 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Decoding with CTC-based Draft Model for LLM Inference Acceleration
Nov 25, 2024



Inference acceleration of large language models (LLMs) has been put forward in many application scenarios and speculative decoding has shown its advantage in addressing inference acceleration. Speculative decoding usually introduces a draft model to assist the base LLM where the draft model produces drafts and the base LLM verifies the draft for acceptance or rejection. In this framework, the final inference speed is decided by the decoding speed of the draft model and the acceptance rate of the draft provided by the draft model. Currently the widely used draft models usually generate draft tokens for the next several positions in a non-autoregressive way without considering the correlations between draft tokens. Therefore, it has a high decoding speed but an unsatisfactory acceptance rate. In this paper, we focus on how to improve the performance of the draft model and aim to accelerate inference via a high acceptance rate. To this end, we propose a CTC-based draft model which strengthens the correlations between draft tokens during the draft phase, thereby generating higher-quality draft candidate sequences. Experiment results show that compared to strong baselines, the proposed method can achieve a higher acceptance rate and hence a faster inference speed.
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Apr 29, 2024



Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate labels), current systems still cannot meet the demands of practical applications. Therefore, we plan to organize a series of challenges around emotion recognition to further promote the development of this field. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
Multimodal Fusion with Pre-Trained Model Features in Affective Behaviour Analysis In-the-wild
Mar 22, 2024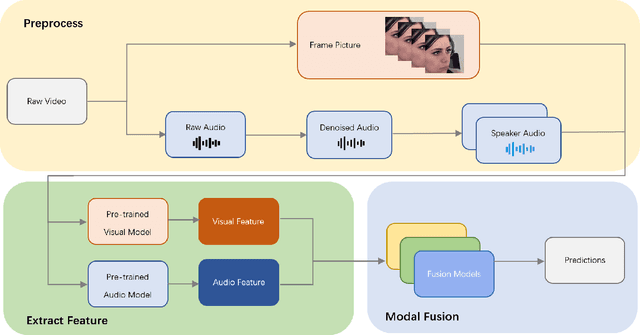
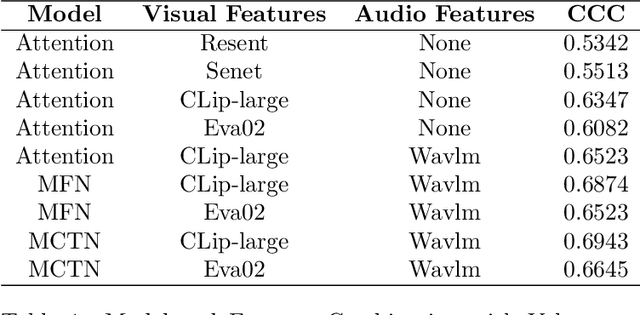

Multimodal fusion is a significant method for most multimodal tasks. With the recent surge in the number of large pre-trained models, combining both multimodal fusion methods and pre-trained model features can achieve outstanding performance in many multimodal tasks. In this paper, we present our approach, which leverages both advantages for addressing the task of Expression (Expr) Recognition and Valence-Arousal (VA) Estimation. We evaluate the Aff-Wild2 database using pre-trained models, then extract the final hidden layers of the models as features. Following preprocessing and interpolation or convolution to align the extracted features, different models are employed for modal fusion. Our code is available at GitHub - FulgenceWen/ABAW6th.
GPT-4V with Emotion: A Zero-shot Benchmark for Multimodal Emotion Understanding
Dec 07, 2023



Recently, GPT-4 with Vision (GPT-4V) has shown remarkable performance across various multimodal tasks. However, its efficacy in emotion recognition remains a question. This paper quantitatively evaluates GPT-4V's capabilities in multimodal emotion understanding, encompassing tasks such as facial emotion recognition, visual sentiment analysis, micro-expression recognition, dynamic facial emotion recognition, and multimodal emotion recognition. Our experiments show that GPT-4V exhibits impressive multimodal and temporal understanding capabilities, even surpassing supervised systems in some tasks. Despite these achievements, GPT-4V is currently tailored for general domains. It performs poorly in micro-expression recognition that requires specialized expertise. The main purpose of this paper is to present quantitative results of GPT-4V on emotion understanding and establish a zero-shot benchmark for future research. Code and evaluation results are available at: https://github.com/zeroQiaoba/gpt4v-emotion.