 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStream-Omni: Simultaneous Multimodal Interactions with Large Language-Vision-Speech Model
Jun 16, 2025The emergence of GPT-4o-like large multimodal models (LMMs) has raised the exploration of integrating text, vision, and speech modalities to support more flexible multimodal interaction. Existing LMMs typically concatenate representation of modalities along the sequence dimension and feed them into a large language model (LLM) backbone. While sequence-dimension concatenation is straightforward for modality integration, it often relies heavily on large-scale data to learn modality alignments. In this paper, we aim to model the relationships between modalities more purposefully, thereby achieving more efficient and flexible modality alignments. To this end, we propose Stream-Omni, a large language-vision-speech model with efficient modality alignments, which can simultaneously support interactions under various modality combinations. Stream-Omni employs LLM as the backbone and aligns the vision and speech to the text based on their relationships. For vision that is semantically complementary to text, Stream-Omni uses sequence-dimension concatenation to achieve vision-text alignment. For speech that is semantically consistent with text, Stream-Omni introduces a CTC-based layer-dimension mapping to achieve speech-text alignment. In this way, Stream-Omni can achieve modality alignments with less data (especially speech), enabling the transfer of text capabilities to other modalities. Experiments on various benchmarks demonstrate that Stream-Omni achieves strong performance on visual understanding, speech interaction, and vision-grounded speech interaction tasks. Owing to the layer-dimensional mapping, Stream-Omni can simultaneously provide intermediate text outputs (such as ASR transcriptions and model responses) during speech interaction, offering users a comprehensive multimodal experience.
LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
May 05, 2025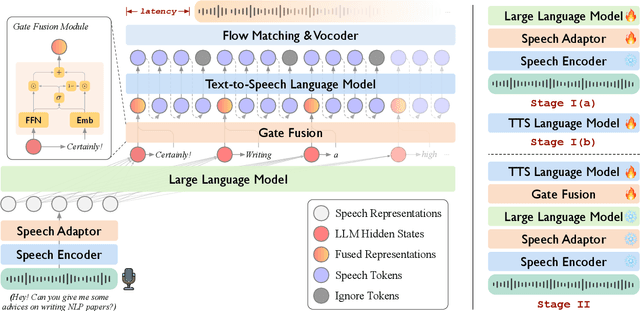
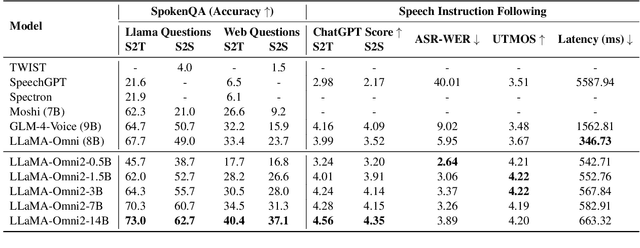
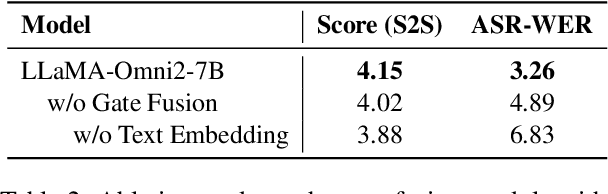
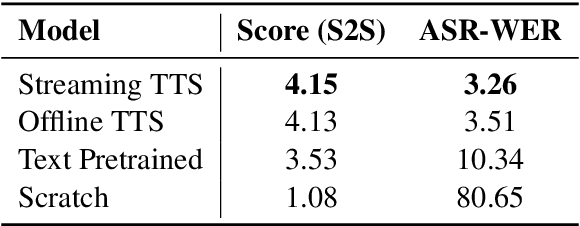
Real-time, intelligent, and natural speech interaction is an essential part of the next-generation human-computer interaction. Recent advancements have showcased the potential of building intelligent spoken chatbots based on large language models (LLMs). In this paper, we introduce LLaMA-Omni 2, a series of speech language models (SpeechLMs) ranging from 0.5B to 14B parameters, capable of achieving high-quality real-time speech interaction. LLaMA-Omni 2 is built upon the Qwen2.5 series models, integrating a speech encoder and an autoregressive streaming speech decoder. Despite being trained on only 200K multi-turn speech dialogue samples, LLaMA-Omni 2 demonstrates strong performance on several spoken question answering and speech instruction following benchmarks, surpassing previous state-of-the-art SpeechLMs like GLM-4-Voice, which was trained on millions of hours of speech data.
LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
Jan 07, 2025



The advent of real-time large multimodal models (LMMs) like GPT-4o has sparked considerable interest in efficient LMMs. LMM frameworks typically encode visual inputs into vision tokens (continuous representations) and integrate them and textual instructions into the context of large language models (LLMs), where large-scale parameters and numerous context tokens (predominantly vision tokens) result in substantial computational overhead. Previous efforts towards efficient LMMs always focus on replacing the LLM backbone with smaller models, while neglecting the crucial issue of token quantity. In this paper, we introduce LLaVA-Mini, an efficient LMM with minimal vision tokens. To achieve a high compression ratio of vision tokens while preserving visual information, we first analyze how LMMs understand vision tokens and find that most vision tokens only play a crucial role in the early layers of LLM backbone, where they mainly fuse visual information into text tokens. Building on this finding, LLaVA-Mini introduces modality pre-fusion to fuse visual information into text tokens in advance, thereby facilitating the extreme compression of vision tokens fed to LLM backbone into one token. LLaVA-Mini is a unified large multimodal model that can support the understanding of images, high-resolution images, and videos in an efficient manner. Experiments across 11 image-based and 7 video-based benchmarks demonstrate that LLaVA-Mini outperforms LLaVA-v1.5 with just 1 vision token instead of 576. Efficiency analyses reveal that LLaVA-Mini can reduce FLOPs by 77%, deliver low-latency responses within 40 milliseconds, and process over 10,000 frames of video on the GPU hardware with 24GB of memory.
BayLing 2: A Multilingual Large Language Model with Efficient Language Alignment
Nov 25, 2024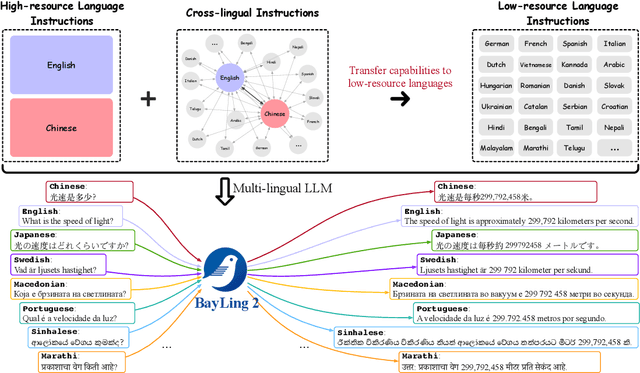


Large language models (LLMs), with their powerful generative capabilities and vast knowledge, empower various tasks in everyday life. However, these abilities are primarily concentrated in high-resource languages, leaving low-resource languages with weaker generative capabilities and relatively limited knowledge. Enhancing the multilingual capabilities of LLMs is therefore crucial for serving over 100 linguistic communities worldwide. An intuitive approach to enhance the multilingual capabilities would be to construct instruction data for various languages, but constructing instruction data for over 100 languages is prohibitively costly. In this paper, we introduce BayLing 2, which efficiently transfers generative capabilities and knowledge from high-resource languages to low-resource languages through language alignment. To achieve this, we constructed a dataset of 3.2 million instructions, comprising high-resource language instructions (Chinese and English) and cross-lingual instructions for 100+ languages and performed instruction tuning based on the dataset to facilitate the capability transfer between languages. Using Llama as the foundation model, we developed BayLing-2-7B, BayLing-2-13B, and BayLing-3-8B, and conducted a comprehensive evaluation of BayLing. For multilingual translation across 100+ languages, BayLing shows superior performance compared to open-source models of similar scale. For multilingual knowledge and understanding benchmarks, BayLing achieves significant improvements across over 20 low-resource languages, demonstrating its capability of effective knowledge transfer from high-resource to low-resource languages. Furthermore, results on English benchmarks indicate that BayLing maintains high performance in highresource languages while enhancing the performance in low-resource languages. Demo, homepage, code and models of BayLing are available.
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Sep 10, 2024



Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech interaction models based on open-source LLMs. To address this, we propose LLaMA-Omni, a novel model architecture designed for low-latency and high-quality speech interaction with LLMs. LLaMA-Omni integrates a pretrained speech encoder, a speech adaptor, an LLM, and a streaming speech decoder. It eliminates the need for speech transcription, and can simultaneously generate text and speech responses directly from speech instructions with extremely low latency. We build our model based on the latest Llama-3.1-8B-Instruct model. To align the model with speech interaction scenarios, we construct a dataset named InstructS2S-200K, which includes 200K speech instructions and corresponding speech responses. Experimental results show that compared to previous speech-language models, LLaMA-Omni provides better responses in both content and style, with a response latency as low as 226ms. Additionally, training LLaMA-Omni takes less than 3 days on just 4 GPUs, paving the way for the efficient development of speech-language models in the future.
CTC-based Non-autoregressive Textless Speech-to-Speech Translation
Jun 11, 2024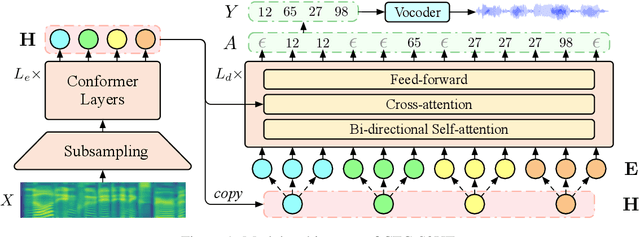
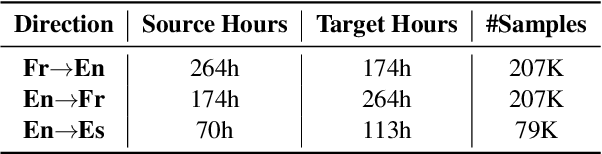

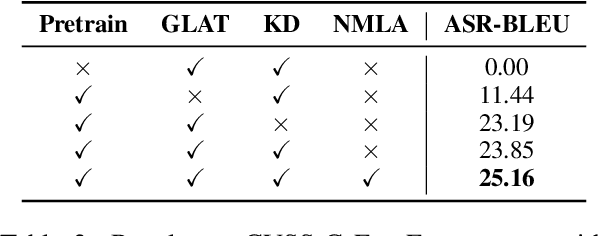
Direct speech-to-speech translation (S2ST) has achieved impressive translation quality, but it often faces the challenge of slow decoding due to the considerable length of speech sequences. Recently, some research has turned to non-autoregressive (NAR) models to expedite decoding, yet the translation quality typically lags behind autoregressive (AR) models significantly. In this paper, we investigate the performance of CTC-based NAR models in S2ST, as these models have shown impressive results in machine translation. Experimental results demonstrate that by combining pretraining, knowledge distillation, and advanced NAR training techniques such as glancing training and non-monotonic latent alignments, CTC-based NAR models achieve translation quality comparable to the AR model, while preserving up to 26.81$\times$ decoding speedup.
A Non-autoregressive Generation Framework for End-to-End Simultaneous Speech-to-Any Translation
Jun 11, 2024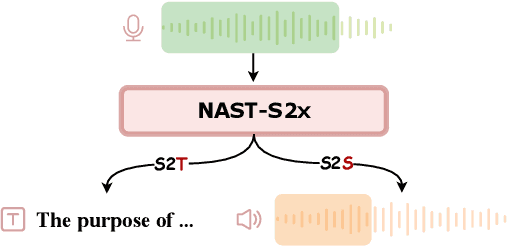



Simultaneous translation models play a crucial role in facilitating communication. However, existing research primarily focuses on text-to-text or speech-to-text models, necessitating additional cascade components to achieve speech-to-speech translation. These pipeline methods suffer from error propagation and accumulate delays in each cascade component, resulting in reduced synchronization between the speaker and listener. To overcome these challenges, we propose a novel non-autoregressive generation framework for simultaneous speech translation (NAST-S2X), which integrates speech-to-text and speech-to-speech tasks into a unified end-to-end framework. We develop a non-autoregressive decoder capable of concurrently generating multiple text or acoustic unit tokens upon receiving fixed-length speech chunks. The decoder can generate blank or repeated tokens and employ CTC decoding to dynamically adjust its latency. Experimental results show that NAST-S2X outperforms state-of-the-art models in both speech-to-text and speech-to-speech tasks. It achieves high-quality simultaneous interpretation within a delay of less than 3 seconds and provides a 28 times decoding speedup in offline generation.
Can We Achieve High-quality Direct Speech-to-Speech Translation without Parallel Speech Data?
Jun 11, 2024Recently proposed two-pass direct speech-to-speech translation (S2ST) models decompose the task into speech-to-text translation (S2TT) and text-to-speech (TTS) within an end-to-end model, yielding promising results. However, the training of these models still relies on parallel speech data, which is extremely challenging to collect. In contrast, S2TT and TTS have accumulated a large amount of data and pretrained models, which have not been fully utilized in the development of S2ST models. Inspired by this, in this paper, we first introduce a composite S2ST model named ComSpeech, which can seamlessly integrate any pretrained S2TT and TTS models into a direct S2ST model. Furthermore, to eliminate the reliance on parallel speech data, we propose a novel training method ComSpeech-ZS that solely utilizes S2TT and TTS data. It aligns representations in the latent space through contrastive learning, enabling the speech synthesis capability learned from the TTS data to generalize to S2ST in a zero-shot manner. Experimental results on the CVSS dataset show that when the parallel speech data is available, ComSpeech surpasses previous two-pass models like UnitY and Translatotron 2 in both translation quality and decoding speed. When there is no parallel speech data, ComSpeech-ZS lags behind \name by only 0.7 ASR-BLEU and outperforms the cascaded models.
StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning
Jun 05, 2024Simultaneous speech-to-speech translation (Simul-S2ST, a.k.a streaming speech translation) outputs target speech while receiving streaming speech inputs, which is critical for real-time communication. Beyond accomplishing translation between speech, Simul-S2ST requires a policy to control the model to generate corresponding target speech at the opportune moment within speech inputs, thereby posing a double challenge of translation and policy. In this paper, we propose StreamSpeech, a direct Simul-S2ST model that jointly learns translation and simultaneous policy in a unified framework of multi-task learning. Adhering to a multi-task learning approach, StreamSpeech can perform offline and simultaneous speech recognition, speech translation and speech synthesis via an "All-in-One" seamless model. Experiments on CVSS benchmark demonstrate that StreamSpeech achieves state-of-the-art performance in both offline S2ST and Simul-S2ST tasks. Besides, StreamSpeech is able to present high-quality intermediate results (i.e., ASR or translation results) during simultaneous translation process, offering a more comprehensive real-time communication experience.
Bridging the Gap between Synthetic and Authentic Images for Multimodal Machine Translation
Oct 20, 2023



Multimodal machine translation (MMT) simultaneously takes the source sentence and a relevant image as input for translation. Since there is no paired image available for the input sentence in most cases, recent studies suggest utilizing powerful text-to-image generation models to provide image inputs. Nevertheless, synthetic images generated by these models often follow different distributions compared to authentic images. Consequently, using authentic images for training and synthetic images for inference can introduce a distribution shift, resulting in performance degradation during inference. To tackle this challenge, in this paper, we feed synthetic and authentic images to the MMT model, respectively. Then we minimize the gap between the synthetic and authentic images by drawing close the input image representations of the Transformer Encoder and the output distributions of the Transformer Decoder. Therefore, we mitigate the distribution disparity introduced by the synthetic images during inference, thereby freeing the authentic images from the inference process.Experimental results show that our approach achieves state-of-the-art performance on the Multi30K En-De and En-Fr datasets, while remaining independent of authentic images during inference.