 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Project-Specific Code Completion by Inferring Internal API Information
Jul 28, 2025Project-specific code completion is a critical task that leverages context from a project to generate accurate code. State-of-the-art methods use retrieval-augmented generation (RAG) with large language models (LLMs) and project information for code completion. However, they often struggle to incorporate internal API information, which is crucial for accuracy, especially when APIs are not explicitly imported in the file. To address this, we propose a method to infer internal API information without relying on imports. Our method extends the representation of APIs by constructing usage examples and semantic descriptions, building a knowledge base for LLMs to generate relevant completions. We also introduce ProjBench, a benchmark that avoids leaked imports and consists of large-scale real-world projects. Experiments on ProjBench and CrossCodeEval show that our approach significantly outperforms existing methods, improving code exact match by 22.72% and identifier exact match by 18.31%. Additionally, integrating our method with existing baselines boosts code match by 47.80% and identifier match by 35.55%.
Learning to Align Human Code Preferences
Jul 27, 2025Large Language Models (LLMs) have demonstrated remarkable potential in automating software development tasks. While recent advances leverage Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to align models with human preferences, the optimal training strategy remains unclear across diverse code preference scenarios. This paper systematically investigates the roles of SFT and DPO in aligning LLMs with different code preferences. Through both theoretical analysis and empirical observation, we hypothesize that SFT excels in scenarios with objectively verifiable optimal solutions, while applying SFT followed by DPO (S&D) enables models to explore superior solutions in scenarios without objectively verifiable optimal solutions. Based on the analysis and experimental evidence, we propose Adaptive Preference Optimization (APO), a dynamic integration approach that adaptively amplifies preferred responses, suppresses dispreferred ones, and encourages exploration of potentially superior solutions during training. Extensive experiments across six representative code preference tasks validate our theoretical hypotheses and demonstrate that APO consistently matches or surpasses the performance of existing SFT and S&D strategies. Our work provides both theoretical foundations and practical guidance for selecting appropriate training strategies in different code preference alignment scenarios.
Learning-based Models for Vulnerability Detection: An Extensive Study
Aug 14, 2024Though many deep learning-based models have made great progress in vulnerability detection, we have no good understanding of these models, which limits the further advancement of model capability, understanding of the mechanism of model detection, and efficiency and safety of practical application of models. In this paper, we extensively and comprehensively investigate two types of state-of-the-art learning-based approaches (sequence-based and graph-based) by conducting experiments on a recently built large-scale dataset. We investigate seven research questions from five dimensions, namely model capabilities, model interpretation, model stability, ease of use of model, and model economy. We experimentally demonstrate the priority of sequence-based models and the limited abilities of both LLM (ChatGPT) and graph-based models. We explore the types of vulnerability that learning-based models skilled in and reveal the instability of the models though the input is subtlely semantical-equivalently changed. We empirically explain what the models have learned. We summarize the pre-processing as well as requirements for easily using the models. Finally, we initially induce the vital information for economically and safely practical usage of these models.
Rectifier: Code Translation with Corrector via LLMs
Jul 10, 2024Software migration is garnering increasing attention with the evolution of software and society. Early studies mainly relied on handcrafted translation rules to translate between two languages, the translation process is error-prone and time-consuming. In recent years, researchers have begun to explore the use of pre-trained large language models (LLMs) in code translation. However, code translation is a complex task that LLMs would generate mistakes during code translation, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). In this paper, we propose a general corrector, namely Rectifier, which is a micro and universal model for repairing translation errors. It learns from errors generated by existing LLMs and can be widely applied to correct errors generated by any LLM. The experimental results on translation tasks between C++, Java, and Python show that our model has effective repair ability, and cross experiments also demonstrate the robustness of our method.
Exploring ChatGPT's Ability to Rank Content: A Preliminary Study on Consistency with Human Preferences
Mar 14, 2023



As a natural language assistant, ChatGPT is capable of performing various tasks, including but not limited to article generation, code completion, and data analysis. Furthermore, ChatGPT has consistently demonstrated a remarkable level of accuracy and reliability in terms of content evaluation, exhibiting the capability of mimicking human preferences. To further explore ChatGPT's potential in this regard, a study is conducted to assess its ability to rank content. In order to do so, a test set consisting of prompts is created, covering a wide range of use cases, and five models are utilized to generate corresponding responses. ChatGPT is then instructed to rank the responses generated by these models. The results on the test set show that ChatGPT's ranking preferences are consistent with human to a certain extent. This preliminary experimental finding implies that ChatGPT's zero-shot ranking capability could be used to reduce annotation pressure in a number of ranking tasks.
Fast and Compute-efficient Sampling-based Local Exploration Planning via Distribution Learning
Feb 28, 2022
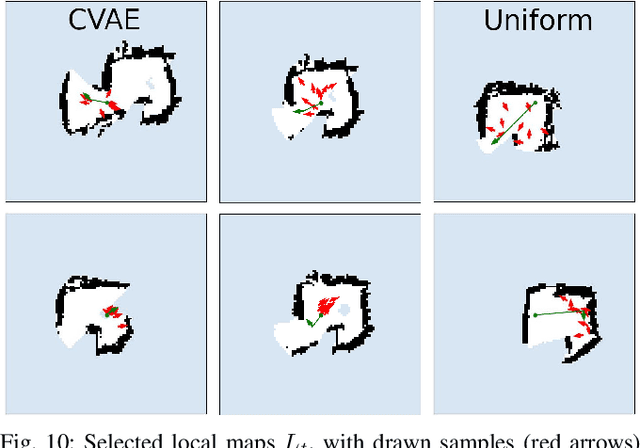


Exploration is a fundamental problem in robotics. While sampling-based planners have shown high performance, they are oftentimes compute intensive and can exhibit high variance. To this end, we propose to directly learn the underlying distribution of informative views based on the spatial context in the robot's map. We further explore a variety of methods to also learn the information gain. We show in thorough experimental evaluation that our proposed system improves exploration performance by up to 28\% over classical methods, and find that learning the gains in addition to the sampling distribution can provide favorable performance vs. compute trade-offs for compute-constrained systems. We demonstrate in simulation and on a low-cost mobile robot that our system generalizes well to varying environments.