 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Distinct Representations for Every Speech Token? Unveiling and Exploiting Redundancy in Large Speech Language Models
Apr 08, 2026Large Speech Language Models (LSLMs) typically operate at high token rates (tokens/s) to ensure acoustic fidelity, yet this results in sequence lengths that far exceed the underlying semantic content, incurring prohibitive inference costs. In this paper, we empirically revisit the necessity of such granular token-level processing. Through layer-wise oracle interventions, we unveil a structured redundancy hierarchy: while shallow layers encode essential acoustic details, deep layers exhibit extreme redundancy, allowing for aggressive compression. Motivated by these findings, we introduce Affinity Pooling, a training-free, similarity-based token merging mechanism. By strategically applying this method at both input and deep layers, we effectively compress speech representations without compromising semantic information. Extensive evaluations across three tasks demonstrate that our approach reduces prefilling FLOPs by 27.48\% while maintaining competitive accuracy. Practical deployment further confirms significant efficiency gains, yielding up to $\sim$1.7$\times$ memory savings and $\sim$1.1$\times$ faster time-to-first-token on long utterances. Our results challenge the necessity of fully distinct token representations, providing new perspectives on LSLM efficiency.
SARI: Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning
Apr 22, 2025Recent work shows that reinforcement learning(RL) can markedly sharpen the reasoning ability of large language models (LLMs) by prompting them to "think before answering." Yet whether and how these gains transfer to audio-language reasoning remains largely unexplored. We extend the Group-Relative Policy Optimization (GRPO) framework from DeepSeek-R1 to a Large Audio-Language Model (LALM), and construct a 32k sample multiple-choice corpus. Using a two-stage regimen supervised fine-tuning on structured and unstructured chains-of-thought, followed by curriculum-guided GRPO, we systematically compare implicit vs. explicit, and structured vs. free form reasoning under identical architectures. Our structured audio reasoning model, SARI (Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning), achieves a 16.35% improvement in average accuracy over the base model Qwen2-Audio-7B-Instruct. Furthermore, the variant built upon Qwen2.5-Omni reaches state-of-the-art performance of 67.08% on the MMAU test-mini benchmark. Ablation experiments show that on the base model we use: (i) SFT warm-up is important for stable RL training, (ii) structured chains yield more robust generalization than unstructured ones, and (iii) easy-to-hard curricula accelerate convergence and improve final performance. These findings demonstrate that explicit, structured reasoning and curriculum learning substantially enhances audio-language understanding.
Advancing Speech Language Models by Scaling Supervised Fine-Tuning with Over 60,000 Hours of Synthetic Speech Dialogue Data
Dec 03, 2024



The GPT-4o represents a significant milestone in enabling real-time interaction with large language models (LLMs) through speech, its remarkable low latency and high fluency not only capture attention but also stimulate research interest in the field. This real-time speech interaction is particularly valuable in scenarios requiring rapid feedback and immediate responses, dramatically enhancing user experience. However, there is a notable lack of research focused on real-time large speech language models, particularly for Chinese. In this work, we present KE-Omni, a seamless large speech language model built upon Ke-SpeechChat, a large-scale high-quality synthetic speech interaction dataset consisting of 7 million Chinese and English conversations, featuring 42,002 speakers, and totaling over 60,000 hours, This contributes significantly to the advancement of research and development in this field. The demos can be accessed at \url{https://huggingface.co/spaces/KE-Team/KE-Omni}.
VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
Nov 05, 2022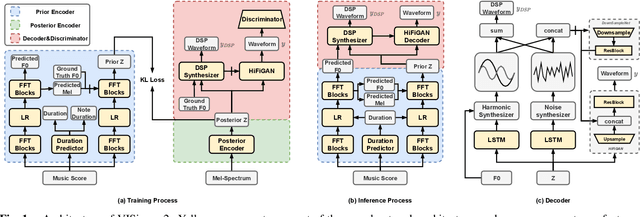
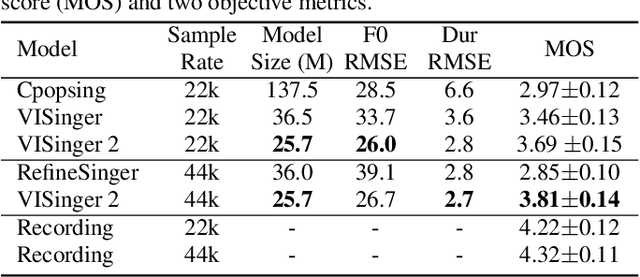
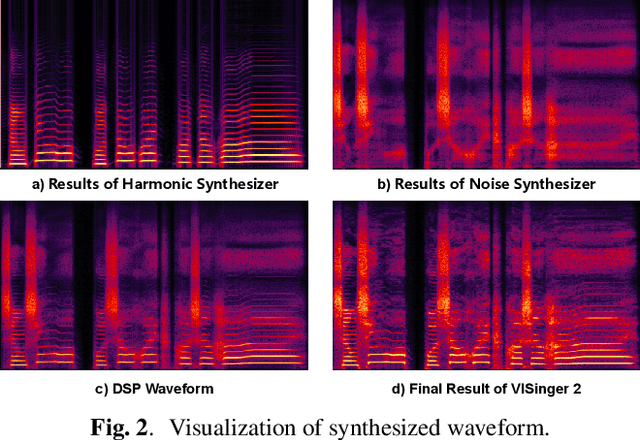
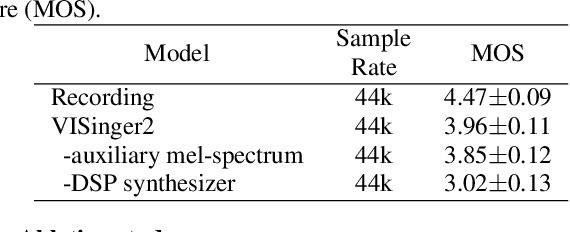
End-to-end singing voice synthesis (SVS) model VISinger can achieve better performance than the typical two-stage model with fewer parameters. However, VISinger has several problems: text-to-phase problem, the end-to-end model learns the meaningless mapping of text-to-phase; glitches problem, the harmonic components corresponding to the periodic signal of the voiced segment occurs a sudden change with audible artefacts; low sampling rate, the sampling rate of 24KHz does not meet the application needs of high-fidelity generation with the full-band rate (44.1KHz or higher). In this paper, we propose VISinger 2 to address these issues by integrating the digital signal processing (DSP) methods with VISinger. Specifically, inspired by recent advances in differentiable digital signal processing (DDSP), we incorporate a DSP synthesizer into the decoder to solve the above issues. The DSP synthesizer consists of a harmonic synthesizer and a noise synthesizer to generate periodic and aperiodic signals, respectively, from the latent representation z in VISinger. It supervises the posterior encoder to extract the latent representation without phase information and avoid the prior encoder modelling text-to-phase mapping. To avoid glitch artefacts, the HiFi-GAN is modified to accept the waveforms generated by the DSP synthesizer as a condition to produce the singing voice. Moreover, with the improved waveform decoder, VISinger 2 manages to generate 44.1kHz singing audio with richer expression and better quality. Experiments on OpenCpop corpus show that VISinger 2 outperforms VISinger, CpopSing and RefineSinger in both subjective and objective metrics.
Audio-Visual Wake Word Spotting System For MISP Challenge 2021
Apr 20, 2022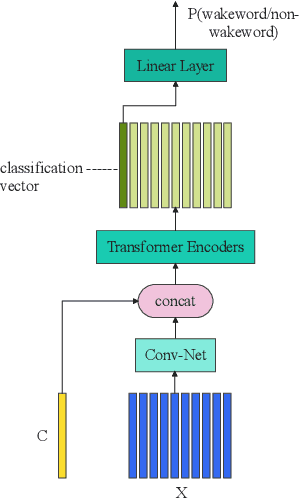
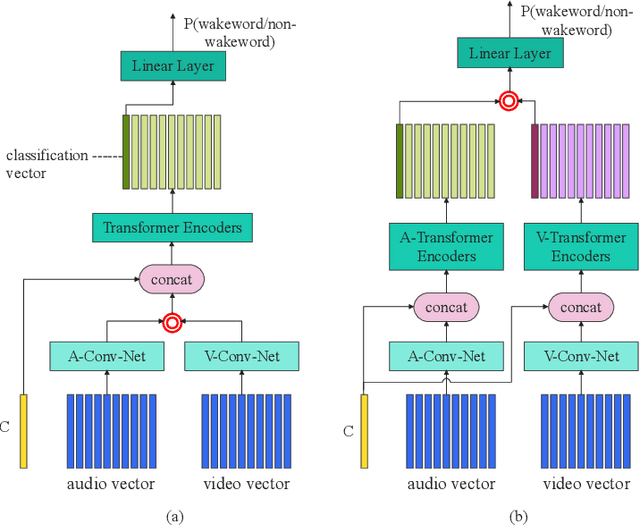

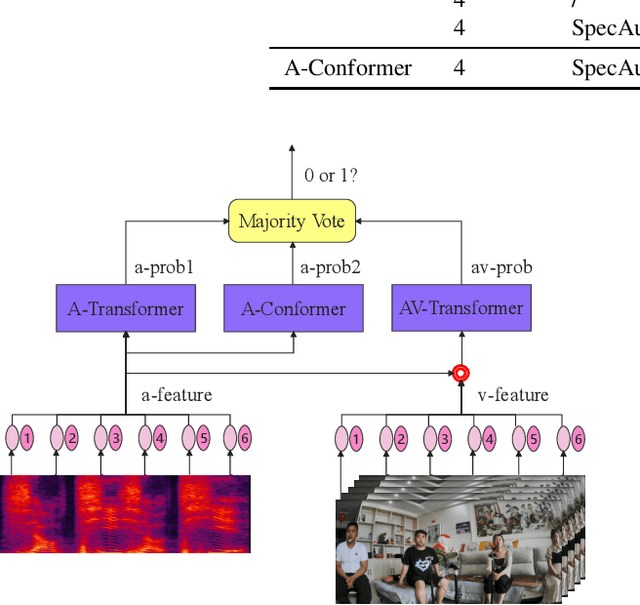
This paper presents the details of our system designed for the Task 1 of Multimodal Information Based Speech Processing (MISP) Challenge 2021. The purpose of Task 1 is to leverage both audio and video information to improve the environmental robustness of far-field wake word spotting. In the proposed system, firstly, we take advantage of speech enhancement algorithms such as beamforming and weighted prediction error (WPE) to address the multi-microphone conversational audio. Secondly, several data augmentation techniques are applied to simulate a more realistic far-field scenario. For the video information, the provided region of interest (ROI) is used to obtain visual representation. Then the multi-layer CNN is proposed to learn audio and visual representations, and these representations are fed into our two-branch attention-based network which can be employed for fusion, such as transformer and conformed. The focal loss is used to fine-tune the model and improve the performance significantly. Finally, multiple trained models are integrated by casting vote to achieve our final 0.091 score.
Time Domain Adversarial Voice Conversion for ADD 2022
Apr 20, 2022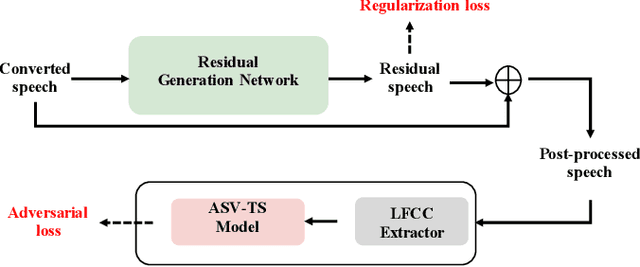

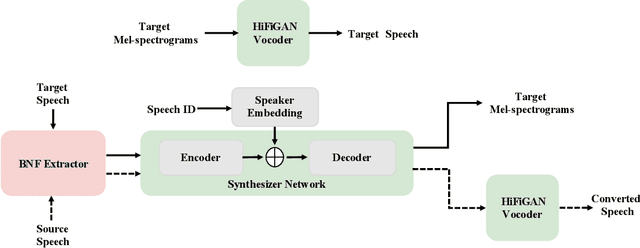
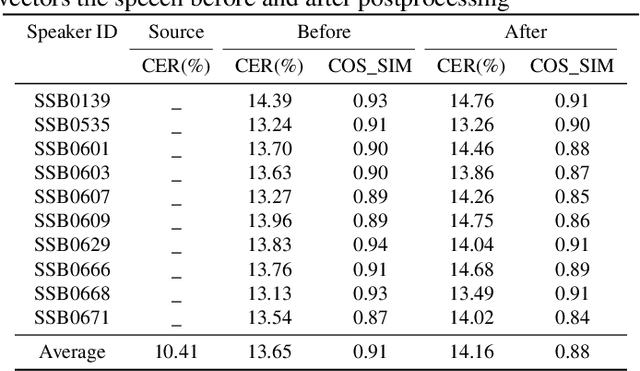
In this paper, we describe our speech generation system for the first Audio Deep Synthesis Detection Challenge (ADD 2022). Firstly, we build an any-to-many voice conversion (VC) system to convert source speech with arbitrary language content into the target speaker%u2019s fake speech. Then the converted speech generated from VC is post-processed in the time domain to improve the deception ability. The experimental results show that our system has adversarial ability against anti-spoofing detectors with a little compromise in audio quality and speaker similarity. This system ranks top in Track 3.1 in the ADD 2022, showing that our method could also gain good generalization ability against different detectors.
Audio Deep Fake Detection System with Neural Stitching for ADD 2022
Apr 20, 2022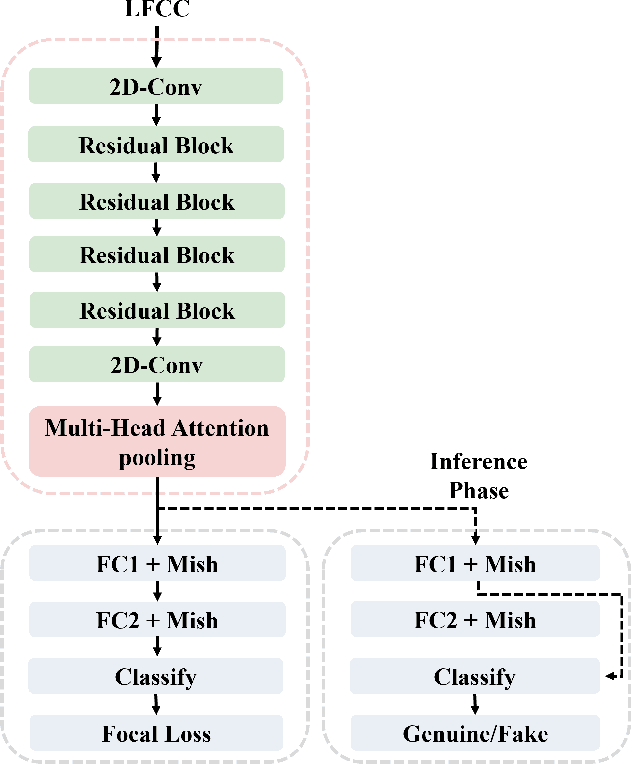
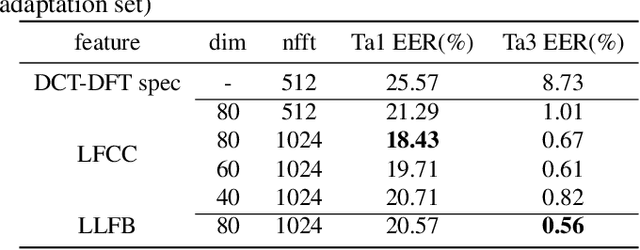


This paper describes our best system and methodology for ADD 2022: The First Audio Deep Synthesis Detection Challenge\cite{Yi2022ADD}. The very same system was used for both two rounds of evaluation in Track 3.2 with a similar training methodology. The first round of Track 3.2 data is generated from Text-to-Speech(TTS) or voice conversion (VC) algorithms, while the second round of data consists of generated fake audio from other participants in Track 3.1, aiming to spoof our systems. Our systems use a standard 34-layer ResNet, with multi-head attention pooling \cite{india2019self} to learn the discriminative embedding for fake audio and spoof detection. We further utilize neural stitching to boost the model's generalization capability in order to perform equally well in different tasks, and more details will be explained in the following sessions. The experiments show that our proposed method outperforms all other systems with a 10.1% equal error rate(EER) in Track 3.2.
DELTA: A DEep learning based Language Technology plAtform
Aug 02, 2019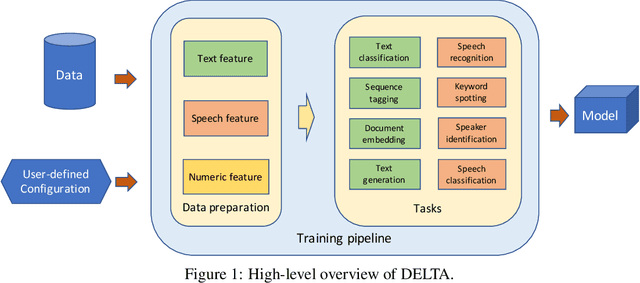
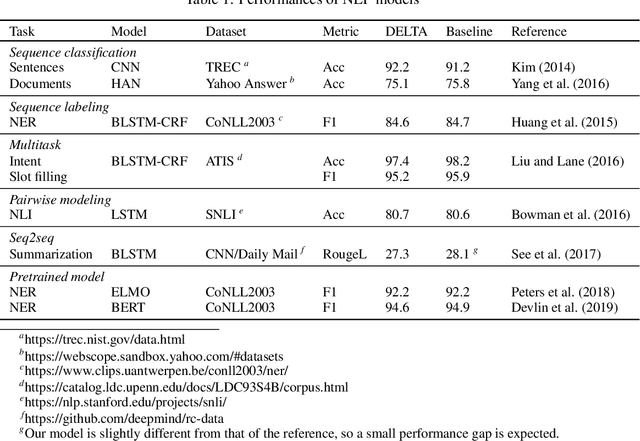
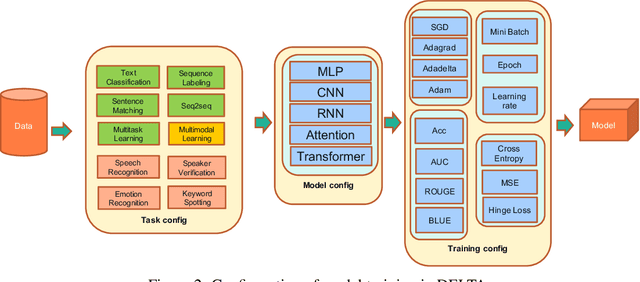
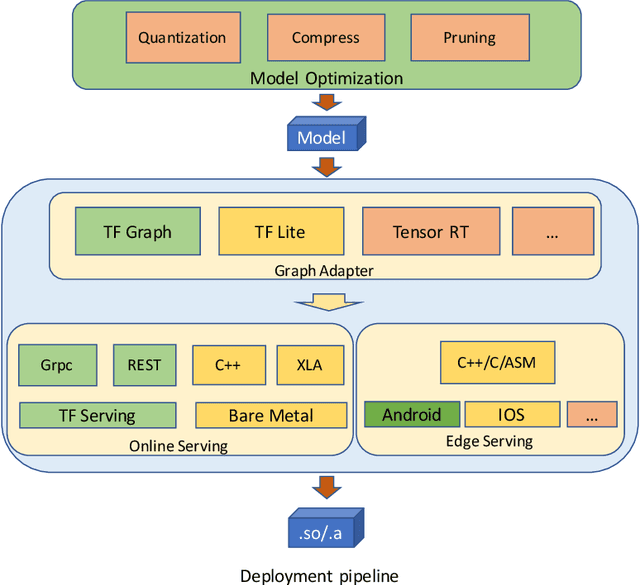
In this paper we present DELTA, a deep learning based language technology platform. DELTA is an end-to-end platform designed to solve industry level natural language and speech processing problems. It integrates most popular neural network models for training as well as comprehensive deployment tools for production. DELTA aims to provide easy and fast experiences for using, deploying, and developing natural language processing and speech models for both academia and industry use cases. We demonstrate the reliable performance with DELTA on several natural language processing and speech tasks, including text classification, named entity recognition, natural language inference, speech recognition, speaker verification, etc. DELTA has been used for developing several state-of-the-art algorithms for publications and delivering real production to serve millions of users.