 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSO-Merging: Merging Models Based on Particle Swarm Optimization
Aug 27, 2025Model merging has emerged as an efficient strategy for constructing multitask models by integrating the strengths of multiple available expert models, thereby reducing the need to fine-tune a pre-trained model for all the tasks from scratch. Existing data-independent methods struggle with performance limitations due to the lack of data-driven guidance. Data-driven approaches also face key challenges: gradient-based methods are computationally expensive, limiting their practicality for merging large expert models, whereas existing gradient-free methods often fail to achieve satisfactory results within a limited number of optimization steps. To address these limitations, this paper introduces PSO-Merging, a novel data-driven merging method based on the Particle Swarm Optimization (PSO). In this approach, we initialize the particle swarm with a pre-trained model, expert models, and sparsified expert models. We then perform multiple iterations, with the final global best particle serving as the merged model. Experimental results on different language models show that PSO-Merging generally outperforms baseline merging methods, offering a more efficient and scalable solution for model merging.
BayLing 2: A Multilingual Large Language Model with Efficient Language Alignment
Nov 25, 2024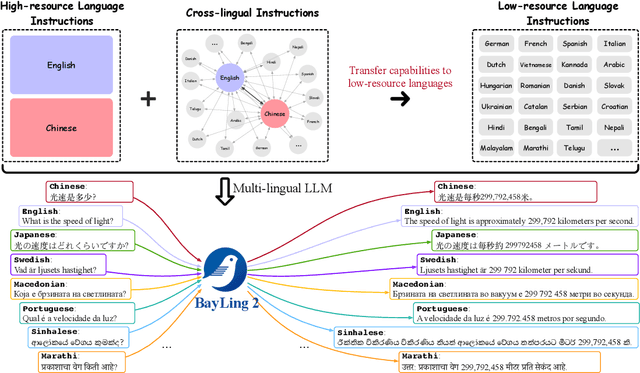


Large language models (LLMs), with their powerful generative capabilities and vast knowledge, empower various tasks in everyday life. However, these abilities are primarily concentrated in high-resource languages, leaving low-resource languages with weaker generative capabilities and relatively limited knowledge. Enhancing the multilingual capabilities of LLMs is therefore crucial for serving over 100 linguistic communities worldwide. An intuitive approach to enhance the multilingual capabilities would be to construct instruction data for various languages, but constructing instruction data for over 100 languages is prohibitively costly. In this paper, we introduce BayLing 2, which efficiently transfers generative capabilities and knowledge from high-resource languages to low-resource languages through language alignment. To achieve this, we constructed a dataset of 3.2 million instructions, comprising high-resource language instructions (Chinese and English) and cross-lingual instructions for 100+ languages and performed instruction tuning based on the dataset to facilitate the capability transfer between languages. Using Llama as the foundation model, we developed BayLing-2-7B, BayLing-2-13B, and BayLing-3-8B, and conducted a comprehensive evaluation of BayLing. For multilingual translation across 100+ languages, BayLing shows superior performance compared to open-source models of similar scale. For multilingual knowledge and understanding benchmarks, BayLing achieves significant improvements across over 20 low-resource languages, demonstrating its capability of effective knowledge transfer from high-resource to low-resource languages. Furthermore, results on English benchmarks indicate that BayLing maintains high performance in highresource languages while enhancing the performance in low-resource languages. Demo, homepage, code and models of BayLing are available.