 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerendipitous Recommendation with Multimodal LLM
Jun 09, 2025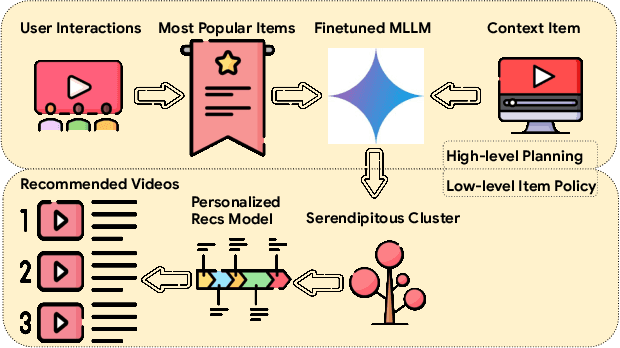
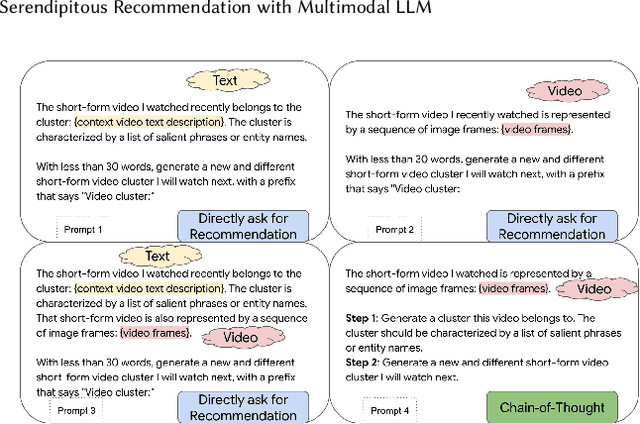
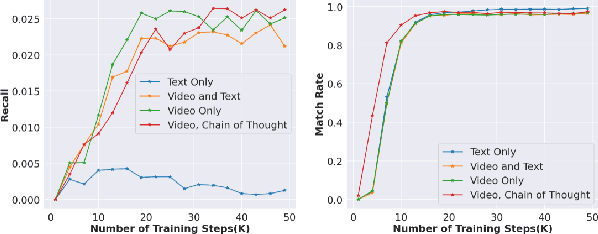
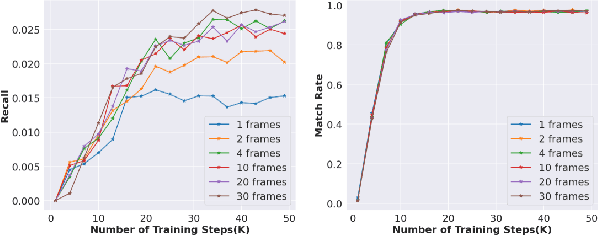
Conventional recommendation systems succeed in identifying relevant content but often fail to provide users with surprising or novel items. Multimodal Large Language Models (MLLMs) possess the world knowledge and multimodal understanding needed for serendipity, but their integration into billion-item-scale platforms presents significant challenges. In this paper, we propose a novel hierarchical framework where fine-tuned MLLMs provide high-level guidance to conventional recommendation models, steering them towards more serendipitous suggestions. This approach leverages MLLM strengths in understanding multimodal content and user interests while retaining the efficiency of traditional models for item-level recommendation. This mitigates the complexity of applying MLLMs directly to vast action spaces. We also demonstrate a chain-of-thought strategy enabling MLLMs to discover novel user interests by first understanding video content and then identifying relevant yet unexplored interest clusters. Through live experiments within a commercial short-form video platform serving billions of users, we show that our MLLM-powered approach significantly improves both recommendation serendipity and user satisfaction.
Ocean-OCR: Towards General OCR Application via a Vision-Language Model
Jan 26, 2025



Multimodal large language models (MLLMs) have shown impressive capabilities across various domains, excelling in processing and understanding information from multiple modalities. Despite the rapid progress made previously, insufficient OCR ability hinders MLLMs from excelling in text-related tasks. In this paper, we present \textbf{Ocean-OCR}, a 3B MLLM with state-of-the-art performance on various OCR scenarios and comparable understanding ability on general tasks. We employ Native Resolution ViT to enable variable resolution input and utilize a substantial collection of high-quality OCR datasets to enhance the model performance. We demonstrate the superiority of Ocean-OCR through comprehensive experiments on open-source OCR benchmarks and across various OCR scenarios. These scenarios encompass document understanding, scene text recognition, and handwritten recognition, highlighting the robust OCR capabilities of Ocean-OCR. Note that Ocean-OCR is the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Large-Scale Sparse Principal Component Analysis with Application to Text Data
Oct 26, 2012



Sparse PCA provides a linear combination of small number of features that maximizes variance across data. Although Sparse PCA has apparent advantages compared to PCA, such as better interpretability, it is generally thought to be computationally much more expensive. In this paper, we demonstrate the surprising fact that sparse PCA can be easier than PCA in practice, and that it can be reliably applied to very large data sets. This comes from a rigorous feature elimination pre-processing result, coupled with the favorable fact that features in real-life data typically have exponentially decreasing variances, which allows for many features to be eliminated. We introduce a fast block coordinate ascent algorithm with much better computational complexity than the existing first-order ones. We provide experimental results obtained on text corpora involving millions of documents and hundreds of thousands of features. These results illustrate how Sparse PCA can help organize a large corpus of text data in a user-interpretable way, providing an attractive alternative approach to topic models.