 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMEx: Curvature-aware Merging of Experts
Feb 26, 2025

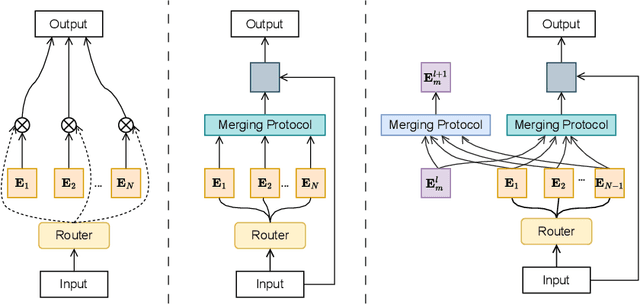

Existing methods for merging experts during model training and fine-tuning predominantly rely on Euclidean geometry, which assumes a flat parameter space. This assumption can limit the model's generalization ability, especially during the pre-training phase, where the parameter manifold might exhibit more complex curvature. Curvature-aware merging methods typically require additional information and computational resources to approximate the Fisher Information Matrix, adding memory overhead. In this paper, we introduce CAMEx (\textbf{C}urvature-\textbf{A}ware \textbf{M}erging of \textbf{Ex}perts), a novel expert merging protocol that incorporates natural gradients to account for the non-Euclidean curvature of the parameter manifold. By leveraging natural gradients, CAMEx adapts more effectively to the structure of the parameter space, improving alignment between model updates and the manifold's geometry. This approach enhances both pre-training and fine-tuning, resulting in better optimization trajectories and improved generalization without the substantial memory overhead typically associated with curvature-aware methods. Our contributions are threefold: (1) CAMEx significantly outperforms traditional Euclidean-based expert merging techniques across various natural language processing tasks, leading to enhanced performance during pre-training and fine-tuning; (2) we introduce a dynamic merging architecture that optimizes resource utilization, achieving high performance while reducing computational costs, facilitating efficient scaling of large language models; and (3) we provide both theoretical and empirical evidence to demonstrate the efficiency of our proposed method.
iMoT: Inertial Motion Transformer for Inertial Navigation
Dec 13, 2024
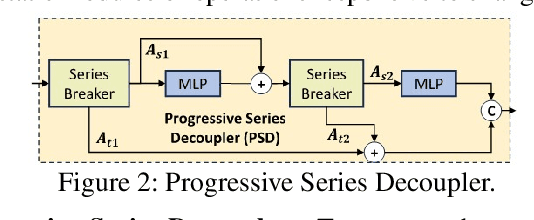


We propose iMoT, an innovative Transformer-based inertial odometry method that retrieves cross-modal information from motion and rotation modalities for accurate positional estimation. Unlike prior work, during the encoding of the motion context, we introduce Progressive Series Decoupler at the beginning of each encoder layer to stand out critical motion events inherent in acceleration and angular velocity signals. To better aggregate cross-modal interactions, we present Adaptive Positional Encoding, which dynamically modifies positional embeddings for temporal discrepancies between different modalities. During decoding, we introduce a small set of learnable query motion particles as priors to model motion uncertainties within velocity segments. Each query motion particle is intended to draw cross-modal features dedicated to a specific motion mode, all taken together allowing the model to refine its understanding of motion dynamics effectively. Lastly, we design a dynamic scoring mechanism to stabilize iMoT's optimization by considering all aligned motion particles at the final decoding step, ensuring robust and accurate velocity segment estimation. Extensive evaluations on various inertial datasets demonstrate that iMoT significantly outperforms state-of-the-art methods in delivering superior robustness and accuracy in trajectory reconstruction.
Multi-Surrogate-Teacher Assistance for Representation Alignment in Fingerprint-based Indoor Localization
Dec 13, 2024



Despite remarkable progress in knowledge transfer across visual and textual domains, extending these achievements to indoor localization, particularly for learning transferable representations among Received Signal Strength (RSS) fingerprint datasets, remains a challenge. This is due to inherent discrepancies among these RSS datasets, largely including variations in building structure, the input number and disposition of WiFi anchors. Accordingly, specialized networks, which were deprived of the ability to discern transferable representations, readily incorporate environment-sensitive clues into the learning process, hence limiting their potential when applied to specific RSS datasets. In this work, we propose a plug-and-play (PnP) framework of knowledge transfer, facilitating the exploitation of transferable representations for specialized networks directly on target RSS datasets through two main phases. Initially, we design an Expert Training phase, which features multiple surrogate generative teachers, all serving as a global adapter that homogenizes the input disparities among independent source RSS datasets while preserving their unique characteristics. In a subsequent Expert Distilling phase, we continue introducing a triplet of underlying constraints that requires minimizing the differences in essential knowledge between the specialized network and surrogate teachers through refining its representation learning on the target dataset. This process implicitly fosters a representational alignment in such a way that is less sensitive to specific environmental dynamics. Extensive experiments conducted on three benchmark WiFi RSS fingerprint datasets underscore the effectiveness of the framework that significantly exerts the full potential of specialized networks in localization.