 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionRS: A Large-Scale RGB-Infrared Remote Sensing Dataset for Dual-Modal Vision-Language Foundation Models
Jun 15, 2026Remote sensing vision-language models have advanced Earth observation understanding, but most existing work remains centered on RGB imagery, leaving the complementary information in infrared data underexplored. Infrared images provide distinctive cues, including thermal intensity structures, object boundaries, and illumination-invariant scene features, which can enrich visual-language learning beyond conventional RGB observations. However, a large-scale RGB-infrared-text dataset for remote sensing vision-language modeling is still absent. To address this gap, we introduce FusionRS, the first large-scale RGB-infrared-text dataset designed for dual-modal vision-language learning in remote sensing. FusionRS is constructed by translating diverse public RGB remote sensing images into infrared-style counterparts, forming aligned RGB-IR image pairs. Each pair is associated with conventional scene captions and IR-aware captions that explicitly describe infrared-specific visual properties while preserving semantic content. Based on FusionRS, we train dual-modal vision-language foundation models for RGB-IR joint understanding. We first train CLIP-style models for RGB-IR-text alignment, and then fine-tune generative VLMs for dual-modal RGB-IR captioning. Experiments show that FusionRS improves RGB-IR alignment, infrared-to-text retrieval, and dual-modal captioning over RGB-only and non-IR-aware training settings. Ablation studies further verify that IR-aware captions are crucial for strengthening infrared-language alignment, highlighting the importance of modality-specific textual supervision for more scalable RGB-infrared remote sensing vision-language representation learning.
Exposing Vulnerabilities in Visible-Infrared VLMs: A Unified Geometric Adversarial Framework with Cross-Task Transferability
May 21, 2026Vision-language models (VLMs) have achieved strong performance across diverse multimodal tasks, but their adversarial robustness in visible-infrared (VIS-IR) scenarios remains underexplored. This gap is critical because VIS-IR sensing is widely used in real-world perception systems to support reliable understanding under challenging imaging conditions. To address this cross-modal threat setting, we propose CFGPatch, a curved-edge fractal geometric adversarial patch framework for attacking VIS-IR VLMs. CFGPatch builds on triangular fractal geometry and replaces rigid straight-edged primitives with Bezier-curved elements, preserving multi-scale fractal self-similarity while introducing smoother contours, richer directional variation, and more flexible shape deformation. In addition, we design a modality-specific Fraser-spiral rendering mechanism to inject fine-grained texture distortions and misleading perceptual cues into visible and infrared images. By coupling global curved-fractal geometry with local spiral-based appearance interference, CFGPatch disrupts both shape perception and texture interpretation. We further adopt expectation over transformation (EOT) to improve robustness against common image-level transformations. Extensive experiments show that CFGPatch effectively fools VIS-IR VLMs and consistently outperforms standard patch baselines in attack effectiveness and robustness. Moreover, adversarial samples optimized for zero-shot classification transfer well to image captioning and visual question answering, demonstrating strong cross-task transferability and generalizability across downstream tasks.
Multimodal Emotion Regression with Multi-Objective Optimization and VAD-Aware Audio Modeling for the 10th ABAW EMI Track
Mar 14, 2026We participated in the 10th ABAW Challenge, focusing on the Emotional Mimicry Intensity (EMI) Estimation track on the Hume-Vidmimic2 dataset. This task aims to predict six continuous emotion dimensions: Admiration, Amusement, Determination, Empathic Pain, Excitement, and Joy. Through systematic multimodal exploration of pretrained high-level features, we found that, under our pretrained feature setting, direct feature concatenation outperformed the more complex fusion strategies we tested. This empirical finding motivated us to design a systematic approach built upon three core principles: (i) preserving modality-specific attributes through feature-level concatenation; (ii) improving training stability and metric alignment via multi-objective optimization; and (iii) enriching acoustic representations with a VAD-inspired latent prior. Our final framework integrates concatenation-based multimodal fusion, a shared six-dimensional regression head, multi-objective optimization with MSE, Pearson-correlation, and auxiliary branch supervision, EMA for parameter stabilization, and a VAD-inspired latent prior for the acoustic branch. On the official validation set, the proposed scheme achieved our best mean Pearson Correlation Coefficient of 0.478567.
A Semantic Decoupling-Based Two-Stage Rainy-Day Attack for Revealing Weather Robustness Deficiencies in Vision-Language Models
Jan 19, 2026Vision-Language Models (VLMs) are trained on image-text pairs collected under canonical visual conditions and achieve strong performance on multimodal tasks. However, their robustness to real-world weather conditions, and the stability of cross-modal semantic alignment under such structured perturbations, remain insufficiently studied. In this paper, we focus on rainy scenarios and introduce the first adversarial framework that exploits realistic weather to attack VLMs, using a two-stage, parameterized perturbation model based on semantic decoupling to analyze rain-induced shifts in decision-making. In Stage 1, we model the global effects of rainfall by applying a low-dimensional global modulation to condition the embedding space and gradually weaken the original semantic decision boundaries. In Stage 2, we introduce structured rain variations by explicitly modeling multi-scale raindrop appearance and rainfall-induced illumination changes, and optimize the resulting non-differentiable weather space to induce stable semantic shifts. Operating in a non-pixel parameter space, our framework generates perturbations that are both physically grounded and interpretable. Experiments across multiple tasks show that even physically plausible, highly constrained weather perturbations can induce substantial semantic misalignment in mainstream VLMs, posing potential safety and reliability risks in real-world deployment. Ablations further confirm that illumination modeling and multi-scale raindrop structures are key drivers of these semantic shifts.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Ocean-OCR: Towards General OCR Application via a Vision-Language Model
Jan 26, 2025



Multimodal large language models (MLLMs) have shown impressive capabilities across various domains, excelling in processing and understanding information from multiple modalities. Despite the rapid progress made previously, insufficient OCR ability hinders MLLMs from excelling in text-related tasks. In this paper, we present \textbf{Ocean-OCR}, a 3B MLLM with state-of-the-art performance on various OCR scenarios and comparable understanding ability on general tasks. We employ Native Resolution ViT to enable variable resolution input and utilize a substantial collection of high-quality OCR datasets to enhance the model performance. We demonstrate the superiority of Ocean-OCR through comprehensive experiments on open-source OCR benchmarks and across various OCR scenarios. These scenarios encompass document understanding, scene text recognition, and handwritten recognition, highlighting the robust OCR capabilities of Ocean-OCR. Note that Ocean-OCR is the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR.
Improved Content Understanding With Effective Use of Multi-task Contrastive Learning
May 21, 2024



In enhancing LinkedIn core content recommendation models, a significant challenge lies in improving their semantic understanding capabilities. This paper addresses the problem by leveraging multi-task learning, a method that has shown promise in various domains. We fine-tune a pre-trained, transformer-based LLM using multi-task contrastive learning with data from a diverse set of semantic labeling tasks. We observe positive transfer, leading to superior performance across all tasks when compared to training independently on each. Our model outperforms the baseline on zero shot learning and offers improved multilingual support, highlighting its potential for broader application. The specialized content embeddings produced by our model outperform generalized embeddings offered by OpenAI on Linkedin dataset and tasks. This work provides a robust foundation for vertical teams across LinkedIn to customize and fine-tune the LLM to their specific applications. Our work offers insights and best practices for the field to build on.
Multimodal Fusion with Pre-Trained Model Features in Affective Behaviour Analysis In-the-wild
Mar 22, 2024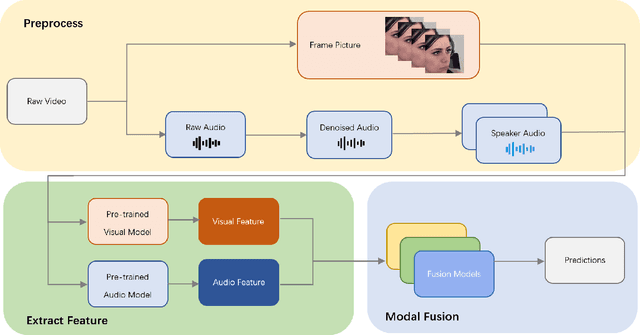
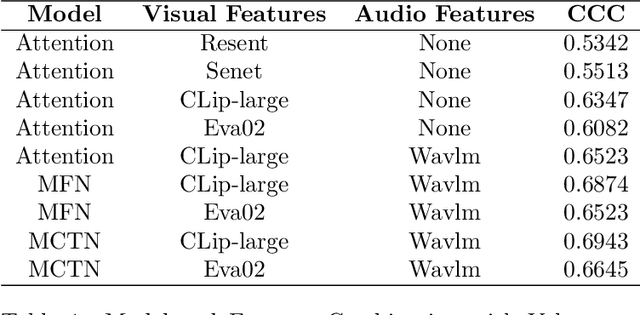

Multimodal fusion is a significant method for most multimodal tasks. With the recent surge in the number of large pre-trained models, combining both multimodal fusion methods and pre-trained model features can achieve outstanding performance in many multimodal tasks. In this paper, we present our approach, which leverages both advantages for addressing the task of Expression (Expr) Recognition and Valence-Arousal (VA) Estimation. We evaluate the Aff-Wild2 database using pre-trained models, then extract the final hidden layers of the models as features. Following preprocessing and interpolation or convolution to align the extracted features, different models are employed for modal fusion. Our code is available at GitHub - FulgenceWen/ABAW6th.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024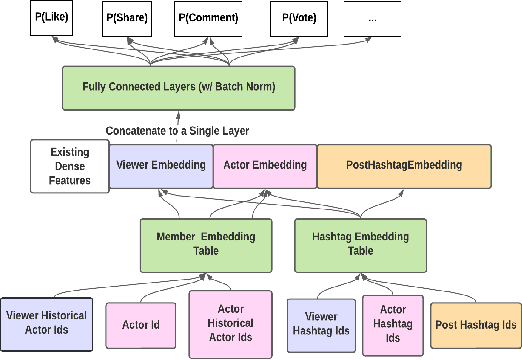

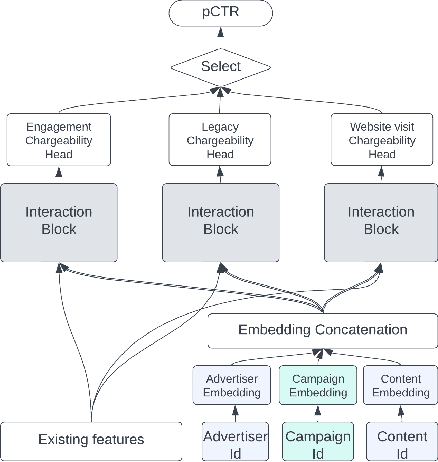

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
FsaNet: Frequency Self-attention for Semantic Segmentation
Nov 28, 2022



Considering the spectral properties of images, we propose a new self-attention mechanism with highly reduced computational complexity, up to a linear rate. To better preserve edges while promoting similarity within objects, we propose individualized processes over different frequency bands. In particular, we study a case where the process is merely over low-frequency components. By ablation study, we show that low frequency self-attention can achieve very close or better performance relative to full frequency even without retraining the network. Accordingly, we design and embed novel plug-and-play modules to the head of a CNN network that we refer to as FsaNet. The frequency self-attention 1) takes low frequency coefficients as input, 2) can be mathematically equivalent to spatial domain self-attention with linear structures, 3) simplifies token mapping ($1\times1$ convolution) stage and token mixing stage simultaneously. We show that the frequency self-attention requires $87.29\% \sim 90.04\%$ less memory, $96.13\% \sim 98.07\%$ less FLOPs, and $97.56\% \sim 98.18\%$ in run time than the regular self-attention. Compared to other ResNet101-based self-attention networks, FsaNet achieves a new state-of-the-art result ($83.0\%$ mIoU) on Cityscape test dataset and competitive results on ADE20k and VOCaug.