 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecMind: Cognitively Inspired, Interactive Multi-Turn Framework for Postcondition Inference
Feb 25, 2026Specifications are vital for ensuring program correctness, yet writing them manually remains challenging and time-intensive. Recent large language model (LLM)-based methods have shown successes in generating specifications such as postconditions, but existing single-pass prompting often yields inaccurate results. In this paper, we present SpecMind, a novel framework for postcondition generation that treats LLMs as interactive and exploratory reasoners rather than one-shot generators. SpecMind employs feedback-driven multi-turn prompting approaches, enabling the model to iteratively refine candidate postconditions by incorporating implicit and explicit correctness feedback, while autonomously deciding when to stop. This process fosters deeper code comprehension and improves alignment with true program behavior via exploratory attempts. Our empirical evaluation shows that SpecMind significantly outperforms state-of-the-art approaches in both accuracy and completeness of generated postconditions.
Multi-Agent Coordinated Rename Refactoring
Jan 01, 2026The primary value of AI agents in software development lies in their ability to extend the developer's capacity for reasoning and action, not to supplant human involvement. To showcase how to use agents working in tandem with developers, we designed a novel approach for carrying out coordinated renaming. Coordinated renaming, where a single rename refactoring triggers refactorings in multiple, related identifiers, is a frequent yet challenging task. Developers must manually propagate these rename refactorings across numerous files and contexts, a process that is both tedious and highly error-prone. State-of-the-art heuristic-based approaches produce an overwhelming number of false positives, while vanilla Large Language Models (LLMs) provide incomplete suggestions due to their limited context and inability to interact with refactoring tools. This leaves developers with incomplete refactorings or burdens them with filtering too many false positives. Coordinated renaming is exactly the kind of repetitive task that agents can significantly reduce the developers' burden while keeping them in the driver's seat. We designed, implemented, and evaluated the first multi-agent framework that automates coordinated renaming. It operates on a key insight: a developer's initial refactoring is a clue to infer the scope of related refactorings. Our Scope Inference Agent first transforms this clue into an explicit, natural-language Declared Scope. The Planned Execution Agent then uses this as a strict plan to identify program elements that should undergo refactoring and safely executes the changes by invoking the IDE's own trusted refactoring APIs. Finally, the Replication Agent uses it to guide the project-wide search. We first conducted a formative study on the practice of coordinated renaming in 609K commits in 100 open-source projects and surveyed 205 developers ...
Fuzzwise: Intelligent Initial Corpus Generation for Fuzzing
Dec 24, 2025In mutation-based greybox fuzzing, generating high-quality input seeds for the initial corpus is essential for effective fuzzing. Rather than conducting separate phases for generating a large corpus and subsequently minimizing it, we propose FuzzWise which integrates them into one process to generate the optimal initial corpus of seeds (ICS). FuzzWise leverages a multi-agent framework based on Large Language Models (LLMs). The first LLM agent generates test cases for the target program. The second LLM agent, which functions as a predictive code coverage module, assesses whether each generated test case will enhance the overall coverage of the current corpus. The streamlined process allows each newly generated test seed to be immediately evaluated for its contribution to the overall coverage. FuzzWise employs a predictive approach using an LLM and eliminates the need for actual execution, saving computational resources and time, particularly in scenarios where the execution is not desirable or even impossible. Our empirical evaluation demonstrates that FuzzWise generates significantly fewer test cases than baseline methods. Despite the lower number of test cases, FuzzWise achieves high code coverage and triggers more runtime errors compared to the baselines. Moreover, it is more time-efficient and coverage-efficient in producing an initial corpus catching more errors.
Cerberus: Multi-Agent Reasoning and Coverage-Guided Exploration for Static Detection of Runtime Errors
Dec 24, 2025
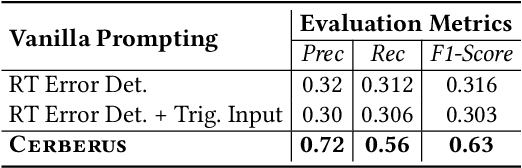


In several software development scenarios, it is desirable to detect runtime errors and exceptions in code snippets without actual execution. A typical example is to detect runtime exceptions in online code snippets before integrating them into a codebase. In this paper, we propose Cerberus, a novel predictive, execution-free coverage-guided testing framework. Cerberus uses LLMs to generate the inputs that trigger runtime errors and to perform code coverage prediction and error detection without code execution. With a two-phase feedback loop, Cerberus first aims to both increasing code coverage and detecting runtime errors, then shifts to focus only detecting runtime errors when the coverage reaches 100% or its maximum, enabling it to perform better than prompting the LLMs for both purposes. Our empirical evaluation demonstrates that Cerberus performs better than conventional and learning-based testing frameworks for (in)complete code snippets by generating high-coverage test cases more efficiently, leading to the discovery of more runtime errors.
SWE-Synth: Synthesizing Verifiable Bug-Fix Data to Enable Large Language Models in Resolving Real-World Bugs
Apr 20, 2025Large language models (LLMs) are transforming automated program repair (APR) through agent-based approaches that localize bugs, generate patches, and verify fixes. However, the lack of high-quality, scalable training datasets, especially those with verifiable outputs and intermediate reasoning traces-limits progress, particularly for open-source models. In this work, we present SWE-Synth, a framework for synthesizing realistic, verifiable, and process-aware bug-fix datasets at the repository level. SWE-Synth leverages LLM agents to simulate debugging workflows, producing not only bug-fix pairs but also test cases and structured repair trajectories. Compared to manually curated datasets, our method scales with minimal human effort while preserving contextual richness and correctness. Experiments show that models trained on SWE-Synth outperform those trained on real-world datasets by 2.3% on SWE-Bench Lite. Our results highlight the potential of synthetic, agent-generated data to advance the state of the art in APR and software engineering automation.
Rectifier: Code Translation with Corrector via LLMs
Jul 10, 2024Software migration is garnering increasing attention with the evolution of software and society. Early studies mainly relied on handcrafted translation rules to translate between two languages, the translation process is error-prone and time-consuming. In recent years, researchers have begun to explore the use of pre-trained large language models (LLMs) in code translation. However, code translation is a complex task that LLMs would generate mistakes during code translation, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). In this paper, we propose a general corrector, namely Rectifier, which is a micro and universal model for repairing translation errors. It learns from errors generated by existing LLMs and can be widely applied to correct errors generated by any LLM. The experimental results on translation tasks between C++, Java, and Python show that our model has effective repair ability, and cross experiments also demonstrate the robustness of our method.
RepoHyper: Better Context Retrieval Is All You Need for Repository-Level Code Completion
Mar 16, 2024Code Large Language Models (CodeLLMs) have demonstrated impressive proficiency in code completion tasks. However, they often fall short of fully understanding the extensive context of a project repository, such as the intricacies of relevant files and class hierarchies, which can result in less precise completions. To overcome these limitations, we present \tool, a multifaceted framework designed to address the complex challenges associated with repository-level code completion. Central to \tool is the {\em Repo-level Semantic Graph} (RSG), a novel semantic graph structure that encapsulates the vast context of code repositories. Furthermore, RepoHyper leverages \textit{Expand and Refine} retrieval method, including a graph expansion and a link prediction algorithm applied to the RSG, enabling the effective retrieval and prioritization of relevant code snippets. Our evaluations show that \tool markedly outperforms existing techniques in repository-level code completion, showcasing enhanced accuracy across various datasets when compared to several strong baselines. Our implementation of RepoHyper can be found at~\url{https://github.com/FSoft-AI4Code/RepoHyper}.
Better Language Models of Code through Self-Improvement
Apr 02, 2023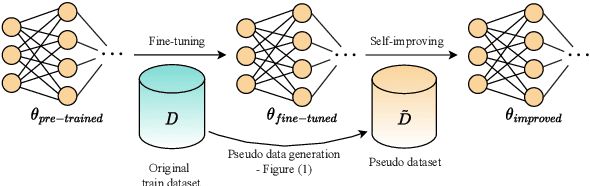
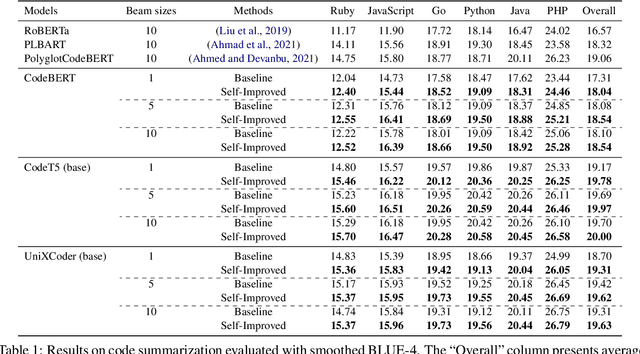
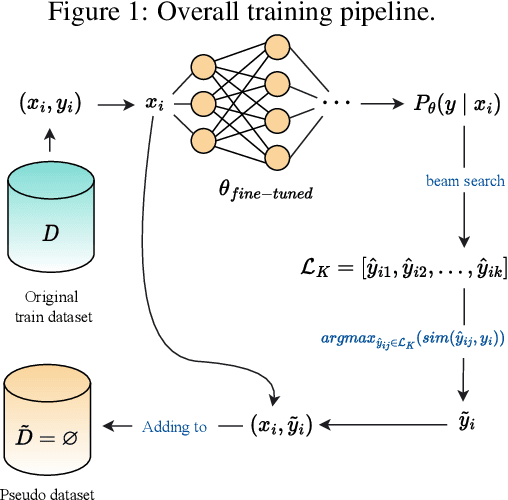
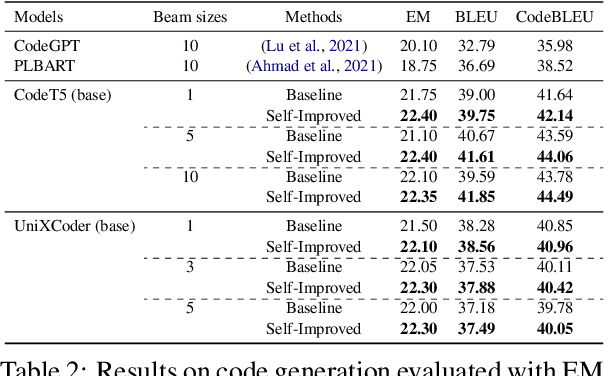
Pre-trained language models for code (PLMCs) have gained attention in recent research. These models are pre-trained on large-scale datasets using multi-modal objectives. However, fine-tuning them requires extensive supervision and is limited by the size of the dataset provided. We aim to improve this issue by proposing a simple data augmentation framework. Our framework utilizes knowledge gained during the pre-training and fine-tuning stage to generate pseudo data, which is then used as training data for the next step. We incorporate this framework into the state-of-the-art language models, such as CodeT5, CodeBERT, and UnixCoder. The results show that our framework significantly improves PLMCs' performance in code-related sequence generation tasks, such as code summarization and code generation in the CodeXGLUE benchmark.
Does BLEU Score Work for Code Migration?
Jun 12, 2019

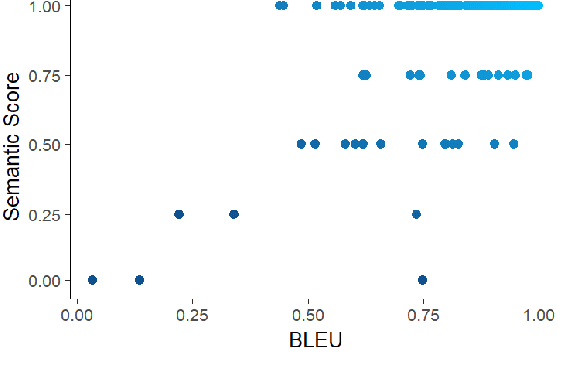

Statistical machine translation (SMT) is a fast-growing sub-field of computational linguistics. Until now, the most popular automatic metric to measure the quality of SMT is BiLingual Evaluation Understudy (BLEU) score. Lately, SMT along with the BLEU metric has been applied to a Software Engineering task named code migration. (In)Validating the use of BLEU score could advance the research and development of SMT-based code migration tools. Unfortunately, there is no study to approve or disapprove the use of BLEU score for source code. In this paper, we conducted an empirical study on BLEU score to (in)validate its suitability for the code migration task due to its inability to reflect the semantics of source code. In our work, we use human judgment as the ground truth to measure the semantic correctness of the migrated code. Our empirical study demonstrates that BLEU does not reflect translation quality due to its weak correlation with the semantic correctness of translated code. We provided counter-examples to show that BLEU is ineffective in comparing the translation quality between SMT-based models. Due to BLEU's ineffectiveness for code migration task, we propose an alternative metric RUBY, which considers lexical, syntactical, and semantic representations of source code. We verified that RUBY achieves a higher correlation coefficient with the semantic correctness of migrated code, 0.775 in comparison with 0.583 of BLEU score. We also confirmed the effectiveness of RUBY in reflecting the changes in translation quality of SMT-based translation models. With its advantages, RUBY can be used to evaluate SMT-based code migration models.