 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
SARI: Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning
Apr 22, 2025Recent work shows that reinforcement learning(RL) can markedly sharpen the reasoning ability of large language models (LLMs) by prompting them to "think before answering." Yet whether and how these gains transfer to audio-language reasoning remains largely unexplored. We extend the Group-Relative Policy Optimization (GRPO) framework from DeepSeek-R1 to a Large Audio-Language Model (LALM), and construct a 32k sample multiple-choice corpus. Using a two-stage regimen supervised fine-tuning on structured and unstructured chains-of-thought, followed by curriculum-guided GRPO, we systematically compare implicit vs. explicit, and structured vs. free form reasoning under identical architectures. Our structured audio reasoning model, SARI (Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning), achieves a 16.35% improvement in average accuracy over the base model Qwen2-Audio-7B-Instruct. Furthermore, the variant built upon Qwen2.5-Omni reaches state-of-the-art performance of 67.08% on the MMAU test-mini benchmark. Ablation experiments show that on the base model we use: (i) SFT warm-up is important for stable RL training, (ii) structured chains yield more robust generalization than unstructured ones, and (iii) easy-to-hard curricula accelerate convergence and improve final performance. These findings demonstrate that explicit, structured reasoning and curriculum learning substantially enhances audio-language understanding.
MFH: A Multi-faceted Heuristic Algorithm Selection Approach for Software Verification
Mar 28, 2025Currently, many verification algorithms are available to improve the reliability of software systems. Selecting the appropriate verification algorithm typically demands domain expertise and non-trivial manpower. An automated algorithm selector is thus desired. However, existing selectors, either depend on machine-learned strategies or manually designed heuristics, encounter issues such as reliance on high-quality samples with algorithm labels and limited scalability. In this paper, an automated algorithm selection approach, namely MFH, is proposed for software verification. Our approach leverages the heuristics that verifiers producing correct results typically implement certain appropriate algorithms, and the supported algorithms by these verifiers indirectly reflect which ones are potentially applicable. Specifically, MFH embeds the code property graph (CPG) of a semantic-preserving transformed program to enhance the robustness of the prediction model. Furthermore, our approach decomposes the selection task into the sub-tasks of predicting potentially applicable algorithms and matching the most appropriate verifiers. Additionally, MFH also introduces a feedback loop on incorrect predictions to improve model prediction accuracy. We evaluate MFH on 20 verifiers and over 15,000 verification tasks. Experimental results demonstrate the effectiveness of MFH, achieving a prediction accuracy of 91.47% even without ground truth algorithm labels provided during the training phase. Moreover, the prediction accuracy decreases only by 0.84% when introducing 10 new verifiers, indicating the strong scalability of the proposed approach.
From Informal to Formal -- Incorporating and Evaluating LLMs on Natural Language Requirements to Verifiable Formal Proofs
Jan 27, 2025The research in AI-based formal mathematical reasoning has shown an unstoppable growth trend. These studies have excelled in mathematical competitions like IMO, showing significant progress. However, these studies intertwined multiple skills simultaneously, i.e., problem-solving, reasoning, and writing formal specifications, making it hard to precisely identify the LLMs' strengths and weaknesses in each task. This paper focuses on formal verification, an immediate application scenario of formal reasoning, and decomposes it into six sub-tasks. We constructed 18k high-quality instruction-response pairs across five mainstream formal specification languages (Coq, Lean4, Dafny, ACSL, and TLA+) in six formal-verification-related tasks by distilling GPT-4o. They are split into a 14k+ fine-tuning dataset FM-alpaca and a 4k benchmark FM-Bench. We found that LLMs are good at writing proof segments when given either the code, or the detailed description of proof steps. Also, the fine-tuning brought about a nearly threefold improvement at most. Interestingly, we observed that fine-tuning with formal data also enhances mathematics, reasoning, and coding abilities. We hope our findings inspire further research. Fine-tuned models are released to facilitate subsequent studies
ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
Jul 28, 2023



This paper presents the development and evaluation of ChatHome, a domain-specific language model (DSLM) designed for the intricate field of home renovation. Considering the proven competencies of large language models (LLMs) like GPT-4 and the escalating fascination with home renovation, this study endeavors to reconcile these aspects by generating a dedicated model that can yield high-fidelity, precise outputs relevant to the home renovation arena. ChatHome's novelty rests on its methodology, fusing domain-adaptive pretraining and instruction-tuning over an extensive dataset. This dataset includes professional articles, standard documents, and web content pertinent to home renovation. This dual-pronged strategy is designed to ensure that our model can assimilate comprehensive domain knowledge and effectively address user inquiries. Via thorough experimentation on diverse datasets, both universal and domain-specific, including the freshly introduced "EvalHome" domain dataset, we substantiate that ChatHome not only amplifies domain-specific functionalities but also preserves its versatility.
Patch-Wise Point Cloud Generation: A Divide-and-Conquer Approach
Jul 22, 2023



A generative model for high-fidelity point clouds is of great importance in synthesizing 3d environments for applications such as autonomous driving and robotics. Despite the recent success of deep generative models for 2d images, it is non-trivial to generate 3d point clouds without a comprehensive understanding of both local and global geometric structures. In this paper, we devise a new 3d point cloud generation framework using a divide-and-conquer approach, where the whole generation process can be divided into a set of patch-wise generation tasks. Specifically, all patch generators are based on learnable priors, which aim to capture the information of geometry primitives. We introduce point- and patch-wise transformers to enable the interactions between points and patches. Therefore, the proposed divide-and-conquer approach contributes to a new understanding of point cloud generation from the geometry constitution of 3d shapes. Experimental results on a variety of object categories from the most popular point cloud dataset, ShapeNet, show the effectiveness of the proposed patch-wise point cloud generation, where it clearly outperforms recent state-of-the-art methods for high-fidelity point cloud generation.
BPNet: Bézier Primitive Segmentation on 3D Point Clouds
Jul 08, 2023This paper proposes BPNet, a novel end-to-end deep learning framework to learn B\'ezier primitive segmentation on 3D point clouds. The existing works treat different primitive types separately, thus limiting them to finite shape categories. To address this issue, we seek a generalized primitive segmentation on point clouds. Taking inspiration from B\'ezier decomposition on NURBS models, we transfer it to guide point cloud segmentation casting off primitive types. A joint optimization framework is proposed to learn B\'ezier primitive segmentation and geometric fitting simultaneously on a cascaded architecture. Specifically, we introduce a soft voting regularizer to improve primitive segmentation and propose an auto-weight embedding module to cluster point features, making the network more robust and generic. We also introduce a reconstruction module where we successfully process multiple CAD models with different primitives simultaneously. We conducted extensive experiments on the synthetic ABC dataset and real-scan datasets to validate and compare our approach with different baseline methods. Experiments show superior performance over previous work in terms of segmentation, with a substantially faster inference speed.
PointWavelet: Learning in Spectral Domain for 3D Point Cloud Analysis
Feb 10, 2023With recent success of deep learning in 2D visual recognition, deep learning-based 3D point cloud analysis has received increasing attention from the community, especially due to the rapid development of autonomous driving technologies. However, most existing methods directly learn point features in the spatial domain, leaving the local structures in the spectral domain poorly investigated. In this paper, we introduce a new method, PointWavelet, to explore local graphs in the spectral domain via a learnable graph wavelet transform. Specifically, we first introduce the graph wavelet transform to form multi-scale spectral graph convolution to learn effective local structural representations. To avoid the time-consuming spectral decomposition, we then devise a learnable graph wavelet transform, which significantly accelerates the overall training process. Extensive experiments on four popular point cloud datasets, ModelNet40, ScanObjectNN, ShapeNet-Part, and S3DIS, demonstrate the effectiveness of the proposed method on point cloud classification and segmentation.
VITA: A Multi-Source Vicinal Transfer Augmentation Method for Out-of-Distribution Generalization
Apr 25, 2022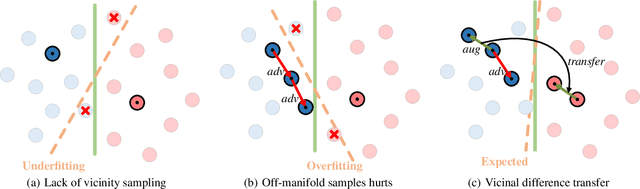
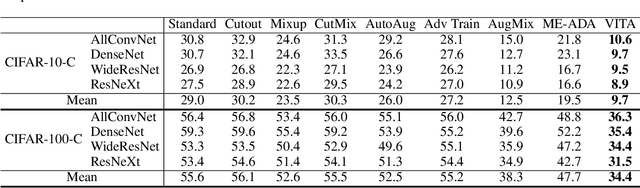
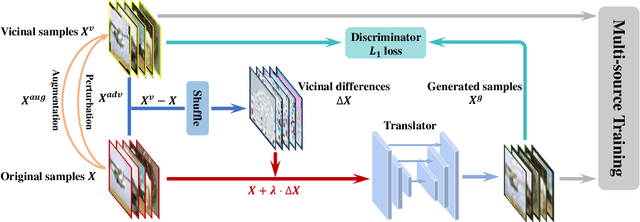
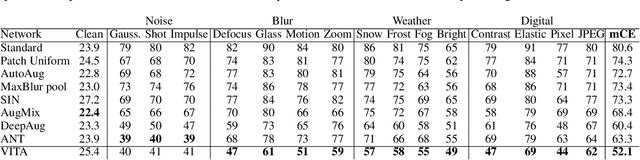
Invariance to diverse types of image corruption, such as noise, blurring, or colour shifts, is essential to establish robust models in computer vision. Data augmentation has been the major approach in improving the robustness against common corruptions. However, the samples produced by popular augmentation strategies deviate significantly from the underlying data manifold. As a result, performance is skewed toward certain types of corruption. To address this issue, we propose a multi-source vicinal transfer augmentation (VITA) method for generating diverse on-manifold samples. The proposed VITA consists of two complementary parts: tangent transfer and integration of multi-source vicinal samples. The tangent transfer creates initial augmented samples for improving corruption robustness. The integration employs a generative model to characterize the underlying manifold built by vicinal samples, facilitating the generation of on-manifold samples. Our proposed VITA significantly outperforms the current state-of-the-art augmentation methods, demonstrated in extensive experiments on corruption benchmarks.
Time Domain Adversarial Voice Conversion for ADD 2022
Apr 20, 2022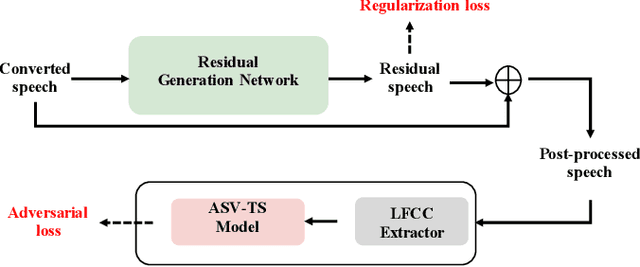

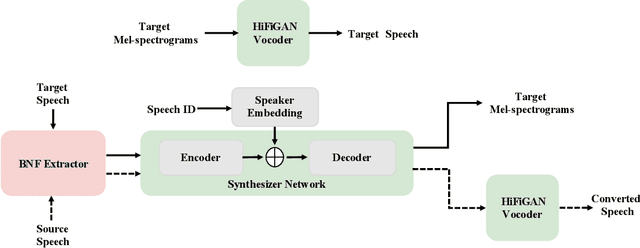
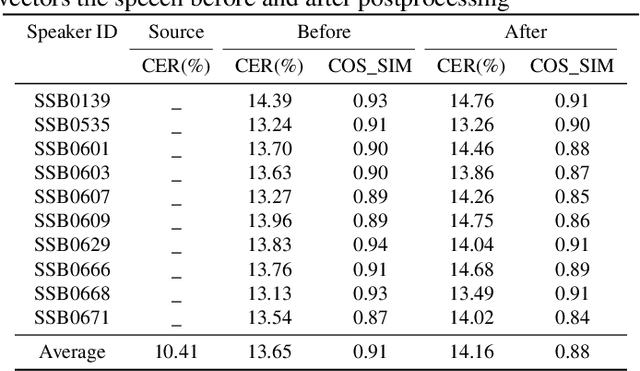
In this paper, we describe our speech generation system for the first Audio Deep Synthesis Detection Challenge (ADD 2022). Firstly, we build an any-to-many voice conversion (VC) system to convert source speech with arbitrary language content into the target speaker%u2019s fake speech. Then the converted speech generated from VC is post-processed in the time domain to improve the deception ability. The experimental results show that our system has adversarial ability against anti-spoofing detectors with a little compromise in audio quality and speaker similarity. This system ranks top in Track 3.1 in the ADD 2022, showing that our method could also gain good generalization ability against different detectors.