 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Decoding with CTC-based Draft Model for LLM Inference Acceleration
Nov 25, 2024



Inference acceleration of large language models (LLMs) has been put forward in many application scenarios and speculative decoding has shown its advantage in addressing inference acceleration. Speculative decoding usually introduces a draft model to assist the base LLM where the draft model produces drafts and the base LLM verifies the draft for acceptance or rejection. In this framework, the final inference speed is decided by the decoding speed of the draft model and the acceptance rate of the draft provided by the draft model. Currently the widely used draft models usually generate draft tokens for the next several positions in a non-autoregressive way without considering the correlations between draft tokens. Therefore, it has a high decoding speed but an unsatisfactory acceptance rate. In this paper, we focus on how to improve the performance of the draft model and aim to accelerate inference via a high acceptance rate. To this end, we propose a CTC-based draft model which strengthens the correlations between draft tokens during the draft phase, thereby generating higher-quality draft candidate sequences. Experiment results show that compared to strong baselines, the proposed method can achieve a higher acceptance rate and hence a faster inference speed.
Non-autoregressive Machine Translation with Probabilistic Context-free Grammar
Nov 14, 2023



Non-autoregressive Transformer(NAT) significantly accelerates the inference of neural machine translation. However, conventional NAT models suffer from limited expression power and performance degradation compared to autoregressive (AT) models due to the assumption of conditional independence among target tokens. To address these limitations, we propose a novel approach called PCFG-NAT, which leverages a specially designed Probabilistic Context-Free Grammar (PCFG) to enhance the ability of NAT models to capture complex dependencies among output tokens. Experimental results on major machine translation benchmarks demonstrate that PCFG-NAT further narrows the gap in translation quality between NAT and AT models. Moreover, PCFG-NAT facilitates a deeper understanding of the generated sentences, addressing the lack of satisfactory explainability in neural machine translation.Code is publicly available at https://github.com/ictnlp/PCFG-NAT.
BayLing: Bridging Cross-lingual Alignment and Instruction Following through Interactive Translation for Large Language Models
Jun 21, 2023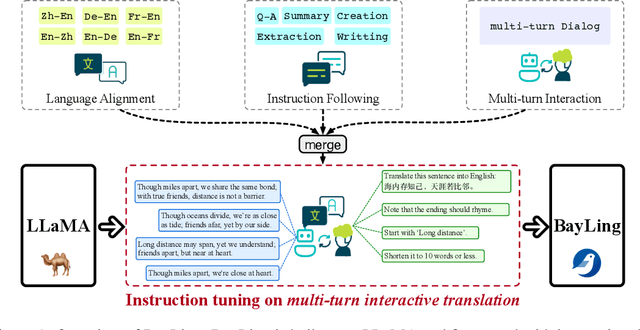
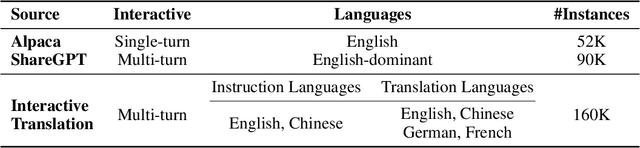

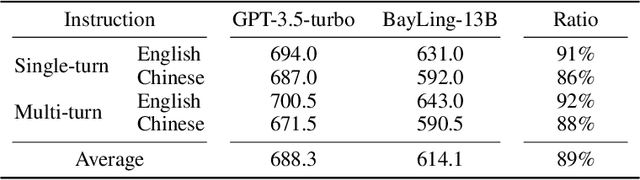
Large language models (LLMs) have demonstrated remarkable prowess in language understanding and generation. Advancing from foundation LLMs to instructionfollowing LLMs, instruction tuning plays a vital role in aligning LLMs to human preferences. However, the existing LLMs are usually focused on English, leading to inferior performance in non-English languages. In order to improve the performance for non-English languages, it is necessary to collect language-specific training data for foundation LLMs and construct language-specific instructions for instruction tuning, both of which are heavy loads. To minimize human workload, we propose to transfer the capabilities of language generation and instruction following from English to other languages through an interactive translation task. We have developed BayLing, an instruction-following LLM by utilizing LLaMA as the foundation LLM and automatically constructing interactive translation instructions for instructing tuning. Extensive assessments demonstrate that BayLing achieves comparable performance to GPT-3.5-turbo, despite utilizing a considerably smaller parameter size of only 13 billion. Experimental results on translation tasks show that BayLing achieves 95% of single-turn translation capability compared to GPT-4 with automatic evaluation and 96% of interactive translation capability compared to GPT-3.5-turbo with human evaluation. To estimate the performance on general tasks, we created a multi-turn instruction test set called BayLing-80. The experimental results on BayLing-80 indicate that BayLing achieves 89% of performance compared to GPT-3.5-turbo. BayLing also demonstrates outstanding performance on knowledge assessment of Chinese GaoKao and English SAT, second only to GPT-3.5-turbo among a multitude of instruction-following LLMs. Demo, homepage, code and models of BayLing are available.
Fuzzy Alignments in Directed Acyclic Graph for Non-Autoregressive Machine Translation
Mar 12, 2023Non-autoregressive translation (NAT) reduces the decoding latency but suffers from performance degradation due to the multi-modality problem. Recently, the structure of directed acyclic graph has achieved great success in NAT, which tackles the multi-modality problem by introducing dependency between vertices. However, training it with negative log-likelihood loss implicitly requires a strict alignment between reference tokens and vertices, weakening its ability to handle multiple translation modalities. In this paper, we hold the view that all paths in the graph are fuzzily aligned with the reference sentence. We do not require the exact alignment but train the model to maximize a fuzzy alignment score between the graph and reference, which takes captured translations in all modalities into account. Extensive experiments on major WMT benchmarks show that our method substantially improves translation performance and increases prediction confidence, setting a new state of the art for NAT on the raw training data.