 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Autoregressive Language Models
Oct 31, 2025The efficiency of large language models (LLMs) is fundamentally limited by their sequential, token-by-token generation process. We argue that overcoming this bottleneck requires a new design axis for LLM scaling: increasing the semantic bandwidth of each generative step. To this end, we introduce Continuous Autoregressive Language Models (CALM), a paradigm shift from discrete next-token prediction to continuous next-vector prediction. CALM uses a high-fidelity autoencoder to compress a chunk of K tokens into a single continuous vector, from which the original tokens can be reconstructed with over 99.9\% accuracy. This allows us to model language as a sequence of continuous vectors instead of discrete tokens, which reduces the number of generative steps by a factor of K. The paradigm shift necessitates a new modeling toolkit; therefore, we develop a comprehensive likelihood-free framework that enables robust training, evaluation, and controllable sampling in the continuous domain. Experiments show that CALM significantly improves the performance-compute trade-off, achieving the performance of strong discrete baselines at a significantly lower computational cost. More importantly, these findings establish next-vector prediction as a powerful and scalable pathway towards ultra-efficient language models. Code: https://github.com/shaochenze/calm. Project: https://shaochenze.github.io/blog/2025/CALM.
Efficient Speech Language Modeling via Energy Distance in Continuous Latent Space
May 19, 2025We introduce SLED, an alternative approach to speech language modeling by encoding speech waveforms into sequences of continuous latent representations and modeling them autoregressively using an energy distance objective. The energy distance offers an analytical measure of the distributional gap by contrasting simulated and target samples, enabling efficient training to capture the underlying continuous autoregressive distribution. By bypassing reliance on residual vector quantization, SLED avoids discretization errors and eliminates the need for the complicated hierarchical architectures common in existing speech language models. It simplifies the overall modeling pipeline while preserving the richness of speech information and maintaining inference efficiency. Empirical results demonstrate that SLED achieves strong performance in both zero-shot and streaming speech synthesis, showing its potential for broader applications in general-purpose speech language models.
Continuous Visual Autoregressive Generation via Score Maximization
May 12, 2025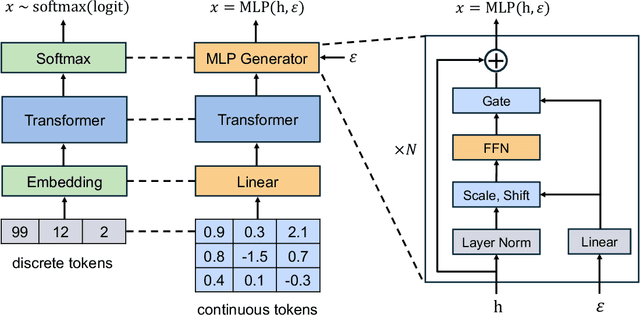



Conventional wisdom suggests that autoregressive models are used to process discrete data. When applied to continuous modalities such as visual data, Visual AutoRegressive modeling (VAR) typically resorts to quantization-based approaches to cast the data into a discrete space, which can introduce significant information loss. To tackle this issue, we introduce a Continuous VAR framework that enables direct visual autoregressive generation without vector quantization. The underlying theoretical foundation is strictly proper scoring rules, which provide powerful statistical tools capable of evaluating how well a generative model approximates the true distribution. Within this framework, all we need is to select a strictly proper score and set it as the training objective to optimize. We primarily explore a class of training objectives based on the energy score, which is likelihood-free and thus overcomes the difficulty of making probabilistic predictions in the continuous space. Previous efforts on continuous autoregressive generation, such as GIVT and diffusion loss, can also be derived from our framework using other strictly proper scores. Source code: https://github.com/shaochenze/EAR.
Patch-Level Training for Large Language Models
Jul 17, 2024



As Large Language Models (LLMs) achieve remarkable progress in language understanding and generation, their training efficiency has become a critical concern. Traditionally, LLMs are trained to predict the next token in a sequence. Despite the success of token-level training, it suffers from considerable computational costs due to the need to process an extensive number of tokens. To mitigate this issue, this paper introduces patch-level training for LLMs, which reduces the sequence length by compressing multiple tokens into a single patch. During patch-level training, we feed the language model shorter sequences of patches and train it to predict the next patch, thereby processing the majority of the training data at a significantly reduced computational cost. Following this, the model continues token-level training on the remaining training data to align with the inference mode. Experiments on a diverse range of models (370M-2.7B parameters) demonstrate that patch-level training can reduce overall computational costs to 0.5$\times$, without compromising the model performance compared to token-level training. Source code: \url{https://github.com/shaochenze/PatchTrain}.
Understanding and Addressing the Under-Translation Problem from the Perspective of Decoding Objective
May 29, 2024Neural Machine Translation (NMT) has made remarkable progress over the past years. However, under-translation and over-translation remain two challenging problems in state-of-the-art NMT systems. In this work, we conduct an in-depth analysis on the underlying cause of under-translation in NMT, providing an explanation from the perspective of decoding objective. To optimize the beam search objective, the model tends to overlook words it is less confident about, leading to the under-translation phenomenon. Correspondingly, the model's confidence in predicting the End Of Sentence (EOS) diminishes when under-translation occurs, serving as a mild penalty for under-translated candidates. Building upon this analysis, we propose employing the confidence of predicting EOS as a detector for under-translation, and strengthening the confidence-based penalty to penalize candidates with a high risk of under-translation. Experiments on both synthetic and real-world data show that our method can accurately detect and rectify under-translated outputs, with minor impact on other correct translations.
Language Generation with Strictly Proper Scoring Rules
May 29, 2024Language generation based on maximum likelihood estimation (MLE) has become the fundamental approach for text generation. Maximum likelihood estimation is typically performed by minimizing the log-likelihood loss, also known as the logarithmic score in statistical decision theory. The logarithmic score is strictly proper in the sense that it encourages honest forecasts, where the expected score is maximized only when the model reports true probabilities. Although many strictly proper scoring rules exist, the logarithmic score is the only local scoring rule among them that depends exclusively on the probability of the observed sample, making it capable of handling the exponentially large sample space of natural text. In this work, we propose a straightforward strategy for adapting scoring rules to language generation, allowing for language modeling with any non-local scoring rules. Leveraging this strategy, we train language generation models using two classic strictly proper scoring rules, the Brier score and the Spherical score, as alternatives to the logarithmic score. Experimental results indicate that simply substituting the loss function, without adjusting other hyperparameters, can yield substantial improvements in model's generation capabilities. Moreover, these improvements can scale up to large language models (LLMs) such as LLaMA-7B and LLaMA-13B. Source code: \url{https://github.com/shaochenze/ScoringRulesLM}.
Non-autoregressive Machine Translation with Probabilistic Context-free Grammar
Nov 14, 2023



Non-autoregressive Transformer(NAT) significantly accelerates the inference of neural machine translation. However, conventional NAT models suffer from limited expression power and performance degradation compared to autoregressive (AT) models due to the assumption of conditional independence among target tokens. To address these limitations, we propose a novel approach called PCFG-NAT, which leverages a specially designed Probabilistic Context-Free Grammar (PCFG) to enhance the ability of NAT models to capture complex dependencies among output tokens. Experimental results on major machine translation benchmarks demonstrate that PCFG-NAT further narrows the gap in translation quality between NAT and AT models. Moreover, PCFG-NAT facilitates a deeper understanding of the generated sentences, addressing the lack of satisfactory explainability in neural machine translation.Code is publicly available at https://github.com/ictnlp/PCFG-NAT.
Beyond MLE: Convex Learning for Text Generation
Oct 26, 2023Maximum likelihood estimation (MLE) is a statistical method used to estimate the parameters of a probability distribution that best explain the observed data. In the context of text generation, MLE is often used to train generative language models, which can then be used to generate new text. However, we argue that MLE is not always necessary and optimal, especially for closed-ended text generation tasks like machine translation. In these tasks, the goal of model is to generate the most appropriate response, which does not necessarily require it to estimate the entire data distribution with MLE. To this end, we propose a novel class of training objectives based on convex functions, which enables text generation models to focus on highly probable outputs without having to estimate the entire data distribution. We investigate the theoretical properties of the optimal predicted distribution when applying convex functions to the loss, demonstrating that convex functions can sharpen the optimal distribution, thereby enabling the model to better capture outputs with high probabilities. Experiments on various text generation tasks and models show the effectiveness of our approach. It enables autoregressive models to bridge the gap between greedy and beam search, and facilitates the learning of non-autoregressive models with a maximum improvement of 9+ BLEU points. Moreover, our approach also exhibits significant impact on large language models (LLMs), substantially enhancing their generative capability on various tasks. Source code is available at \url{https://github.com/ictnlp/Convex-Learning}.
Non-autoregressive Streaming Transformer for Simultaneous Translation
Oct 23, 2023



Simultaneous machine translation (SiMT) models are trained to strike a balance between latency and translation quality. However, training these models to achieve high quality while maintaining low latency often leads to a tendency for aggressive anticipation. We argue that such issue stems from the autoregressive architecture upon which most existing SiMT models are built. To address those issues, we propose non-autoregressive streaming Transformer (NAST) which comprises a unidirectional encoder and a non-autoregressive decoder with intra-chunk parallelism. We enable NAST to generate the blank token or repetitive tokens to adjust its READ/WRITE strategy flexibly, and train it to maximize the non-monotonic latent alignment with an alignment-based latency loss. Experiments on various SiMT benchmarks demonstrate that NAST outperforms previous strong autoregressive SiMT baselines.
Fuzzy Alignments in Directed Acyclic Graph for Non-Autoregressive Machine Translation
Mar 12, 2023Non-autoregressive translation (NAT) reduces the decoding latency but suffers from performance degradation due to the multi-modality problem. Recently, the structure of directed acyclic graph has achieved great success in NAT, which tackles the multi-modality problem by introducing dependency between vertices. However, training it with negative log-likelihood loss implicitly requires a strict alignment between reference tokens and vertices, weakening its ability to handle multiple translation modalities. In this paper, we hold the view that all paths in the graph are fuzzily aligned with the reference sentence. We do not require the exact alignment but train the model to maximize a fuzzy alignment score between the graph and reference, which takes captured translations in all modalities into account. Extensive experiments on major WMT benchmarks show that our method substantially improves translation performance and increases prediction confidence, setting a new state of the art for NAT on the raw training data.