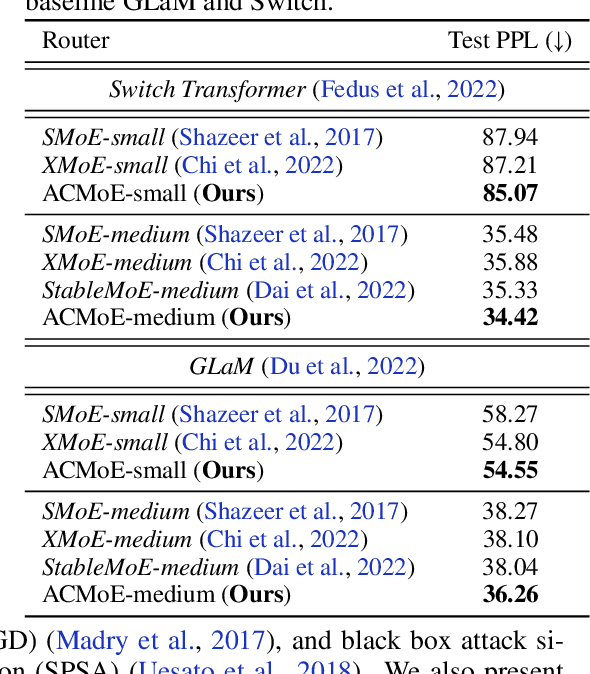
Sparse Mixture-of-Experts (MoE) architectures have emerged as a promising approach to decoupling model capacity from computational cost. At the core of the MoE model is the router, which learns the underlying clustering structure of the input distribution in order to send input tokens to appropriate experts. However, latent clusters may be unidentifiable in high dimension, which causes slow convergence, susceptibility to data contamination, and overall degraded representations as the router is unable to perform appropriate token-expert matching. We examine the router through the lens of clustering optimization and derive optimal feature weights that maximally identify the latent clusters. We use these weights to compute the token-expert routing assignments in an adaptively transformed space that promotes well-separated clusters, which helps identify the best-matched expert for each token. In particular, for each expert cluster, we compute a set of weights that scales features according to whether that expert clusters tightly along that feature. We term this novel router the Adaptive Clustering (AC) router. Our AC router enables the MoE model to obtain three connected benefits: 1) faster convergence, 2) better robustness to data corruption, and 3) overall performance improvement, as experts are specialized in semantically distinct regions of the input space. We empirically demonstrate the advantages of our AC router over baseline routing methods when applied on a variety of MoE backbones for language modeling and image recognition tasks in both clean and corrupted settings.
Elliptical Attention
Jun 19, 2024Pairwise dot-product self-attention is key to the success of transformers that achieve state-of-the-art performance across a variety of applications in language and vision. This dot-product self-attention computes attention weights among the input tokens using Euclidean distance, which makes the model prone to representation collapse and vulnerable to contaminated samples. In this paper, we propose using a Mahalanobis distance metric for computing the attention weights to stretch the underlying feature space in directions of high contextual relevance. In particular, we define a hyper-ellipsoidal neighborhood around each query to increase the attention weights of the tokens lying in the contextually important directions. We term this novel class of attention Elliptical Attention. Our Elliptical Attention provides two benefits: 1) reducing representation collapse and 2) enhancing the model's robustness as the Elliptical Attention pays more attention to contextually relevant information rather than focusing on some small subset of informative features. We empirically demonstrate the advantages of Elliptical Attention over the baseline dot-product attention and state-of-the-art attention methods on various practical tasks, including object classification, image segmentation, and language modeling across different data modalities.