 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamUni: Achieving Streaming Speech Translation with a Unified Large Speech-Language Model
Jul 10, 2025Streaming speech translation (StreamST) requires determining appropriate timing, known as policy, to generate translations while continuously receiving source speech inputs, balancing low latency with high translation quality. However, existing StreamST methods typically operate on sentence-level speech segments, referred to as simultaneous speech translation (SimulST). In practice, they require collaboration with segmentation models to accomplish StreamST, where the truncated speech segments constrain SimulST models to make policy decisions and generate translations based on limited contextual information. Moreover, SimulST models struggle to learn effective policies due to the complexity of speech inputs and cross-lingual generation. To address these challenges, we propose StreamUni, which achieves StreamST through a unified Large Speech-Language Model (LSLM). Specifically, StreamUni incorporates speech Chain-of-Thought (CoT) in guiding the LSLM to generate multi-stage outputs. Leveraging these multi-stage outputs, StreamUni simultaneously accomplishes speech segmentation, policy decision, and translation generation, completing StreamST without requiring massive policy-specific training. Additionally, we propose a streaming CoT training method that enhances low-latency policy decisions and generation capabilities using limited CoT data. Experiments demonstrate that our approach achieves state-of-the-art performance on StreamST tasks.
Stream-Omni: Simultaneous Multimodal Interactions with Large Language-Vision-Speech Model
Jun 16, 2025The emergence of GPT-4o-like large multimodal models (LMMs) has raised the exploration of integrating text, vision, and speech modalities to support more flexible multimodal interaction. Existing LMMs typically concatenate representation of modalities along the sequence dimension and feed them into a large language model (LLM) backbone. While sequence-dimension concatenation is straightforward for modality integration, it often relies heavily on large-scale data to learn modality alignments. In this paper, we aim to model the relationships between modalities more purposefully, thereby achieving more efficient and flexible modality alignments. To this end, we propose Stream-Omni, a large language-vision-speech model with efficient modality alignments, which can simultaneously support interactions under various modality combinations. Stream-Omni employs LLM as the backbone and aligns the vision and speech to the text based on their relationships. For vision that is semantically complementary to text, Stream-Omni uses sequence-dimension concatenation to achieve vision-text alignment. For speech that is semantically consistent with text, Stream-Omni introduces a CTC-based layer-dimension mapping to achieve speech-text alignment. In this way, Stream-Omni can achieve modality alignments with less data (especially speech), enabling the transfer of text capabilities to other modalities. Experiments on various benchmarks demonstrate that Stream-Omni achieves strong performance on visual understanding, speech interaction, and vision-grounded speech interaction tasks. Owing to the layer-dimensional mapping, Stream-Omni can simultaneously provide intermediate text outputs (such as ASR transcriptions and model responses) during speech interaction, offering users a comprehensive multimodal experience.
LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
May 05, 2025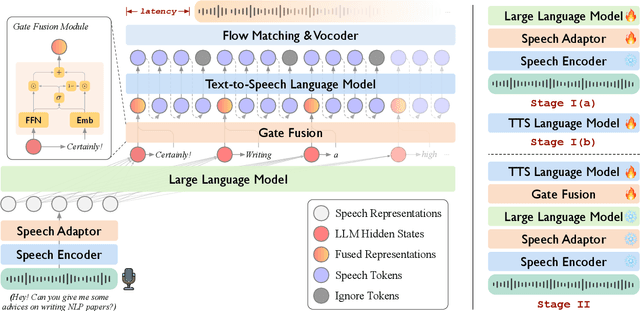
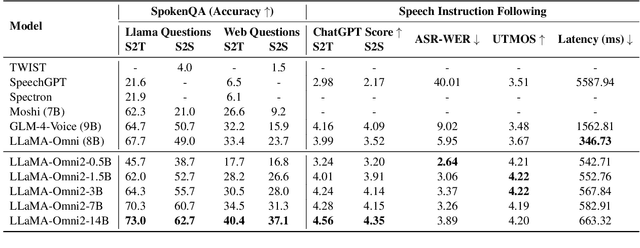
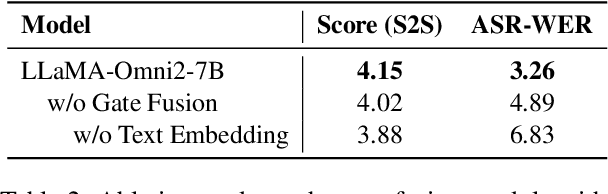
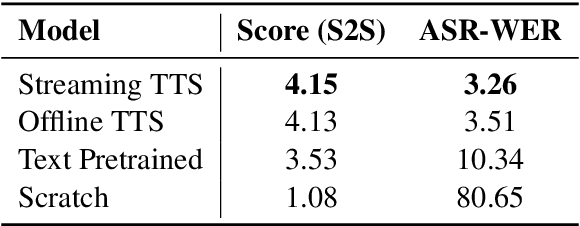
Real-time, intelligent, and natural speech interaction is an essential part of the next-generation human-computer interaction. Recent advancements have showcased the potential of building intelligent spoken chatbots based on large language models (LLMs). In this paper, we introduce LLaMA-Omni 2, a series of speech language models (SpeechLMs) ranging from 0.5B to 14B parameters, capable of achieving high-quality real-time speech interaction. LLaMA-Omni 2 is built upon the Qwen2.5 series models, integrating a speech encoder and an autoregressive streaming speech decoder. Despite being trained on only 200K multi-turn speech dialogue samples, LLaMA-Omni 2 demonstrates strong performance on several spoken question answering and speech instruction following benchmarks, surpassing previous state-of-the-art SpeechLMs like GLM-4-Voice, which was trained on millions of hours of speech data.
Large Language Models Are Read/Write Policy-Makers for Simultaneous Generation
Jan 01, 2025



Simultaneous generation models write generation results while reading streaming inputs, necessitating a policy-maker to determine the appropriate output timing. Existing simultaneous generation methods generally adopt the traditional encoder-decoder architecture and learn the generation and policy-making capabilities through complex dynamic programming techniques. Although LLMs excel at text generation, they face challenges in taking on the role of policy-makers through traditional training methods, limiting their exploration in simultaneous generation. To overcome these limitations, we propose a novel LLM-driven Simultaneous Generation (LSG) framework, which allows the off-the-shelf LLM to decide the generation timing and produce output concurrently. Specifically, LSG selects the generation policy that minimizes latency as the baseline policy. Referring to the baseline policy, LSG enables the LLM to devise an improved generation policy that better balances latency and generation quality, and writes generation results accordingly. Experiments on simultaneous translation and streaming automatic speech recognition tasks show that our method can achieve state-of-the-art performance utilizing the open-source LLMs and demonstrate practicality in real-world scenarios.
BayLing 2: A Multilingual Large Language Model with Efficient Language Alignment
Nov 25, 2024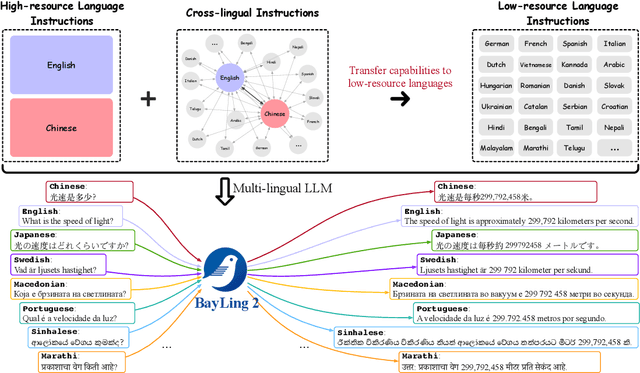


Large language models (LLMs), with their powerful generative capabilities and vast knowledge, empower various tasks in everyday life. However, these abilities are primarily concentrated in high-resource languages, leaving low-resource languages with weaker generative capabilities and relatively limited knowledge. Enhancing the multilingual capabilities of LLMs is therefore crucial for serving over 100 linguistic communities worldwide. An intuitive approach to enhance the multilingual capabilities would be to construct instruction data for various languages, but constructing instruction data for over 100 languages is prohibitively costly. In this paper, we introduce BayLing 2, which efficiently transfers generative capabilities and knowledge from high-resource languages to low-resource languages through language alignment. To achieve this, we constructed a dataset of 3.2 million instructions, comprising high-resource language instructions (Chinese and English) and cross-lingual instructions for 100+ languages and performed instruction tuning based on the dataset to facilitate the capability transfer between languages. Using Llama as the foundation model, we developed BayLing-2-7B, BayLing-2-13B, and BayLing-3-8B, and conducted a comprehensive evaluation of BayLing. For multilingual translation across 100+ languages, BayLing shows superior performance compared to open-source models of similar scale. For multilingual knowledge and understanding benchmarks, BayLing achieves significant improvements across over 20 low-resource languages, demonstrating its capability of effective knowledge transfer from high-resource to low-resource languages. Furthermore, results on English benchmarks indicate that BayLing maintains high performance in highresource languages while enhancing the performance in low-resource languages. Demo, homepage, code and models of BayLing are available.
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Sep 10, 2024



Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech interaction models based on open-source LLMs. To address this, we propose LLaMA-Omni, a novel model architecture designed for low-latency and high-quality speech interaction with LLMs. LLaMA-Omni integrates a pretrained speech encoder, a speech adaptor, an LLM, and a streaming speech decoder. It eliminates the need for speech transcription, and can simultaneously generate text and speech responses directly from speech instructions with extremely low latency. We build our model based on the latest Llama-3.1-8B-Instruct model. To align the model with speech interaction scenarios, we construct a dataset named InstructS2S-200K, which includes 200K speech instructions and corresponding speech responses. Experimental results show that compared to previous speech-language models, LLaMA-Omni provides better responses in both content and style, with a response latency as low as 226ms. Additionally, training LLaMA-Omni takes less than 3 days on just 4 GPUs, paving the way for the efficient development of speech-language models in the future.
Agent-SiMT: Agent-assisted Simultaneous Machine Translation with Large Language Models
Jun 12, 2024Simultaneous Machine Translation (SiMT) generates target translations while reading the source sentence. It relies on a policy to determine the optimal timing for reading sentences and generating translations. Existing SiMT methods generally adopt the traditional Transformer architecture, which concurrently determines the policy and generates translations. While they excel at determining policies, their translation performance is suboptimal. Conversely, Large Language Models (LLMs), trained on extensive corpora, possess superior generation capabilities, but it is difficult for them to acquire translation policy through the training methods of SiMT. Therefore, we introduce Agent-SiMT, a framework combining the strengths of LLMs and traditional SiMT methods. Agent-SiMT contains the policy-decision agent and the translation agent. The policy-decision agent is managed by a SiMT model, which determines the translation policy using partial source sentence and translation. The translation agent, leveraging an LLM, generates translation based on the partial source sentence. The two agents collaborate to accomplish SiMT. Experiments demonstrate that Agent-SiMT attains state-of-the-art performance.
A Non-autoregressive Generation Framework for End-to-End Simultaneous Speech-to-Any Translation
Jun 11, 2024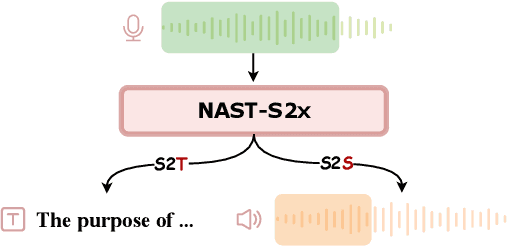



Simultaneous translation models play a crucial role in facilitating communication. However, existing research primarily focuses on text-to-text or speech-to-text models, necessitating additional cascade components to achieve speech-to-speech translation. These pipeline methods suffer from error propagation and accumulate delays in each cascade component, resulting in reduced synchronization between the speaker and listener. To overcome these challenges, we propose a novel non-autoregressive generation framework for simultaneous speech translation (NAST-S2X), which integrates speech-to-text and speech-to-speech tasks into a unified end-to-end framework. We develop a non-autoregressive decoder capable of concurrently generating multiple text or acoustic unit tokens upon receiving fixed-length speech chunks. The decoder can generate blank or repeated tokens and employ CTC decoding to dynamically adjust its latency. Experimental results show that NAST-S2X outperforms state-of-the-art models in both speech-to-text and speech-to-speech tasks. It achieves high-quality simultaneous interpretation within a delay of less than 3 seconds and provides a 28 times decoding speedup in offline generation.
Decoder-only Streaming Transformer for Simultaneous Translation
Jun 06, 2024



Simultaneous Machine Translation (SiMT) generates translation while reading source tokens, essentially producing the target prefix based on the source prefix. To achieve good performance, it leverages the relationship between source and target prefixes to exact a policy to guide the generation of translations. Although existing SiMT methods primarily focus on the Encoder-Decoder architecture, we explore the potential of Decoder-only architecture, owing to its superior performance in various tasks and its inherent compatibility with SiMT. However, directly applying the Decoder-only architecture to SiMT poses challenges in terms of training and inference. To alleviate the above problems, we propose the first Decoder-only SiMT model, named Decoder-only Streaming Transformer (DST). Specifically, DST separately encodes the positions of the source and target prefixes, ensuring that the position of the target prefix remains unaffected by the expansion of the source prefix. Furthermore, we propose a Streaming Self-Attention (SSA) mechanism tailored for the Decoder-only architecture. It is capable of obtaining translation policy by assessing the sufficiency of input source information and integrating with the soft-attention mechanism to generate translations. Experiments demonstrate that our approach achieves state-of-the-art performance on three translation tasks.
StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning
Jun 05, 2024Simultaneous speech-to-speech translation (Simul-S2ST, a.k.a streaming speech translation) outputs target speech while receiving streaming speech inputs, which is critical for real-time communication. Beyond accomplishing translation between speech, Simul-S2ST requires a policy to control the model to generate corresponding target speech at the opportune moment within speech inputs, thereby posing a double challenge of translation and policy. In this paper, we propose StreamSpeech, a direct Simul-S2ST model that jointly learns translation and simultaneous policy in a unified framework of multi-task learning. Adhering to a multi-task learning approach, StreamSpeech can perform offline and simultaneous speech recognition, speech translation and speech synthesis via an "All-in-One" seamless model. Experiments on CVSS benchmark demonstrate that StreamSpeech achieves state-of-the-art performance in both offline S2ST and Simul-S2ST tasks. Besides, StreamSpeech is able to present high-quality intermediate results (i.e., ASR or translation results) during simultaneous translation process, offering a more comprehensive real-time communication experience.