 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Understanding Transformer from the Perspective of Associative Memory
May 26, 2025In this paper, we share our reflections and insights on understanding Transformer architectures through the lens of associative memory--a classic psychological concept inspired by human cognition. We start with the basics of associative memory (think simple linear attention) and then dive into two dimensions: Memory Capacity: How much can a Transformer really remember, and how well? We introduce retrieval SNR to measure this and use a kernel perspective to mathematically reveal why Softmax Attention is so effective. We also show how FFNs can be seen as a type of associative memory, leading to insights on their design and potential improvements. Memory Update: How do these memories learn and evolve? We present a unified framework for understanding how different Transformer variants (like DeltaNet and Softmax Attention) update their "knowledge base". This leads us to tackle two provocative questions: 1. Are Transformers fundamentally limited in what they can express, and can we break these barriers? 2. If a Transformer had infinite context, would it become infinitely intelligent? We want to demystify Transformer architecture, offering a clearer understanding of existing designs. This exploration aims to provide fresh insights and spark new avenues for Transformer innovation.
Amplify Adjacent Token Differences: Enhancing Long Chain-of-Thought Reasoning with Shift-FFN
May 22, 2025Recently, models such as OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable performance on complex reasoning tasks through Long Chain-of-Thought (Long-CoT) reasoning. Although distilling this capability into student models significantly enhances their performance, this paper finds that fine-tuning LLMs with full parameters or LoRA with a low rank on long CoT data often leads to Cyclical Reasoning, where models repeatedly reiterate previous inference steps until the maximum length limit. Further analysis reveals that smaller differences in representations between adjacent tokens correlates with a higher tendency toward Cyclical Reasoning. To mitigate this issue, this paper proposes Shift Feedforward Networks (Shift-FFN), a novel approach that edits the current token's representation with the previous one before inputting it to FFN. This architecture dynamically amplifies the representation differences between adjacent tokens. Extensive experiments on multiple mathematical reasoning tasks demonstrate that LoRA combined with Shift-FFN achieves higher accuracy and a lower rate of Cyclical Reasoning across various data sizes compared to full fine-tuning and standard LoRA. Our data and code are available at https://anonymous.4open.science/r/Shift-FFN
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
LongReD: Mitigating Short-Text Degradation of Long-Context Large Language Models via Restoration Distillation
Feb 11, 2025

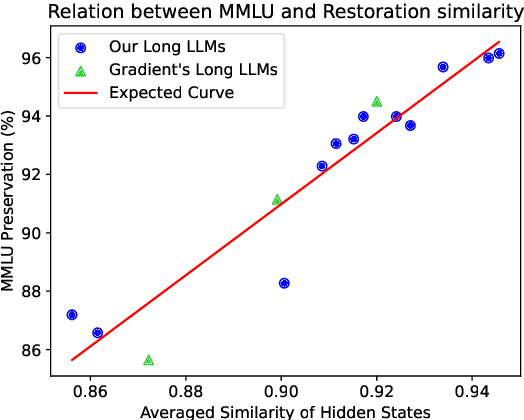

Large language models (LLMs) have gained extended context windows through scaling positional encodings and lightweight continual pre-training. However, this often leads to degraded performance on short-text tasks, while the reasons for this degradation remain insufficiently explored. In this work, we identify two primary factors contributing to this issue: distribution drift in hidden states and attention scores, and catastrophic forgetting during continual pre-training. To address these challenges, we propose Long Context Pre-training with Restoration Distillation (LongReD), a novel approach designed to mitigate short-text performance degradation through minimizing the distribution discrepancy between the extended and original models. Besides training on long texts, LongReD distills the hidden state of selected layers from the original model on short texts. Additionally, LongReD also introduces a short-to-long distillation, aligning the output distribution on short texts with that on long texts by leveraging skipped positional indices. Experiments on common text benchmarks demonstrate that LongReD effectively preserves the model's short-text performance while maintaining comparable or even better capacity to handle long texts than baselines.
KV Shifting Attention Enhances Language Modeling
Nov 29, 2024



The current large language models are mainly based on decode-only structure transformers, which have great in-context learning (ICL) capabilities. It is generally believed that the important foundation of its ICL capability is the induction heads mechanism, which requires at least two layers attention. In order to more efficiently implement the ability of the model's induction, we revisit the induction heads mechanism and proposed a KV shifting attention. We theoretically prove that the KV shifting attention reducing the model's requirements for the depth and width of the induction heads mechanism. Our experimental results demonstrate that KV shifting attention is beneficial to learning induction heads and language modeling, which lead to better performance or faster convergence from toy models to the pre-training models with more than 10 B parameters.
Class-balanced Open-set Semi-supervised Object Detection for Medical Images
Aug 22, 2024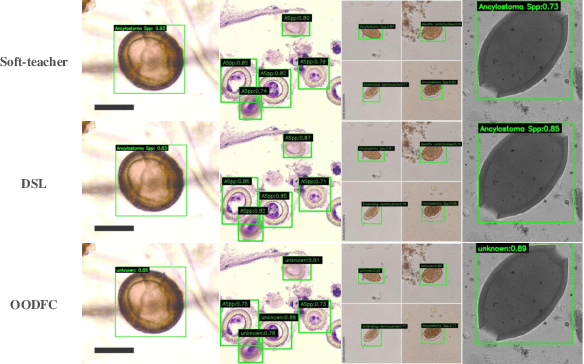
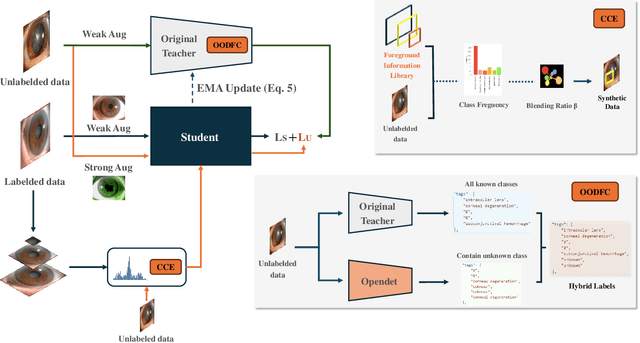
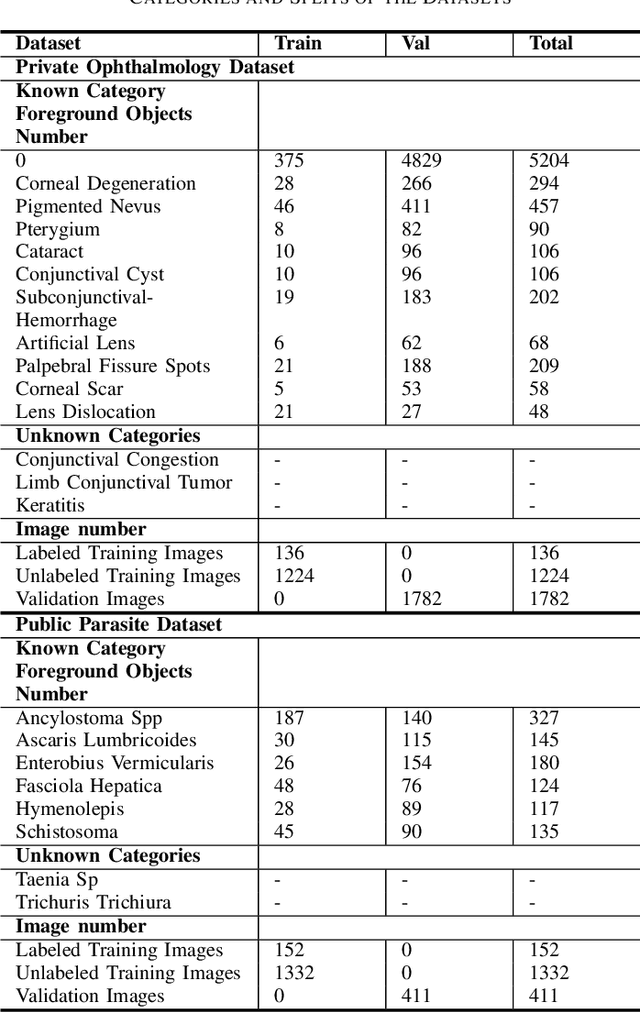
Medical image datasets in the real world are often unlabeled and imbalanced, and Semi-Supervised Object Detection (SSOD) can utilize unlabeled data to improve an object detector. However, existing approaches predominantly assumed that the unlabeled data and test data do not contain out-of-distribution (OOD) classes. The few open-set semi-supervised object detection methods have two weaknesses: first, the class imbalance is not considered; second, the OOD instances are distinguished and simply discarded during pseudo-labeling. In this paper, we consider the open-set semi-supervised object detection problem which leverages unlabeled data that contain OOD classes to improve object detection for medical images. Our study incorporates two key innovations: Category Control Embed (CCE) and out-of-distribution Detection Fusion Classifier (OODFC). CCE is designed to tackle dataset imbalance by constructing a Foreground information Library, while OODFC tackles open-set challenges by integrating the ``unknown'' information into basic pseudo-labels. Our method outperforms the state-of-the-art SSOD performance, achieving a 4.25 mAP improvement on the public Parasite dataset.
Base of RoPE Bounds Context Length
May 23, 2024



Position embedding is a core component of current Large Language Models (LLMs). Rotary position embedding (RoPE), a technique that encodes the position information with a rotation matrix, has been the de facto choice for position embedding in many LLMs, such as the Llama series. RoPE has been further utilized to extend long context capability, which is roughly based on adjusting the \textit{base} parameter of RoPE to mitigate out-of-distribution (OOD) problems in position embedding. However, in this paper, we find that LLMs may obtain a superficial long-context ability based on the OOD theory. We revisit the role of RoPE in LLMs and propose a novel property of long-term decay, we derive that the \textit{base of RoPE bounds context length}: there is an absolute lower bound for the base value to obtain certain context length capability. Our work reveals the relationship between context length and RoPE base both theoretically and empirically, which may shed light on future long context training.
Multimodal Fusion with Pre-Trained Model Features in Affective Behaviour Analysis In-the-wild
Mar 22, 2024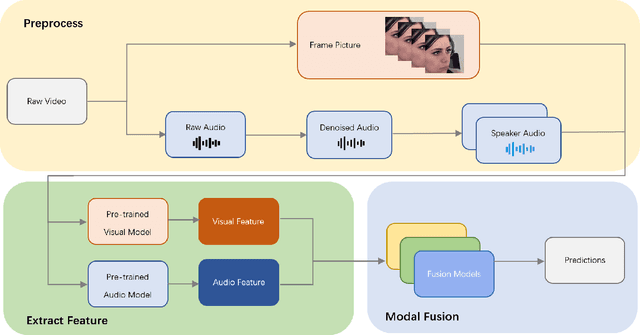
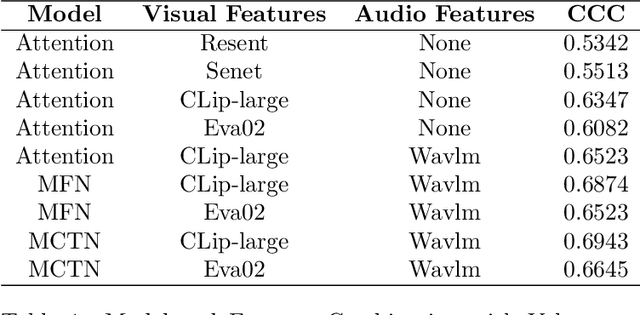

Multimodal fusion is a significant method for most multimodal tasks. With the recent surge in the number of large pre-trained models, combining both multimodal fusion methods and pre-trained model features can achieve outstanding performance in many multimodal tasks. In this paper, we present our approach, which leverages both advantages for addressing the task of Expression (Expr) Recognition and Valence-Arousal (VA) Estimation. We evaluate the Aff-Wild2 database using pre-trained models, then extract the final hidden layers of the models as features. Following preprocessing and interpolation or convolution to align the extracted features, different models are employed for modal fusion. Our code is available at GitHub - FulgenceWen/ABAW6th.