 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCE: Adaptive Mixture of Contextualization Experts for Byte-based Neural Machine Translation
Nov 03, 2024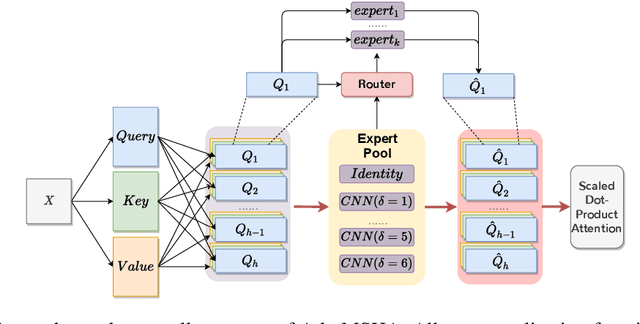

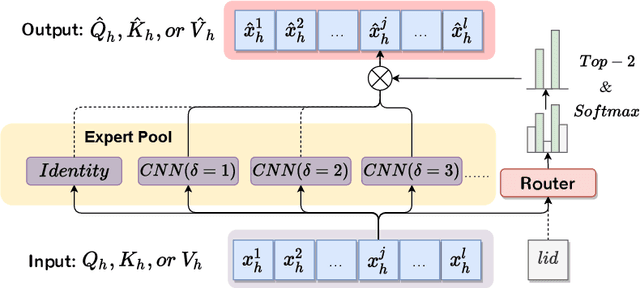

Byte-based machine translation systems have shown significant potential in massively multilingual settings. Unicode encoding, which maps each character to specific byte(s), eliminates the emergence of unknown words, even in new languages, enabling broad language scalability. However, byte-level tokenization results in sequences that are hard to interpret due to limited semantic information per byte. Local contextualization has proven effective in assigning initial semantics to tokens, improving sentence comprehension. Nevertheless, variations in encoding rules across languages necessitate an adaptive approach for effective contextualization. To this end, we propose Adaptive MultiScale-Headed Attention (Ada-MSHA), adaptively selecting and mixing attention heads, which are treated as contextualization experts. This enhances the flexibility of contextualization scales and improves the potential to discover a better strategy than previous methods. Experiment results show that our method outperforms existing methods without extensive manual adjustment of hyper-parameters and surpasses subword-based models with fewer parameters in Ted-59 dataset. Our code is available at https://github.com/ictnlp/MoCE.
BayLing: Bridging Cross-lingual Alignment and Instruction Following through Interactive Translation for Large Language Models
Jun 21, 2023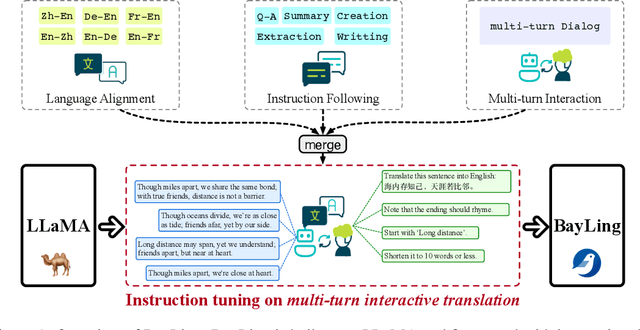
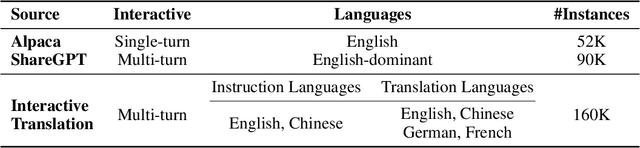

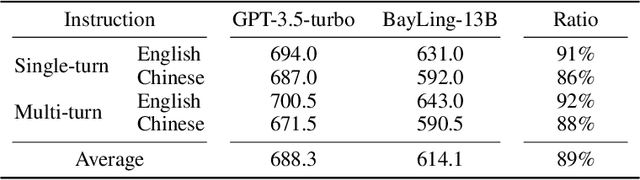
Large language models (LLMs) have demonstrated remarkable prowess in language understanding and generation. Advancing from foundation LLMs to instructionfollowing LLMs, instruction tuning plays a vital role in aligning LLMs to human preferences. However, the existing LLMs are usually focused on English, leading to inferior performance in non-English languages. In order to improve the performance for non-English languages, it is necessary to collect language-specific training data for foundation LLMs and construct language-specific instructions for instruction tuning, both of which are heavy loads. To minimize human workload, we propose to transfer the capabilities of language generation and instruction following from English to other languages through an interactive translation task. We have developed BayLing, an instruction-following LLM by utilizing LLaMA as the foundation LLM and automatically constructing interactive translation instructions for instructing tuning. Extensive assessments demonstrate that BayLing achieves comparable performance to GPT-3.5-turbo, despite utilizing a considerably smaller parameter size of only 13 billion. Experimental results on translation tasks show that BayLing achieves 95% of single-turn translation capability compared to GPT-4 with automatic evaluation and 96% of interactive translation capability compared to GPT-3.5-turbo with human evaluation. To estimate the performance on general tasks, we created a multi-turn instruction test set called BayLing-80. The experimental results on BayLing-80 indicate that BayLing achieves 89% of performance compared to GPT-3.5-turbo. BayLing also demonstrates outstanding performance on knowledge assessment of Chinese GaoKao and English SAT, second only to GPT-3.5-turbo among a multitude of instruction-following LLMs. Demo, homepage, code and models of BayLing are available.