 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model
Apr 18, 2023



Recently, the instruction-tuning of large language models is a crucial area of research in the field of natural language processing. Due to resource and cost limitations, several researchers have employed parameter-efficient tuning techniques, such as LoRA, for instruction tuning, and have obtained encouraging results In comparison to full-parameter fine-tuning, LoRA-based tuning demonstrates salient benefits in terms of training costs. In this study, we undertook experimental comparisons between full-parameter fine-tuning and LoRA-based tuning methods, utilizing LLaMA as the base model. The experimental results show that the selection of the foundational model, training dataset scale, learnable parameter quantity, and model training cost are all important factors. We hope that the experimental conclusions of this paper can provide inspiration for training large language models, especially in the field of Chinese, and help researchers find a better trade-off strategy between training cost and model performance. To facilitate the reproduction of the paper's results, the dataset, model and code will be released.
Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation
Apr 16, 2023Recently, significant public efforts have been directed towards developing low-cost models with capabilities akin to ChatGPT, thereby fostering the growth of open-source conversational models. However, there remains a scarcity of comprehensive and in-depth evaluations of these models' performance. In this study, we examine the influence of training data factors, including quantity, quality, and linguistic distribution, on model performance. Our analysis is grounded in several publicly accessible, high-quality instruction datasets, as well as our own Chinese multi-turn conversations. We assess various models using a evaluation set of 1,000 samples, encompassing nine real-world scenarios. Our goal is to supplement manual evaluations with quantitative analyses, offering valuable insights for the continued advancement of open-source chat models. Furthermore, to enhance the performance and training and inference efficiency of models in the Chinese domain, we extend the vocabulary of LLaMA - the model with the closest open-source performance to proprietary language models like GPT-3 - and conduct secondary pre-training on 3.4B Chinese words. We make our model, data, as well as code publicly available.
Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases
Mar 26, 2023



The success of ChatGPT has recently attracted numerous efforts to replicate it, with instruction-tuning strategies being a key factor in achieving remarkable results. Instruction-tuning not only significantly enhances the model's performance and generalization but also makes the model's generated results more consistent with human speech patterns. However current research rarely studies the impact of different amounts of instruction data on model performance, especially in the real-world use cases. In this paper we explore the performance of large language models based on instruction tuning across different scales of instruction data. An evaluation dataset consisting of 12 major online use cases is constructed in the experiment. With Bloomz-7B1-mt as the base model, the results show that 1) merely increasing the amount of instruction data leads to continuous improvement in tasks such as open-ended generation, 2) in tasks such as math and code, the model performance curve remains quite flat while increasing data size. We further analyze the possible causes of these phenomena and propose potential future research directions such as effectively selecting high-quality training data, scaling base models and training methods specialized for hard tasks. We will release our training and evaluation datasets, as well as model checkpoints.
Exploring ChatGPT's Ability to Rank Content: A Preliminary Study on Consistency with Human Preferences
Mar 14, 2023



As a natural language assistant, ChatGPT is capable of performing various tasks, including but not limited to article generation, code completion, and data analysis. Furthermore, ChatGPT has consistently demonstrated a remarkable level of accuracy and reliability in terms of content evaluation, exhibiting the capability of mimicking human preferences. To further explore ChatGPT's potential in this regard, a study is conducted to assess its ability to rank content. In order to do so, a test set consisting of prompts is created, covering a wide range of use cases, and five models are utilized to generate corresponding responses. ChatGPT is then instructed to rank the responses generated by these models. The results on the test set show that ChatGPT's ranking preferences are consistent with human to a certain extent. This preliminary experimental finding implies that ChatGPT's zero-shot ranking capability could be used to reduce annotation pressure in a number of ranking tasks.
BEIKE NLP at SemEval-2022 Task 4: Prompt-Based Paragraph Classification for Patronizing and Condescending Language Detection
Aug 02, 2022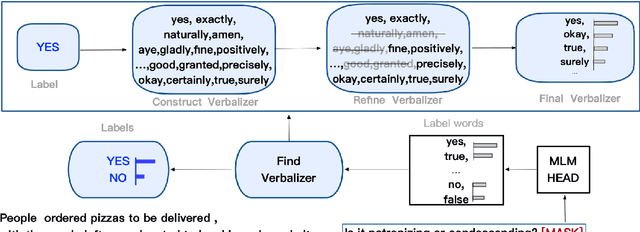
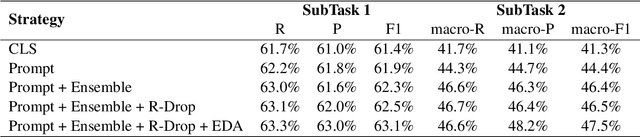
PCL detection task is aimed at identifying and categorizing language that is patronizing or condescending towards vulnerable communities in the general media.Compared to other NLP tasks of paragraph classification, the negative language presented in the PCL detection task is usually more implicit and subtle to be recognized, making the performance of common text-classification approaches disappointed. Targeting the PCL detection problem in SemEval-2022 Task 4, in this paper, we give an introduction to our team's solution, which exploits the power of prompt-based learning on paragraph classification. We reformulate the task as an appropriate cloze prompt and use pre-trained Masked Language Models to fill the cloze slot. For the two subtasks, binary classification and multi-label classification, DeBERTa model is adopted and fine-tuned to predict masked label words of task-specific prompts. On the evaluation dataset, for binary classification, our approach achieves an F1-score of 0.6406; for multi-label classification, our approach achieves an macro-F1-score of 0.4689 and ranks first in the leaderboard.
To Answer or Not to Answer? Improving Machine Reading Comprehension Model with Span-based Contrastive Learning
Aug 02, 2022

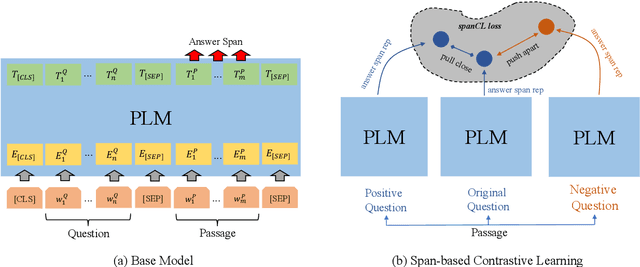
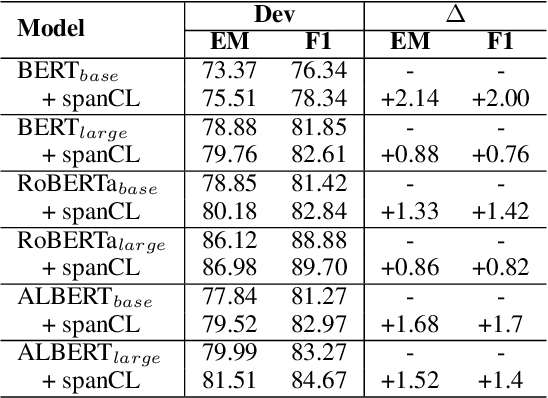
Machine Reading Comprehension with Unanswerable Questions is a difficult NLP task, challenged by the questions which can not be answered from passages. It is observed that subtle literal changes often make an answerable question unanswerable, however, most MRC models fail to recognize such changes. To address this problem, in this paper, we propose a span-based method of Contrastive Learning (spanCL) which explicitly contrast answerable questions with their answerable and unanswerable counterparts at the answer span level. With spanCL, MRC models are forced to perceive crucial semantic changes from slight literal differences. Experiments on SQuAD 2.0 dataset show that spanCL can improve baselines significantly, yielding 0.86-2.14 absolute EM improvements. Additional experiments also show that spanCL is an effective way to utilize generated questions.
Selective Attention Encoders by Syntactic Graph Convolutional Networks for Document Summarization
Mar 18, 2020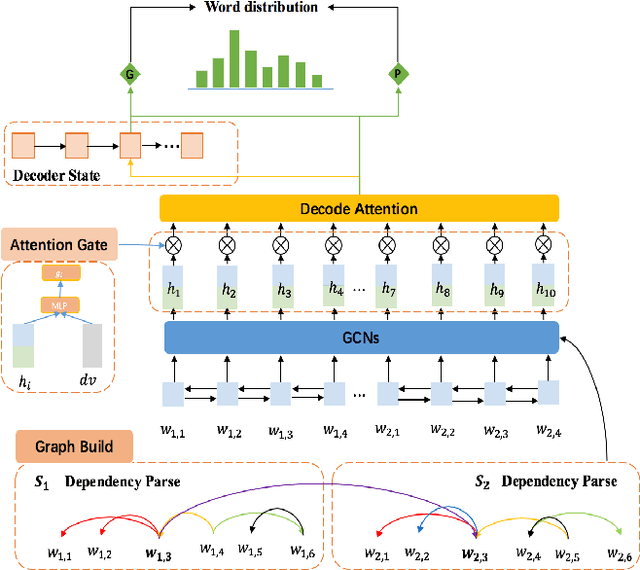
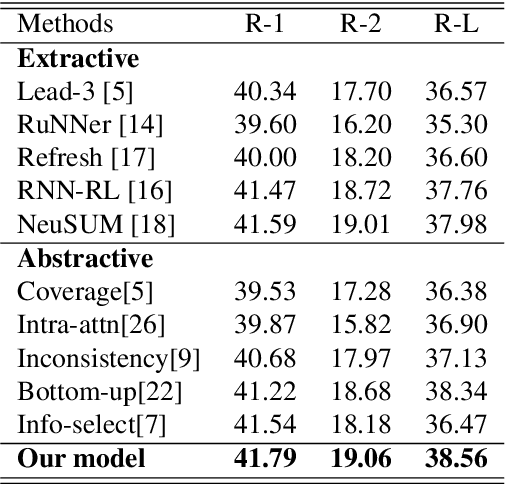
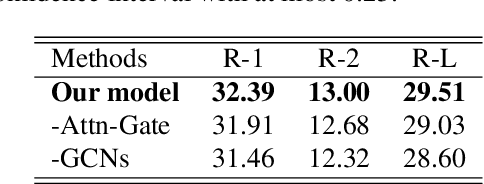
Abstractive text summarization is a challenging task, and one need to design a mechanism to effectively extract salient information from the source text and then generate a summary. A parsing process of the source text contains critical syntactic or semantic structures, which is useful to generate more accurate summary. However, modeling a parsing tree for text summarization is not trivial due to its non-linear structure and it is harder to deal with a document that includes multiple sentences and their parsing trees. In this paper, we propose to use a graph to connect the parsing trees from the sentences in a document and utilize the stacked graph convolutional networks (GCNs) to learn the syntactic representation for a document. The selective attention mechanism is used to extract salient information in semantic and structural aspect and generate an abstractive summary. We evaluate our approach on the CNN/Daily Mail text summarization dataset. The experimental results show that the proposed GCNs based selective attention approach outperforms the baselines and achieves the state-of-the-art performance on the dataset.
DELTA: A DEep learning based Language Technology plAtform
Aug 02, 2019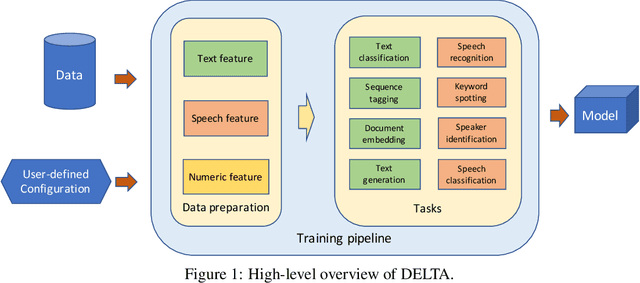
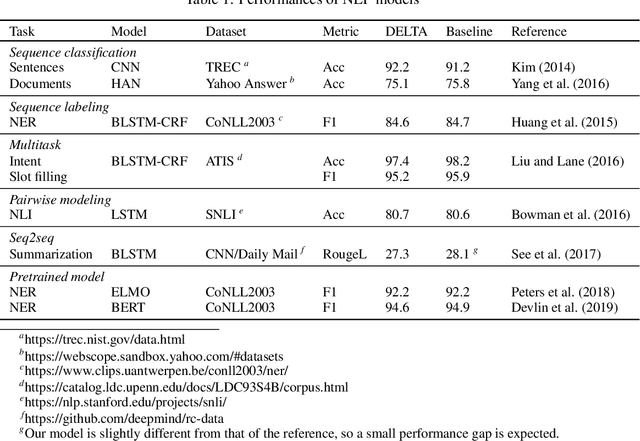
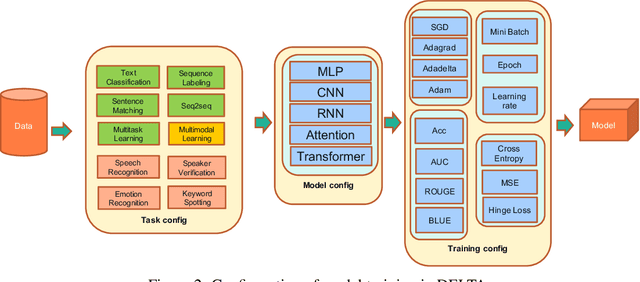
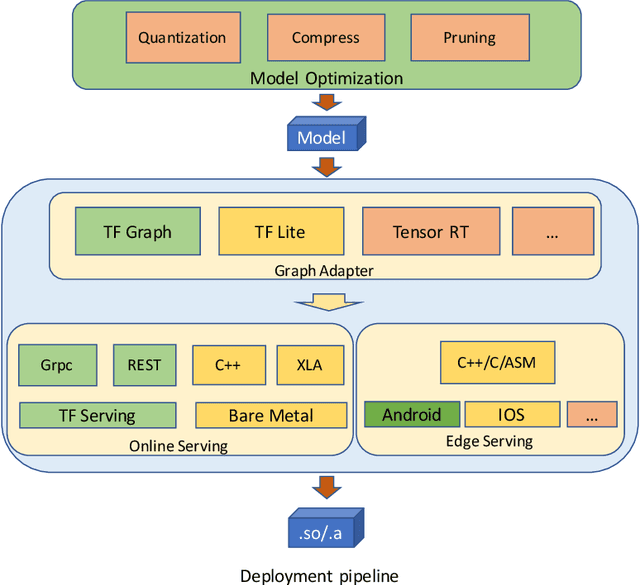
In this paper we present DELTA, a deep learning based language technology platform. DELTA is an end-to-end platform designed to solve industry level natural language and speech processing problems. It integrates most popular neural network models for training as well as comprehensive deployment tools for production. DELTA aims to provide easy and fast experiences for using, deploying, and developing natural language processing and speech models for both academia and industry use cases. We demonstrate the reliable performance with DELTA on several natural language processing and speech tasks, including text classification, named entity recognition, natural language inference, speech recognition, speaker verification, etc. DELTA has been used for developing several state-of-the-art algorithms for publications and delivering real production to serve millions of users.