 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-Zero: Self-Play for Open-Ended Generation from Zero Data
May 11, 2026Self-evolving LLMs excel in verifiable domains but struggle in open-ended tasks, where reliance on proxy LLM judges introduces capability bottlenecks and reward hacking. To overcome this, we introduce G-Zero, a verifier-free, co-evolutionary framework for autonomous self-improvement. Our core innovation is Hint-$δ$, an intrinsic reward that quantifies the predictive shift between a Generator model's unassisted response and its response conditioned on a self-generated hint. Using this signal, a Proposer model is trained via GRPO to continuously target the Generator's blind spots by synthesizing challenging queries and informative hints. The Generator is concurrently optimized via DPO to internalize these hint-guided improvements. Theoretically, we prove a best-iterate suboptimality guarantee for an idealized standard-DPO version of G-Zero, provided that the Proposer induces sufficient exploration coverage and the data filteration keeps pseudo-label score noise low. By deriving supervision entirely from internal distributional dynamics, G-Zero bypasses the capability ceilings of external judges, providing a scalable, robust pathway for continuous LLM self-evolution across unverifiable domains.
Training Data Efficiency in Multimodal Process Reward Models
Feb 05, 2026Multimodal Process Reward Models (MPRMs) are central to step-level supervision for visual reasoning in MLLMs. Training MPRMs typically requires large-scale Monte Carlo (MC)-annotated corpora, incurring substantial training cost. This paper studies the data efficiency for MPRM training. Our preliminary experiments reveal that MPRM training quickly saturates under random subsampling of the training data, indicating substantial redundancy within existing MC-annotated corpora. To explain this, we formalize a theoretical framework and reveal that informative gradient updates depend on two factors: label mixtures of positive/negative steps and label reliability (average MC scores of positive steps). Guided by these insights, we propose the Balanced-Information Score (BIS), which prioritizes both mixture and reliability based on existing MC signals at the rollout level, without incurring any additional cost. Across two backbones (InternVL2.5-8B and Qwen2.5-VL-7B) on VisualProcessBench, BIS-selected subsets consistently match and even surpass the full-data performance at small fractions. Notably, the BIS subset reaches full-data performance using only 10% of the training data, improving over random subsampling by a relative 4.1%.
RelayLLM: Efficient Reasoning via Collaborative Decoding
Jan 08, 2026Large Language Models (LLMs) for complex reasoning is often hindered by high computational costs and latency, while resource-efficient Small Language Models (SLMs) typically lack the necessary reasoning capacity. Existing collaborative approaches, such as cascading or routing, operate at a coarse granularity by offloading entire queries to LLMs, resulting in significant computational waste when the SLM is capable of handling the majority of reasoning steps. To address this, we propose RelayLLM, a novel framework for efficient reasoning via token-level collaborative decoding. Unlike routers, RelayLLM empowers the SLM to act as an active controller that dynamically invokes the LLM only for critical tokens via a special command, effectively "relaying" the generation process. We introduce a two-stage training framework, including warm-up and Group Relative Policy Optimization (GRPO) to teach the model to balance independence with strategic help-seeking. Empirical results across six benchmarks demonstrate that RelayLLM achieves an average accuracy of 49.52%, effectively bridging the performance gap between the two models. Notably, this is achieved by invoking the LLM for only 1.07% of the total generated tokens, offering a 98.2% cost reduction compared to performance-matched random routers.
CrossWordBench: Evaluating the Reasoning Capabilities of LLMs and LVLMs with Controllable Puzzle Generation
Mar 30, 2025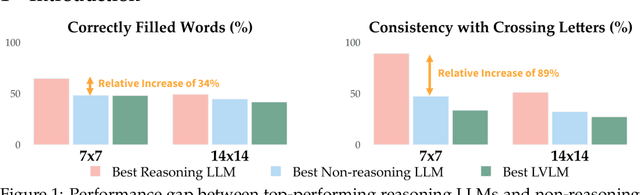
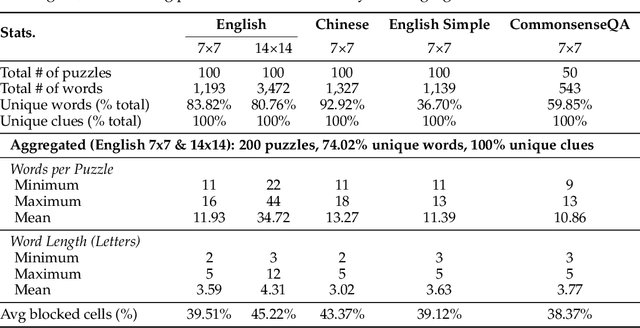
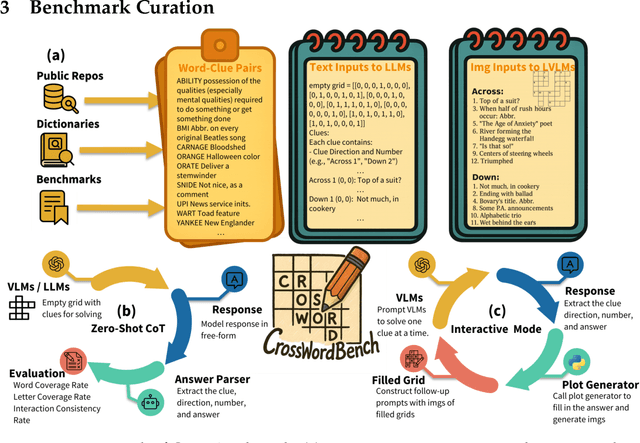
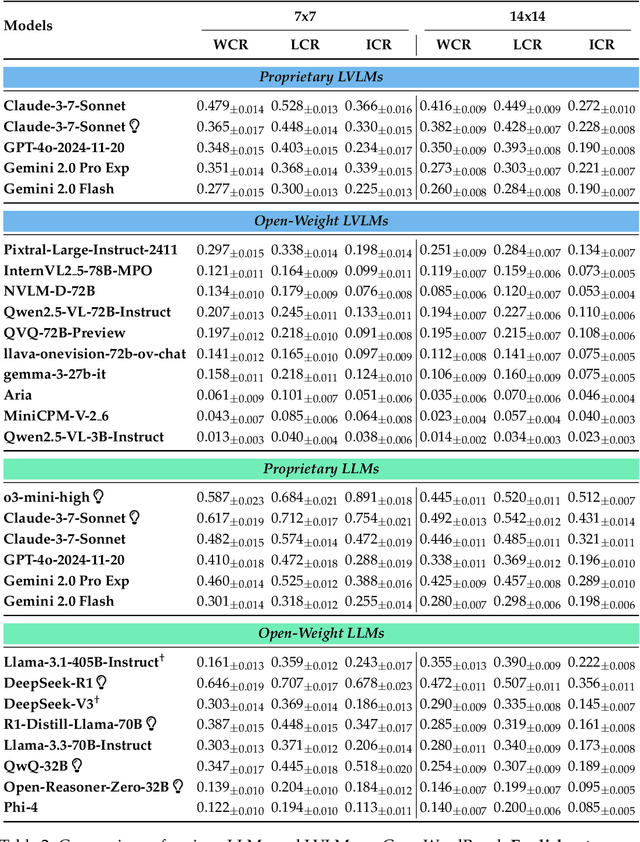
Existing reasoning evaluation frameworks for Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) predominantly either assess text-based reasoning or vision-language understanding capabilities, with limited dynamic interplay between textual and visual constraints. To address this limitation, we introduce CrossWordBench, a benchmark designed to evaluate the reasoning capabilities of both LLMs and LVLMs through the medium of crossword puzzles-a task requiring multimodal adherence to semantic constraints from text-based clues and intersectional constraints from visual grid structures. CrossWordBench leverages a controllable puzzle generation framework that produces puzzles in multiple formats (text and image) and offers different evaluation strategies ranging from direct puzzle solving to interactive modes. Our extensive evaluation of over 20 models reveals that reasoning LLMs outperform non-reasoning models substantially by effectively leveraging crossing-letter constraints. We further demonstrate that LVLMs struggle with the task, showing a strong correlation between their puzzle-solving performance and grid-parsing accuracy. Our findings offer insights into the limitations of the reasoning capabilities of current LLMs and LVLMs, and provide an effective approach for creating multimodal constrained tasks for future evaluations.
MoCE: Adaptive Mixture of Contextualization Experts for Byte-based Neural Machine Translation
Nov 03, 2024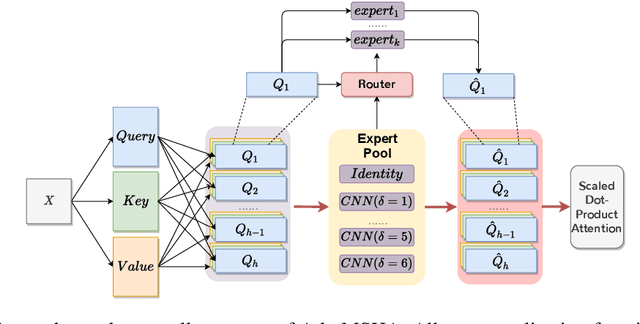

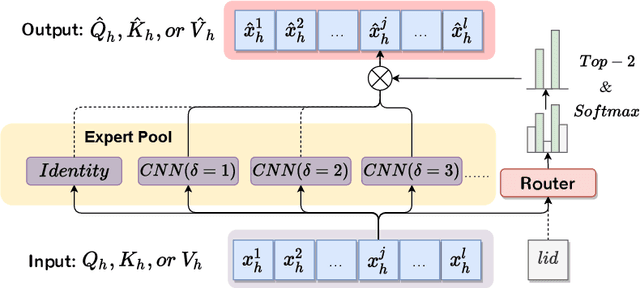

Byte-based machine translation systems have shown significant potential in massively multilingual settings. Unicode encoding, which maps each character to specific byte(s), eliminates the emergence of unknown words, even in new languages, enabling broad language scalability. However, byte-level tokenization results in sequences that are hard to interpret due to limited semantic information per byte. Local contextualization has proven effective in assigning initial semantics to tokens, improving sentence comprehension. Nevertheless, variations in encoding rules across languages necessitate an adaptive approach for effective contextualization. To this end, we propose Adaptive MultiScale-Headed Attention (Ada-MSHA), adaptively selecting and mixing attention heads, which are treated as contextualization experts. This enhances the flexibility of contextualization scales and improves the potential to discover a better strategy than previous methods. Experiment results show that our method outperforms existing methods without extensive manual adjustment of hyper-parameters and surpasses subword-based models with fewer parameters in Ted-59 dataset. Our code is available at https://github.com/ictnlp/MoCE.
Divide, Reweight, and Conquer: A Logit Arithmetic Approach for In-Context Learning
Oct 14, 2024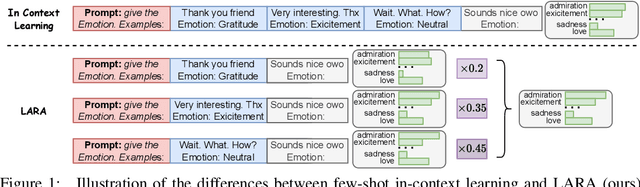
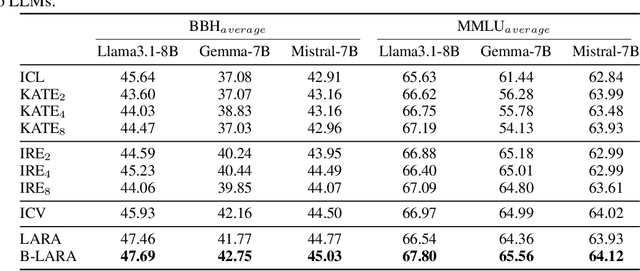
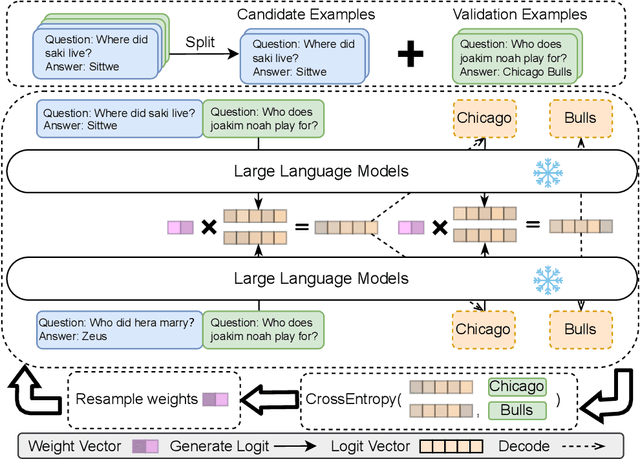
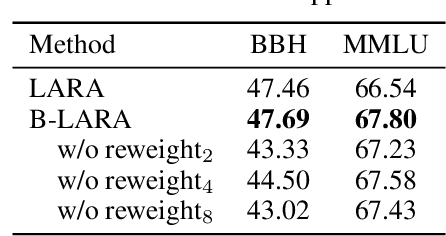
In-Context Learning (ICL) emerges as a key feature for Large Language Models (LLMs), allowing them to adapt to new tasks by leveraging task-specific examples without updating model parameters. However, ICL faces challenges with increasing numbers of examples due to performance degradation and quadratic computational costs. In this paper, we propose Logit Arithmetic Reweighting Approach (LARA), a novel framework that enhances ICL by using logit-based ensembling of multiple demonstrations. Our approach divides long input demonstrations into parallelizable shorter inputs to significantly reduce memory requirements, and then effectively aggregate the information by reweighting logits of each group via a non-gradient optimization approach. We further introduce Binary LARA (B-LARA), a variant that constrains weights to binary values to simplify the search space and reduces memory usage by filtering out less informative demonstration groups. Experiments on BBH and MMLU demonstrate that LARA and B-LARA outperform all baseline methods in both accuracy and memory efficiency. We also conduct extensive analysis to show that LARA generalizes well to scenarios of varying numbers of examples from limited to many-shot demonstrations.
Integrating Multi-scale Contextualized Information for Byte-based Neural Machine Translation
May 29, 2024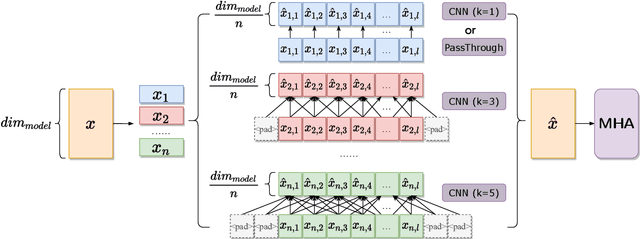



Subword tokenization is a common method for vocabulary building in Neural Machine Translation (NMT) models. However, increasingly complex tasks have revealed its disadvantages. First, a vocabulary cannot be modified once it is learned, making it hard to adapt to new words. Second, in multilingual translation, the imbalance in data volumes across different languages spreads to the vocabulary, exacerbating translations involving low-resource languages. While byte-based tokenization addresses these issues, byte-based models struggle with the low information density inherent in UTF-8 byte sequences. Previous works enhance token semantics through local contextualization but fail to select an appropriate contextualizing scope based on the input. Consequently, we propose the Multi-Scale Contextualization (MSC) method, which learns contextualized information of varying scales across different hidden state dimensions. It then leverages the attention module to dynamically integrate the multi-scale contextualized information. Experiments show that MSC significantly outperforms subword-based and other byte-based methods in both multilingual and out-of-domain scenarios. Code can be found in https://github.com/ictnlp/Multiscale-Contextualization.
Enhancing Neural Machine Translation with Semantic Units
Oct 17, 2023
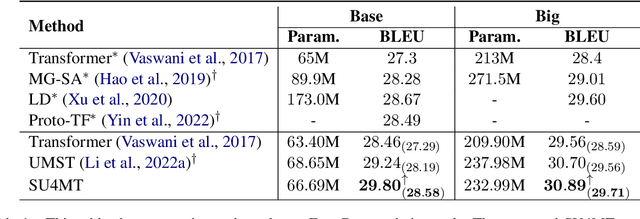
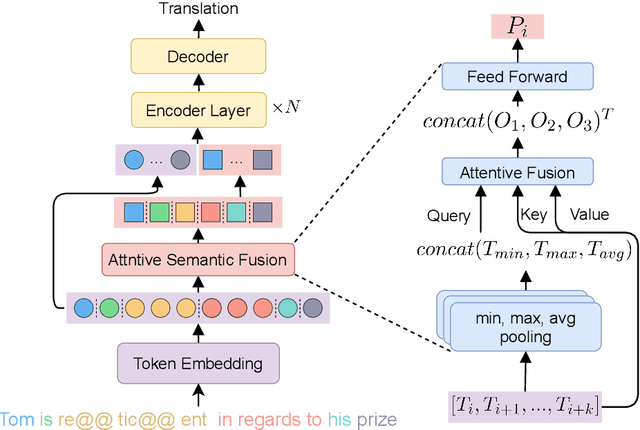
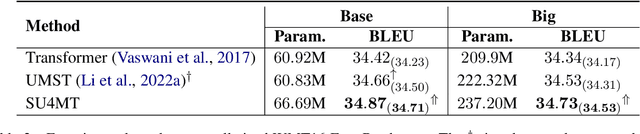
Conventional neural machine translation (NMT) models typically use subwords and words as the basic units for model input and comprehension. However, complete words and phrases composed of several tokens are often the fundamental units for expressing semantics, referred to as semantic units. To address this issue, we propose a method Semantic Units for Machine Translation (SU4MT) which models the integral meanings of semantic units within a sentence, and then leverages them to provide a new perspective for understanding the sentence. Specifically, we first propose Word Pair Encoding (WPE), a phrase extraction method to help identify the boundaries of semantic units. Next, we design an Attentive Semantic Fusion (ASF) layer to integrate the semantics of multiple subwords into a single vector: the semantic unit representation. Lastly, the semantic-unit-level sentence representation is concatenated to the token-level one, and they are combined as the input of encoder. Experimental results demonstrate that our method effectively models and leverages semantic-unit-level information and outperforms the strong baselines. The code is available at https://github.com/ictnlp/SU4MT.
BayLing: Bridging Cross-lingual Alignment and Instruction Following through Interactive Translation for Large Language Models
Jun 21, 2023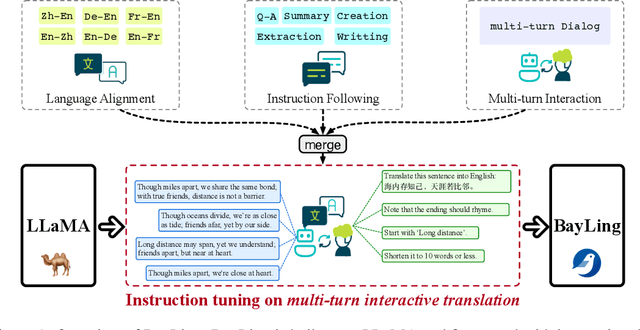
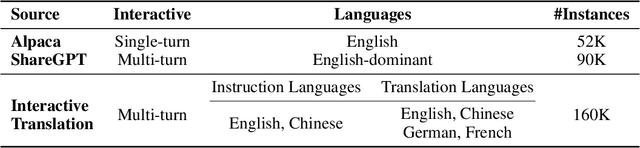

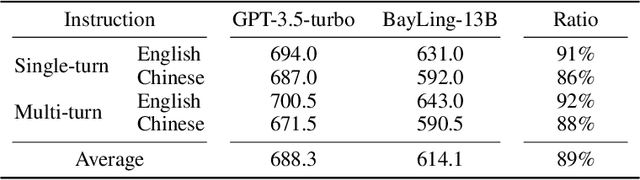
Large language models (LLMs) have demonstrated remarkable prowess in language understanding and generation. Advancing from foundation LLMs to instructionfollowing LLMs, instruction tuning plays a vital role in aligning LLMs to human preferences. However, the existing LLMs are usually focused on English, leading to inferior performance in non-English languages. In order to improve the performance for non-English languages, it is necessary to collect language-specific training data for foundation LLMs and construct language-specific instructions for instruction tuning, both of which are heavy loads. To minimize human workload, we propose to transfer the capabilities of language generation and instruction following from English to other languages through an interactive translation task. We have developed BayLing, an instruction-following LLM by utilizing LLaMA as the foundation LLM and automatically constructing interactive translation instructions for instructing tuning. Extensive assessments demonstrate that BayLing achieves comparable performance to GPT-3.5-turbo, despite utilizing a considerably smaller parameter size of only 13 billion. Experimental results on translation tasks show that BayLing achieves 95% of single-turn translation capability compared to GPT-4 with automatic evaluation and 96% of interactive translation capability compared to GPT-3.5-turbo with human evaluation. To estimate the performance on general tasks, we created a multi-turn instruction test set called BayLing-80. The experimental results on BayLing-80 indicate that BayLing achieves 89% of performance compared to GPT-3.5-turbo. BayLing also demonstrates outstanding performance on knowledge assessment of Chinese GaoKao and English SAT, second only to GPT-3.5-turbo among a multitude of instruction-following LLMs. Demo, homepage, code and models of BayLing are available.