 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Speech Language Modeling via Energy Distance in Continuous Latent Space
May 19, 2025We introduce SLED, an alternative approach to speech language modeling by encoding speech waveforms into sequences of continuous latent representations and modeling them autoregressively using an energy distance objective. The energy distance offers an analytical measure of the distributional gap by contrasting simulated and target samples, enabling efficient training to capture the underlying continuous autoregressive distribution. By bypassing reliance on residual vector quantization, SLED avoids discretization errors and eliminates the need for the complicated hierarchical architectures common in existing speech language models. It simplifies the overall modeling pipeline while preserving the richness of speech information and maintaining inference efficiency. Empirical results demonstrate that SLED achieves strong performance in both zero-shot and streaming speech synthesis, showing its potential for broader applications in general-purpose speech language models.
Large Language Models Are Read/Write Policy-Makers for Simultaneous Generation
Jan 01, 2025



Simultaneous generation models write generation results while reading streaming inputs, necessitating a policy-maker to determine the appropriate output timing. Existing simultaneous generation methods generally adopt the traditional encoder-decoder architecture and learn the generation and policy-making capabilities through complex dynamic programming techniques. Although LLMs excel at text generation, they face challenges in taking on the role of policy-makers through traditional training methods, limiting their exploration in simultaneous generation. To overcome these limitations, we propose a novel LLM-driven Simultaneous Generation (LSG) framework, which allows the off-the-shelf LLM to decide the generation timing and produce output concurrently. Specifically, LSG selects the generation policy that minimizes latency as the baseline policy. Referring to the baseline policy, LSG enables the LLM to devise an improved generation policy that better balances latency and generation quality, and writes generation results accordingly. Experiments on simultaneous translation and streaming automatic speech recognition tasks show that our method can achieve state-of-the-art performance utilizing the open-source LLMs and demonstrate practicality in real-world scenarios.
Learning Monotonic Attention in Transducer for Streaming Generation
Nov 26, 2024



Streaming generation models are increasingly utilized across various fields, with the Transducer architecture being particularly popular in industrial applications. However, its input-synchronous decoding mechanism presents challenges in tasks requiring non-monotonic alignments, such as simultaneous translation, leading to suboptimal performance in these contexts. In this research, we address this issue by tightly integrating Transducer's decoding with the history of input stream via a learnable monotonic attention mechanism. Our approach leverages the forward-backward algorithm to infer the posterior probability of alignments between the predictor states and input timestamps, which is then used to estimate the context representations of monotonic attention in training. This allows Transducer models to adaptively adjust the scope of attention based on their predictions, avoiding the need to enumerate the exponentially large alignment space. Extensive experiments demonstrate that our MonoAttn-Transducer significantly enhances the handling of non-monotonic alignments in streaming generation, offering a robust solution for Transducer-based frameworks to tackle more complex streaming generation tasks.
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Sep 10, 2024



Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech interaction models based on open-source LLMs. To address this, we propose LLaMA-Omni, a novel model architecture designed for low-latency and high-quality speech interaction with LLMs. LLaMA-Omni integrates a pretrained speech encoder, a speech adaptor, an LLM, and a streaming speech decoder. It eliminates the need for speech transcription, and can simultaneously generate text and speech responses directly from speech instructions with extremely low latency. We build our model based on the latest Llama-3.1-8B-Instruct model. To align the model with speech interaction scenarios, we construct a dataset named InstructS2S-200K, which includes 200K speech instructions and corresponding speech responses. Experimental results show that compared to previous speech-language models, LLaMA-Omni provides better responses in both content and style, with a response latency as low as 226ms. Additionally, training LLaMA-Omni takes less than 3 days on just 4 GPUs, paving the way for the efficient development of speech-language models in the future.
Agent-SiMT: Agent-assisted Simultaneous Machine Translation with Large Language Models
Jun 12, 2024Simultaneous Machine Translation (SiMT) generates target translations while reading the source sentence. It relies on a policy to determine the optimal timing for reading sentences and generating translations. Existing SiMT methods generally adopt the traditional Transformer architecture, which concurrently determines the policy and generates translations. While they excel at determining policies, their translation performance is suboptimal. Conversely, Large Language Models (LLMs), trained on extensive corpora, possess superior generation capabilities, but it is difficult for them to acquire translation policy through the training methods of SiMT. Therefore, we introduce Agent-SiMT, a framework combining the strengths of LLMs and traditional SiMT methods. Agent-SiMT contains the policy-decision agent and the translation agent. The policy-decision agent is managed by a SiMT model, which determines the translation policy using partial source sentence and translation. The translation agent, leveraging an LLM, generates translation based on the partial source sentence. The two agents collaborate to accomplish SiMT. Experiments demonstrate that Agent-SiMT attains state-of-the-art performance.
A Non-autoregressive Generation Framework for End-to-End Simultaneous Speech-to-Any Translation
Jun 11, 2024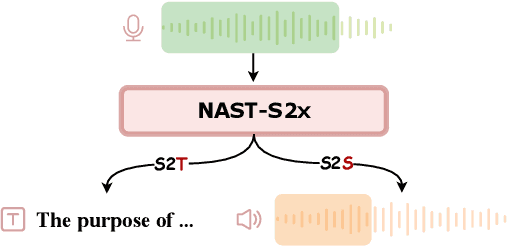



Simultaneous translation models play a crucial role in facilitating communication. However, existing research primarily focuses on text-to-text or speech-to-text models, necessitating additional cascade components to achieve speech-to-speech translation. These pipeline methods suffer from error propagation and accumulate delays in each cascade component, resulting in reduced synchronization between the speaker and listener. To overcome these challenges, we propose a novel non-autoregressive generation framework for simultaneous speech translation (NAST-S2X), which integrates speech-to-text and speech-to-speech tasks into a unified end-to-end framework. We develop a non-autoregressive decoder capable of concurrently generating multiple text or acoustic unit tokens upon receiving fixed-length speech chunks. The decoder can generate blank or repeated tokens and employ CTC decoding to dynamically adjust its latency. Experimental results show that NAST-S2X outperforms state-of-the-art models in both speech-to-text and speech-to-speech tasks. It achieves high-quality simultaneous interpretation within a delay of less than 3 seconds and provides a 28 times decoding speedup in offline generation.
Can We Achieve High-quality Direct Speech-to-Speech Translation without Parallel Speech Data?
Jun 11, 2024Recently proposed two-pass direct speech-to-speech translation (S2ST) models decompose the task into speech-to-text translation (S2TT) and text-to-speech (TTS) within an end-to-end model, yielding promising results. However, the training of these models still relies on parallel speech data, which is extremely challenging to collect. In contrast, S2TT and TTS have accumulated a large amount of data and pretrained models, which have not been fully utilized in the development of S2ST models. Inspired by this, in this paper, we first introduce a composite S2ST model named ComSpeech, which can seamlessly integrate any pretrained S2TT and TTS models into a direct S2ST model. Furthermore, to eliminate the reliance on parallel speech data, we propose a novel training method ComSpeech-ZS that solely utilizes S2TT and TTS data. It aligns representations in the latent space through contrastive learning, enabling the speech synthesis capability learned from the TTS data to generalize to S2ST in a zero-shot manner. Experimental results on the CVSS dataset show that when the parallel speech data is available, ComSpeech surpasses previous two-pass models like UnitY and Translatotron 2 in both translation quality and decoding speed. When there is no parallel speech data, ComSpeech-ZS lags behind \name by only 0.7 ASR-BLEU and outperforms the cascaded models.
CTC-based Non-autoregressive Textless Speech-to-Speech Translation
Jun 11, 2024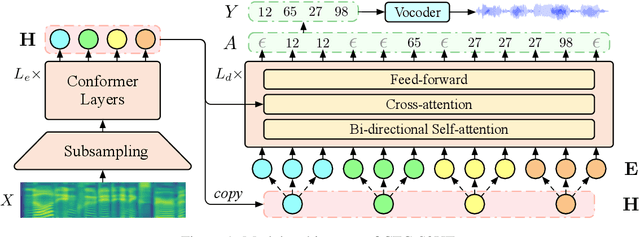
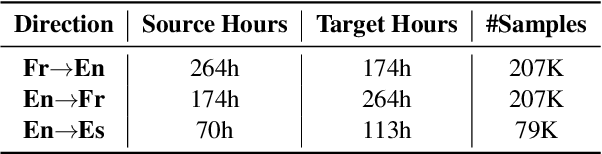

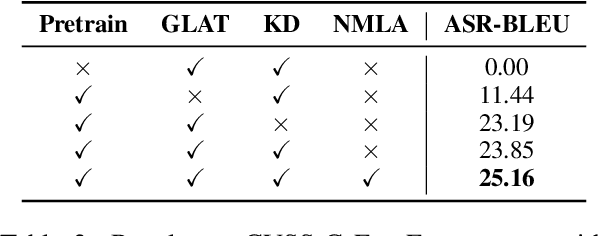
Direct speech-to-speech translation (S2ST) has achieved impressive translation quality, but it often faces the challenge of slow decoding due to the considerable length of speech sequences. Recently, some research has turned to non-autoregressive (NAR) models to expedite decoding, yet the translation quality typically lags behind autoregressive (AR) models significantly. In this paper, we investigate the performance of CTC-based NAR models in S2ST, as these models have shown impressive results in machine translation. Experimental results demonstrate that by combining pretraining, knowledge distillation, and advanced NAR training techniques such as glancing training and non-monotonic latent alignments, CTC-based NAR models achieve translation quality comparable to the AR model, while preserving up to 26.81$\times$ decoding speedup.
StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning
Jun 05, 2024Simultaneous speech-to-speech translation (Simul-S2ST, a.k.a streaming speech translation) outputs target speech while receiving streaming speech inputs, which is critical for real-time communication. Beyond accomplishing translation between speech, Simul-S2ST requires a policy to control the model to generate corresponding target speech at the opportune moment within speech inputs, thereby posing a double challenge of translation and policy. In this paper, we propose StreamSpeech, a direct Simul-S2ST model that jointly learns translation and simultaneous policy in a unified framework of multi-task learning. Adhering to a multi-task learning approach, StreamSpeech can perform offline and simultaneous speech recognition, speech translation and speech synthesis via an "All-in-One" seamless model. Experiments on CVSS benchmark demonstrate that StreamSpeech achieves state-of-the-art performance in both offline S2ST and Simul-S2ST tasks. Besides, StreamSpeech is able to present high-quality intermediate results (i.e., ASR or translation results) during simultaneous translation process, offering a more comprehensive real-time communication experience.
SiLLM: Large Language Models for Simultaneous Machine Translation
Feb 20, 2024

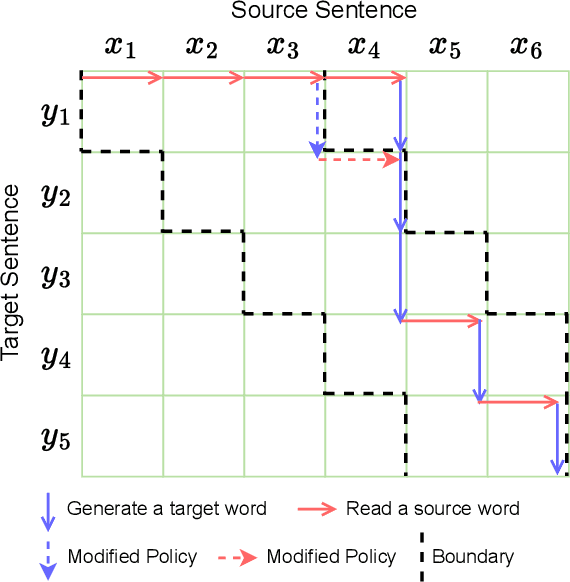

Simultaneous Machine Translation (SiMT) generates translations while reading the source sentence, necessitating a policy to determine the optimal timing for reading and generating words. Despite the remarkable performance achieved by Large Language Models (LLM) across various NLP tasks, existing SiMT methods predominantly focus on conventional transformers, employing a single model to concurrently determine the policy and generate the translations. However, given the complexity of SiMT, it is challenging to effectively address both tasks with a single model. Therefore, there is a need to decouple the SiMT task into policy-decision and translation sub-tasks. We propose SiLLM, which delegates the two sub-tasks to separate agents, thereby incorporating LLM into SiMT. The policy-decision agent is managed by a conventional SiMT model, responsible for determining the translation policy. The translation agent, leveraging the capabilities of LLM, generates translation using the partial source sentence. The two agents collaborate to accomplish SiMT. To facilitate the application of token-level policies determined by conventional SiMT models to LLM, we propose a word-level policy adapted for LLM. Experiments on two datasets demonstrate that, with a small amount of data for fine-tuning LLM, SiLLM attains state-of-the-art performance.