 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
Dec 31, 2025Traditional recommendation systems suffer from inconsistency in multi-stage optimization objectives. Generative Recommendation (GR) mitigates them through an end-to-end framework; however, existing methods still rely on matching mechanisms based on inductive patterns. Although responsive, they lack the ability to uncover complex user intents that require deductive reasoning based on world knowledge. Meanwhile, LLMs show strong deep reasoning capabilities, but their latency and computational costs remain challenging for industrial applications. More critically, there are performance bottlenecks in multi-scenario scalability: as shown in Figure 1, existing solutions require independent training and deployment for each scenario, leading to low resource utilization and high maintenance costs-a challenge unaddressed in GR literature. To address these, we present OxygenREC, an industrial recommendation system that leverages Fast-Slow Thinking to deliver deep reasoning with strict latency and multi-scenario requirements of real-world environments. First, we adopt a Fast-Slow Thinking architecture. Slow thinking uses a near-line LLM pipeline to synthesize Contextual Reasoning Instructions, while fast thinking employs a high-efficiency encoder-decoder backbone for real-time generation. Second, to ensure reasoning instructions effectively enhance recommendation generation, we introduce a semantic alignment mechanism with Instruction-Guided Retrieval (IGR) to filter intent-relevant historical behaviors and use a Query-to-Item (Q2I) loss for instruction-item consistency. Finally, to resolve multi-scenario scalability, we transform scenario information into controllable instructions, using unified reward mapping and Soft Adaptive Group Clip Policy Optimization (SA-GCPO) to align policies with diverse business objectives, realizing a train-once-deploy-everywhere paradigm.
Anatomical Region-Guided Contrastive Decoding: A Plug-and-Play Strategy for Mitigating Hallucinations in Medical VLMs
Dec 19, 2025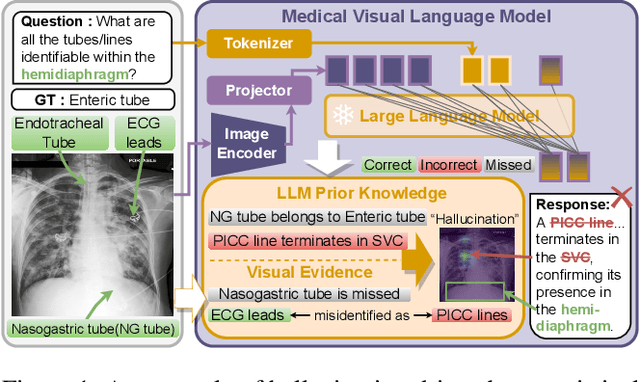
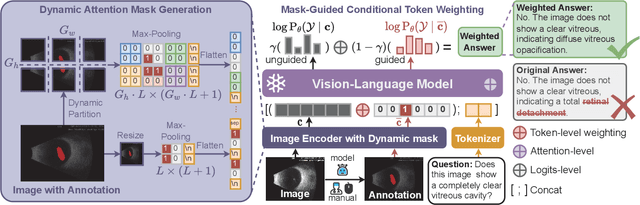

Medical Vision-Language Models (MedVLMs) show immense promise in clinical applicability. However, their reliability is hindered by hallucinations, where models often fail to derive answers from visual evidence, instead relying on learned textual priors. Existing mitigation strategies for MedVLMs have distinct limitations: training-based methods rely on costly expert annotations, limiting scalability, while training-free interventions like contrastive decoding, though data-efficient, apply a global, untargeted correction whose effects in complex real-world clinical settings can be unreliable. To address these challenges, we introduce Anatomical Region-Guided Contrastive Decoding (ARCD), a plug-and-play strategy that mitigates hallucinations by providing targeted, region-specific guidance. Our module leverages an anatomical mask to direct a three-tiered contrastive decoding process. By dynamically re-weighting at the token, attention, and logits levels, it verifiably steers the model's focus onto specified regions, reinforcing anatomical understanding and suppressing factually incorrect outputs. Extensive experiments across diverse datasets, including chest X-ray, CT, brain MRI, and ocular ultrasound, demonstrate our method's effectiveness in improving regional understanding, reducing hallucinations, and enhancing overall diagnostic accuracy.
CheXPO: Preference Optimization for Chest X-ray VLMs with Counterfactual Rationale
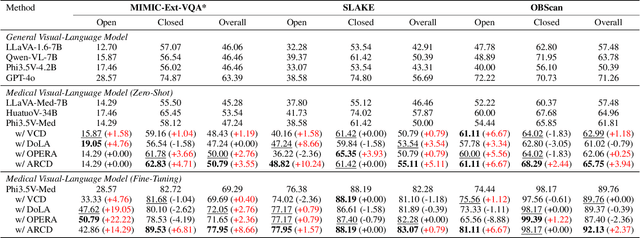
Jul 09, 2025Vision-language models (VLMs) are prone to hallucinations that critically compromise reliability in medical applications. While preference optimization can mitigate these hallucinations through clinical feedback, its implementation faces challenges such as clinically irrelevant training samples, imbalanced data distributions, and prohibitive expert annotation costs. To address these challenges, we introduce CheXPO, a Chest X-ray Preference Optimization strategy that combines confidence-similarity joint mining with counterfactual rationale. Our approach begins by synthesizing a unified, fine-grained multi-task chest X-ray visual instruction dataset across different question types for supervised fine-tuning (SFT). We then identify hard examples through token-level confidence analysis of SFT failures and use similarity-based retrieval to expand hard examples for balancing preference sample distributions, while synthetic counterfactual rationales provide fine-grained clinical preferences, eliminating the need for additional expert input. Experiments show that CheXPO achieves 8.93% relative performance gain using only 5% of SFT samples, reaching state-of-the-art performance across diverse clinical tasks and providing a scalable, interpretable solution for real-world radiology applications.
MFH: A Multi-faceted Heuristic Algorithm Selection Approach for Software Verification
Mar 28, 2025Currently, many verification algorithms are available to improve the reliability of software systems. Selecting the appropriate verification algorithm typically demands domain expertise and non-trivial manpower. An automated algorithm selector is thus desired. However, existing selectors, either depend on machine-learned strategies or manually designed heuristics, encounter issues such as reliance on high-quality samples with algorithm labels and limited scalability. In this paper, an automated algorithm selection approach, namely MFH, is proposed for software verification. Our approach leverages the heuristics that verifiers producing correct results typically implement certain appropriate algorithms, and the supported algorithms by these verifiers indirectly reflect which ones are potentially applicable. Specifically, MFH embeds the code property graph (CPG) of a semantic-preserving transformed program to enhance the robustness of the prediction model. Furthermore, our approach decomposes the selection task into the sub-tasks of predicting potentially applicable algorithms and matching the most appropriate verifiers. Additionally, MFH also introduces a feedback loop on incorrect predictions to improve model prediction accuracy. We evaluate MFH on 20 verifiers and over 15,000 verification tasks. Experimental results demonstrate the effectiveness of MFH, achieving a prediction accuracy of 91.47% even without ground truth algorithm labels provided during the training phase. Moreover, the prediction accuracy decreases only by 0.84% when introducing 10 new verifiers, indicating the strong scalability of the proposed approach.
AutoTestForge: A Multidimensional Automated Testing Framework for Natural Language Processing Models
Mar 07, 2025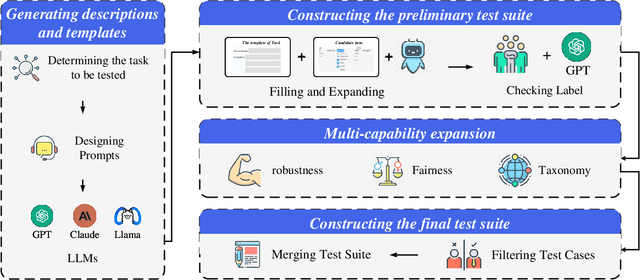
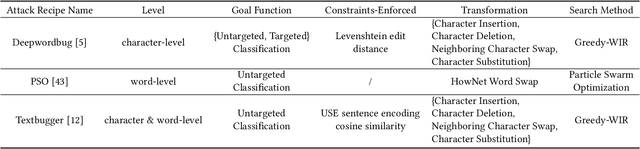

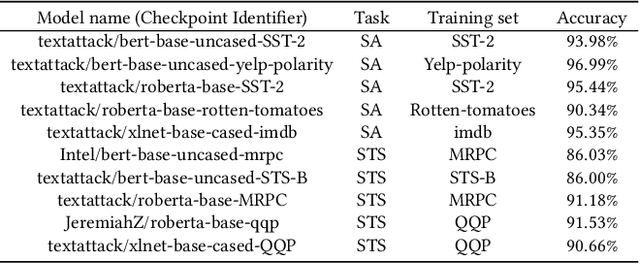
In recent years, the application of behavioral testing in Natural Language Processing (NLP) model evaluation has experienced a remarkable and substantial growth. However, the existing methods continue to be restricted by the requirements for manual labor and the limited scope of capability assessment. To address these limitations, we introduce AutoTestForge, an automated and multidimensional testing framework for NLP models in this paper. Within AutoTestForge, through the utilization of Large Language Models (LLMs) to automatically generate test templates and instantiate them, manual involvement is significantly reduced. Additionally, a mechanism for the validation of test case labels based on differential testing is implemented which makes use of a multi-model voting system to guarantee the quality of test cases. The framework also extends the test suite across three dimensions, taxonomy, fairness, and robustness, offering a comprehensive evaluation of the capabilities of NLP models. This expansion enables a more in-depth and thorough assessment of the models, providing valuable insights into their strengths and weaknesses. A comprehensive evaluation across sentiment analysis (SA) and semantic textual similarity (STS) tasks demonstrates that AutoTestForge consistently outperforms existing datasets and testing tools, achieving higher error detection rates (an average of $30.89\%$ for SA and $34.58\%$ for STS). Moreover, different generation strategies exhibit stable effectiveness, with error detection rates ranging from $29.03\% - 36.82\%$.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
A method for quantifying the generalization capabilities of generative models for solving Ising models
May 06, 2024For Ising models with complex energy landscapes, whether the ground state can be found by neural networks depends heavily on the Hamming distance between the training datasets and the ground state. Despite the fact that various recently proposed generative models have shown good performance in solving Ising models, there is no adequate discussion on how to quantify their generalization capabilities. Here we design a Hamming distance regularizer in the framework of a class of generative models, variational autoregressive networks (VAN), to quantify the generalization capabilities of various network architectures combined with VAN. The regularizer can control the size of the overlaps between the ground state and the training datasets generated by networks, which, together with the success rates of finding the ground state, form a quantitative metric to quantify their generalization capabilities. We conduct numerical experiments on several prototypical network architectures combined with VAN, including feed-forward neural networks, recurrent neural networks, and graph neural networks, to quantify their generalization capabilities when solving Ising models. Moreover, considering the fact that the quantification of the generalization capabilities of networks on small-scale problems can be used to predict their relative performance on large-scale problems, our method is of great significance for assisting in the Neural Architecture Search field of searching for the optimal network architectures when solving large-scale Ising models.
* 10 pages, 7 figures
Message Passing Variational Autoregressive Network for Solving Intractable Ising Models
Apr 09, 2024Many deep neural networks have been used to solve Ising models, including autoregressive neural networks, convolutional neural networks, recurrent neural networks, and graph neural networks. Learning a probability distribution of energy configuration or finding the ground states of a disordered, fully connected Ising model is essential for statistical mechanics and NP-hard problems. Despite tremendous efforts, a neural network architecture with the ability to high-accurately solve these fully connected and extremely intractable problems on larger systems is still lacking. Here we propose a variational autoregressive architecture with a message passing mechanism, which can effectively utilize the interactions between spin variables. The new network trained under an annealing framework outperforms existing methods in solving several prototypical Ising spin Hamiltonians, especially for larger spin systems at low temperatures. The advantages also come from the great mitigation of mode collapse during the training process of deep neural networks. Considering these extremely difficult problems to be solved, our method extends the current computational limits of unsupervised neural networks to solve combinatorial optimization problems.