 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-structured LLM Reasoners Can Be Rigorously Audited
May 30, 2025As Large Language Models (LLMs) become increasingly capable at reasoning, the problem of "faithfulness" persists: LLM "reasoning traces" can contain errors and omissions that are difficult to detect, and may obscure biases in model outputs. To address these limitations, we introduce Semi-Structured Reasoning Models (SSRMs), which internalize a semi-structured Chain-of-Thought (CoT) reasoning format within the model. Our SSRMs generate reasoning traces in a Pythonic syntax. While SSRM traces are not executable, they adopt a restricted, task-specific vocabulary to name distinct reasoning steps, and to mark each step's inputs and outputs. Through extensive evaluation on ten benchmarks, SSRMs demonstrate strong performance and generality: they outperform comparably sized baselines by nearly ten percentage points on in-domain tasks while remaining competitive with specialized models on out-of-domain medical benchmarks. Furthermore, we show that semi-structured reasoning is more amenable to analysis: in particular, they can be automatically audited to identify reasoning flaws. We explore both hand-crafted structured audits, which detect task-specific problematic reasoning patterns, and learned typicality audits, which apply probabilistic models over reasoning patterns, and show that both audits can be used to effectively flag probable reasoning errors.
CrossWordBench: Evaluating the Reasoning Capabilities of LLMs and LVLMs with Controllable Puzzle Generation
Mar 30, 2025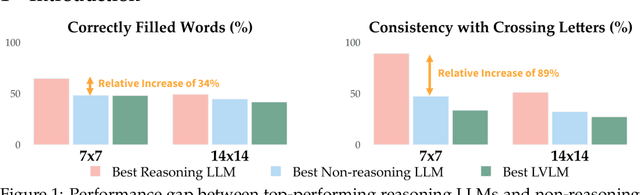
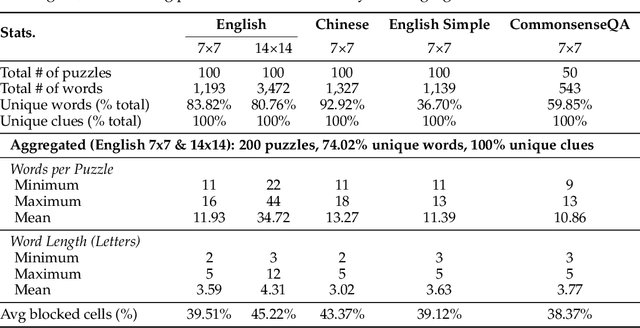
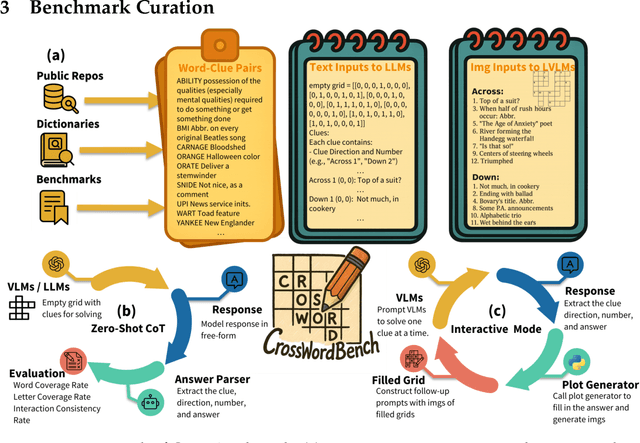
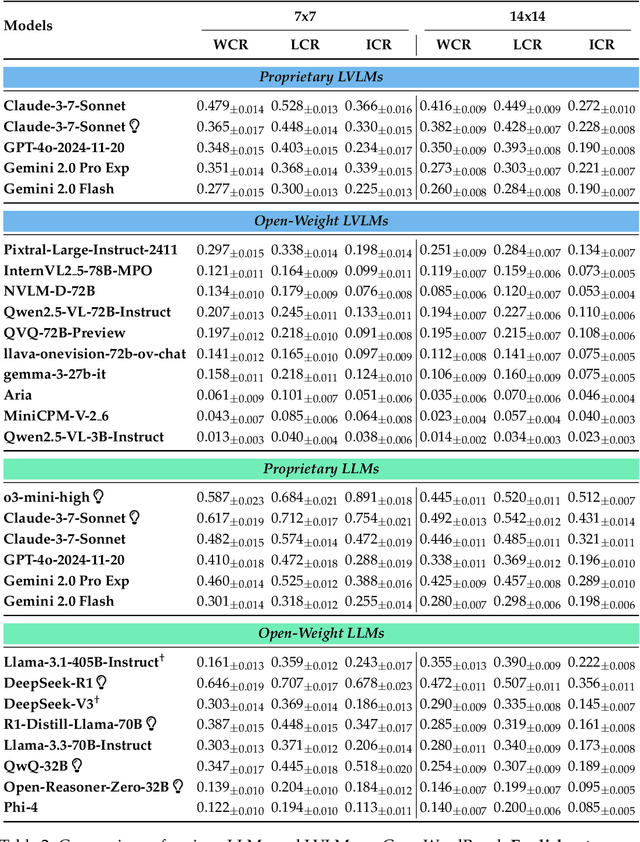
Existing reasoning evaluation frameworks for Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) predominantly either assess text-based reasoning or vision-language understanding capabilities, with limited dynamic interplay between textual and visual constraints. To address this limitation, we introduce CrossWordBench, a benchmark designed to evaluate the reasoning capabilities of both LLMs and LVLMs through the medium of crossword puzzles-a task requiring multimodal adherence to semantic constraints from text-based clues and intersectional constraints from visual grid structures. CrossWordBench leverages a controllable puzzle generation framework that produces puzzles in multiple formats (text and image) and offers different evaluation strategies ranging from direct puzzle solving to interactive modes. Our extensive evaluation of over 20 models reveals that reasoning LLMs outperform non-reasoning models substantially by effectively leveraging crossing-letter constraints. We further demonstrate that LVLMs struggle with the task, showing a strong correlation between their puzzle-solving performance and grid-parsing accuracy. Our findings offer insights into the limitations of the reasoning capabilities of current LLMs and LVLMs, and provide an effective approach for creating multimodal constrained tasks for future evaluations.
S$^{2}$FT: Efficient, Scalable and Generalizable LLM Fine-tuning by Structured Sparsity
Dec 10, 2024



Current PEFT methods for LLMs can achieve either high quality, efficient training, or scalable serving, but not all three simultaneously. To address this limitation, we investigate sparse fine-tuning and observe a remarkable improvement in generalization ability. Utilizing this key insight, we propose a family of Structured Sparse Fine-Tuning (S$^{2}$FT) methods for LLMs, which concurrently achieve state-of-the-art fine-tuning performance, training efficiency, and inference scalability. S$^{2}$FT accomplishes this by "selecting sparsely and computing densely". It selects a few heads and channels in the MHA and FFN modules for each Transformer block, respectively. Next, it co-permutes weight matrices on both sides of the coupled structures in LLMs to connect the selected components in each layer into a dense submatrix. Finally, S$^{2}$FT performs in-place gradient updates on all submatrices. Through theoretical analysis and empirical results, our method prevents overfitting and forgetting, delivers SOTA performance on both commonsense and arithmetic reasoning with 4.6% and 1.3% average improvements compared to LoRA, and surpasses full FT by 11.5% when generalizing to various domains after instruction tuning. Using our partial backpropagation algorithm, S$^{2}$FT saves training memory up to 3$\times$ and improves latency by 1.5-2.7$\times$ compared to full FT, while delivering an average 10% improvement over LoRA on both metrics. We further demonstrate that the weight updates in S$^{2}$FT can be decoupled into adapters, enabling effective fusion, fast switch, and efficient parallelism for serving multiple fine-tuned models.
Taming Overconfidence in LLMs: Reward Calibration in RLHF
Oct 13, 2024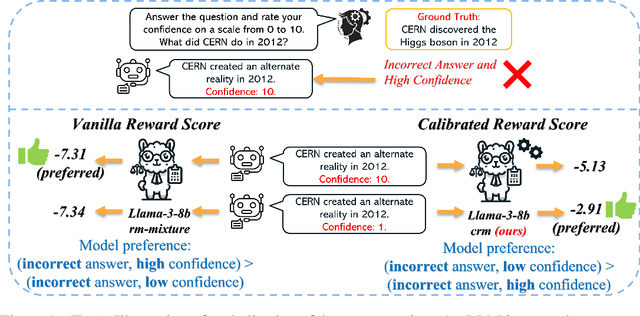
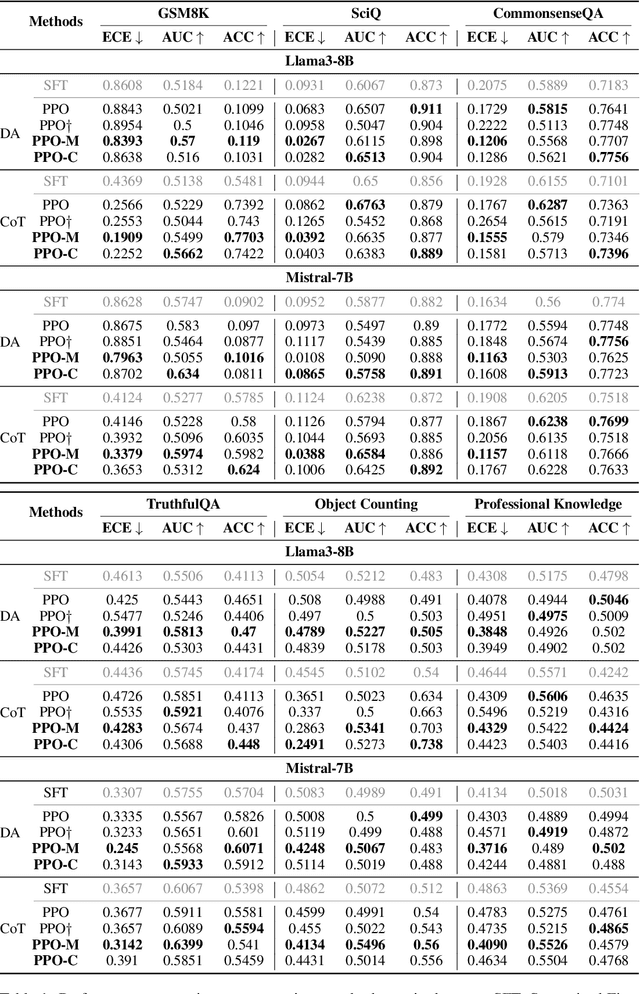
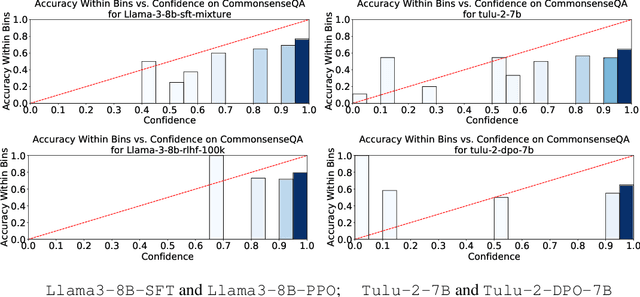
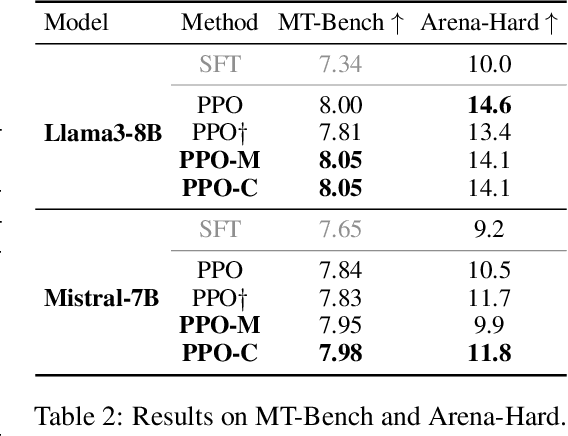
Language model calibration refers to the alignment between the confidence of the model and the actual performance of its responses. While previous studies point out the overconfidence phenomenon in Large Language Models (LLMs) and show that LLMs trained with Reinforcement Learning from Human Feedback (RLHF) are overconfident with a more sharpened output probability, in this study, we reveal that RLHF tends to lead models to express verbalized overconfidence in their own responses. We investigate the underlying cause of this overconfidence and demonstrate that reward models used for Proximal Policy Optimization (PPO) exhibit inherent biases towards high-confidence scores regardless of the actual quality of responses. Building upon this insight, we propose two PPO variants: PPO-M: PPO with Calibrated Reward Modeling and PPO-C: PPO with Calibrated Reward Calculation. PPO-M integrates explicit confidence scores in reward model training, which calibrates reward models to better capture the alignment between response quality and verbalized confidence. PPO-C adjusts the reward score during PPO based on the difference between the current reward and the moving average of past rewards. Both PPO-M and PPO-C can be seamlessly integrated into the current PPO pipeline and do not require additional golden labels. We evaluate our methods on both Llama3-8B and Mistral-7B across six diverse datasets including multiple-choice and open-ended generation. Experiment results demonstrate that both of our methods can reduce calibration error and maintain performance comparable to standard PPO. We further show that they do not compromise model capabilities in open-ended conversation settings.
Choosing Wisely and Learning Deeply: Selective Cross-Modality Distillation via CLIP for Domain Generalization
Nov 26, 2023



Domain Generalization (DG), a crucial research area, seeks to train models across multiple domains and test them on unseen ones. In this paper, we introduce a novel approach, namely, Selective Cross-Modality Distillation for Domain Generalization (SCMD). SCMD leverages the capabilities of large vision-language models, specifically the CLIP model, to train a more efficient model, ensuring it acquires robust generalization capabilities across unseen domains. Our primary contribution is a unique selection framework strategically designed to identify hard-to-learn samples for distillation. In parallel, we introduce a novel cross-modality module. This module seamlessly combines the projected features of the student model with the text embeddings from CLIP, ensuring the alignment of similarity distributions. We assess SCMD's performance on various benchmarks, where it empowers a ResNet50 to deliver state-of-the-art performance, surpassing existing domain generalization methods. Furthermore, we provide a theoretical analysis of our selection strategy, offering deeper insight into its effectiveness and potential in the field of DG.