 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextReasoningBench: Does Reasoning Really Improve Text Classification in Large Language Models?
Mar 20, 2026Eliciting explicit, step-by-step reasoning traces from large language models (LLMs) has emerged as a dominant paradigm for enhancing model capabilities. Although such reasoning strategies were originally designed for problems requiring explicit multi-step reasoning, they have increasingly been applied to a broad range of NLP tasks. This expansion implicitly assumes that deliberative reasoning uniformly benefits heterogeneous tasks. However, whether such reasoning mechanisms truly benefit classification tasks remains largely underexplored, especially considering their substantial token and time costs. To fill this gap, we introduce TextReasoningBench, a systematic benchmark designed to evaluate the effectiveness and efficiency of reasoning strategies for text classification with LLMs. We compare seven reasoning strategies, namely IO, CoT, SC-CoT, ToT, GoT, BoC, and long-CoT across ten LLMs on five text classification datasets. Beyond traditional metrics such as accuracy and macro-F1, we introduce two cost-aware evaluation metrics that quantify the performance gain per reasoning token and the efficiency of performance improvement relative to token cost growth. Experimental results reveal three notable findings: (1) Reasoning does not universally improve classification performance: while moderate strategies such as CoT and SC-CoT yield consistent but limited gains (typically +1% to +3% on big models), more complex methods (e.g., ToT and GoT) often fail to outperform simpler baselines and can even degrade performance, especially on small models; (2) Reasoning is often inefficient: many reasoning strategies increase token consumption by 10$\times$ to 100$\times$ (e.g., SC-CoT and ToT) while providing only marginal performance improvements.
GenVideoLens: Where LVLMs Fall Short in AI-Generated Video Detection?
Mar 19, 2026In recent years, AI-generated videos have become increasingly realistic and sophisticated. Meanwhile, Large Vision-Language Models (LVLMs) have shown strong potential for detecting such content. However, existing evaluation protocols largely treat the task as a binary classification problem and rely on coarse-grained metrics such as overall accuracy, providing limited insight into where LVLMs succeed or fail. To address this limitation, we introduce GenVideoLens, a fine-grained benchmark that enables dimension-wise evaluation of LVLM capabilities in AI-generated video detection. The benchmark contains 400 highly deceptive AI-generated videos and 100 real videos, annotated by experts across 15 authenticity dimensions covering perceptual, optical, physical, and temporal cues. We evaluate eleven representative LVLMs on this benchmark. Our analysis reveals a pronounced dimensional imbalance. While LVLMs perform relatively well on perceptual cues, they struggle with optical consistency, physical interactions, and temporal-causal reasoning. Model performance also varies substantially across dimensions, with smaller open-source models sometimes outperforming stronger proprietary models on specific authenticity cues. Temporal perturbation experiments further show that current LVLMs make limited use of temporal information. Overall, GenVideoLens provides diagnostic insights into LVLM behavior, revealing key capability gaps and offering guidance for improving future AI-generated video detection systems.
Near-Field Positioning for XL-MIMO Uniform Circular Arrays: An Attention-Enhanced Deep Learning Approach
Jan 29, 2026In the evolving landscape of sixth-generation (6G) mobile communication, multiple-input multiple-output (MIMO) systems are incorporating an unprecedented number of antenna elements, advancing towards Extremely large-scale multiple-input-multiple-output (XL-MIMO) systems. This enhancement significantly increases the spatial degrees of freedom, offering substantial benefits for wireless positioning. However, the expansion of the near-field range in XL-MIMO challenges the traditional far-field assumptions used in previous MIMO models. Among various configurations, uniform circular arrays (UCAs) demonstrate superior performance by maintaining constant angular resolution, unlike linear planar arrays. Addressing how to leverage the expanded aperture and harness the near-field effects in XL-MIMO systems remains an area requiring further investigation. In this paper, we introduce an attention-enhanced deep learning approach for precise positioning. We employ a dual-path channel attention mechanism and a spatial attention mechanism to effectively integrate channel-level and spatial-level features. Our comprehensive simulations show that this model surpasses existing benchmarks such as attention-based positioning networks (ABPN), near-field positioning networks (NFLnet), convolutional neural networks (CNN), and multilayer perceptrons (MLP). The proposed model achieves superior positioning accuracy by utilizing covariance metrics of the input signal. Also, simulation results reveal that covariance metric is advantageous for positioning over channel state information (CSI) in terms of positioning accuracy and model efficiency.
Dynamic Channel Charting: An LSTM-AE-based Approach
Jan 26, 2026With the development of the sixth-generation (6G) communication system, Channel State Information (CSI) plays a crucial role in improving network performance. Traditional Channel Charting (CC) methods map high-dimensional CSI data to low-dimensional spaces to help reveal the geometric structure of wireless channels. However, most existing CC methods focus on learning static geometric structures and ignore the dynamic nature of the channel over time, leading to instability and poor topological consistency of the channel charting in complex environments. To address this issue, this paper proposes a novel time-series channel charting approach based on the integration of Long Short-Term Memory (LSTM) networks and Auto encoders (AE) (LSTM-AE-CC). This method incorporates a temporal modeling mechanism into the traditional CC framework, capturing temporal dependencies in CSI using LSTM and learning continuous latent representations with AE. The proposed method ensures both geometric consistency of the channel and explicit modeling of the time-varying properties. Experimental results demonstrate that the proposed method outperforms traditional CC methods in various real-world communication scenarios, particularly in terms of channel charting stability, trajectory continuity, and long-term predictability.
Efficient UAV trajectory prediction: A multi-modal deep diffusion framework
Jan 26, 2026To meet the requirements for managing unauthorized UAVs in the low-altitude economy, a multi-modal UAV trajectory prediction method based on the fusion of LiDAR and millimeter-wave radar information is proposed. A deep fusion network for multi-modal UAV trajectory prediction, termed the Multi-Modal Deep Fusion Framework, is designed. The overall architecture consists of two modality-specific feature extraction networks and a bidirectional cross-attention fusion module, aiming to fully exploit the complementary information of LiDAR and radar point clouds in spatial geometric structure and dynamic reflection characteristics. In the feature extraction stage, the model employs independent but structurally identical feature encoders for LiDAR and radar. After feature extraction, the model enters the Bidirectional Cross-Attention Mechanism stage to achieve information complementarity and semantic alignment between the two modalities. To verify the effectiveness of the proposed model, the MMAUD dataset used in the CVPR 2024 UG2+ UAV Tracking and Pose-Estimation Challenge is adopted as the training and testing dataset. Experimental results show that the proposed multi-modal fusion model significantly improves trajectory prediction accuracy, achieving a 40% improvement compared to the baseline model. In addition, ablation experiments are conducted to demonstrate the effectiveness of different loss functions and post-processing strategies in improving model performance. The proposed model can effectively utilize multi-modal data and provides an efficient solution for unauthorized UAV trajectory prediction in the low-altitude economy.
Ocean-OCR: Towards General OCR Application via a Vision-Language Model
Jan 26, 2025



Multimodal large language models (MLLMs) have shown impressive capabilities across various domains, excelling in processing and understanding information from multiple modalities. Despite the rapid progress made previously, insufficient OCR ability hinders MLLMs from excelling in text-related tasks. In this paper, we present \textbf{Ocean-OCR}, a 3B MLLM with state-of-the-art performance on various OCR scenarios and comparable understanding ability on general tasks. We employ Native Resolution ViT to enable variable resolution input and utilize a substantial collection of high-quality OCR datasets to enhance the model performance. We demonstrate the superiority of Ocean-OCR through comprehensive experiments on open-source OCR benchmarks and across various OCR scenarios. These scenarios encompass document understanding, scene text recognition, and handwritten recognition, highlighting the robust OCR capabilities of Ocean-OCR. Note that Ocean-OCR is the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR.
AI-driven Wireless Positioning: Fundamentals, Standards, State-of-the-art, and Challenges
Jan 24, 2025



Wireless positioning technologies hold significant value for applications in autonomous driving, extended reality (XR), unmanned aerial vehicles (UAVs), and more. With the advancement of artificial intelligence (AI), leveraging AI to enhance positioning accuracy and robustness has emerged as a field full of potential. Driven by the requirements and functionalities defined in the 3rd Generation Partnership Project (3GPP) standards, AI/machine learning (ML)-based positioning is becoming a key technology to overcome the limitations of traditional methods. This paper begins with an introduction to the fundamentals of AI and wireless positioning, covering AI models, algorithms, positioning applications, emerging wireless technologies, and the basics of positioning techniques. Subsequently, focusing on standardization progress, we provide a comprehensive review of the evolution of 3GPP positioning standards, with an emphasis on the integration of AI/ML technologies in recent and upcoming releases. Based on the AI/ML-assisted positioning and direct AI/ML positioning schemes outlined in the standards, we conduct an in-depth investigation of related research. we focus on state-of-the-art (SOTA) research in AI-based line-of-sight (LOS)/non-line-of-sight (NLOS) detection, time of arrival (TOA)/time difference of arrival (TDOA) estimation, and angle estimation techniques. For Direct AI/ML Positioning, we explore SOTA advancements in fingerprint-based positioning, knowledge-assisted AI positioning, and channel charting-based positioning. Furthermore, we introduce publicly available datasets for wireless positioning and conclude by summarizing the challenges and opportunities of AI-driven wireless positioning.
DEYOLO: Dual-Feature-Enhancement YOLO for Cross-Modality Object Detection
Dec 06, 2024Object detection in poor-illumination environments is a challenging task as objects are usually not clearly visible in RGB images. As infrared images provide additional clear edge information that complements RGB images, fusing RGB and infrared images has potential to enhance the detection ability in poor-illumination environments. However, existing works involving both visible and infrared images only focus on image fusion, instead of object detection. Moreover, they directly fuse the two kinds of image modalities, which ignores the mutual interference between them. To fuse the two modalities to maximize the advantages of cross-modality, we design a dual-enhancement-based cross-modality object detection network DEYOLO, in which semantic-spatial cross modality and novel bi-directional decoupled focus modules are designed to achieve the detection-centered mutual enhancement of RGB-infrared (RGB-IR). Specifically, a dual semantic enhancing channel weight assignment module (DECA) and a dual spatial enhancing pixel weight assignment module (DEPA) are firstly proposed to aggregate cross-modality information in the feature space to improve the feature representation ability, such that feature fusion can aim at the object detection task. Meanwhile, a dual-enhancement mechanism, including enhancements for two-modality fusion and single modality, is designed in both DECAand DEPAto reduce interference between the two kinds of image modalities. Then, a novel bi-directional decoupled focus is developed to enlarge the receptive field of the backbone network in different directions, which improves the representation quality of DEYOLO. Extensive experiments on M3FD and LLVIP show that our approach outperforms SOTA object detection algorithms by a clear margin. Our code is available at https://github.com/chips96/DEYOLO.
Beyond the Eye: A Relational Model for Early Dementia Detection Using Retinal OCTA Images
Aug 09, 2024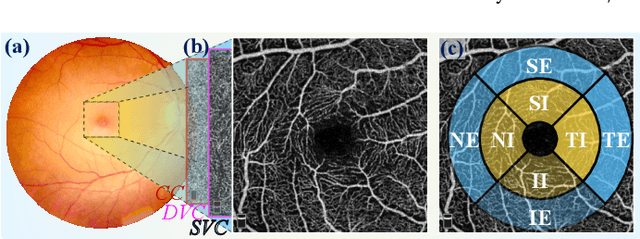
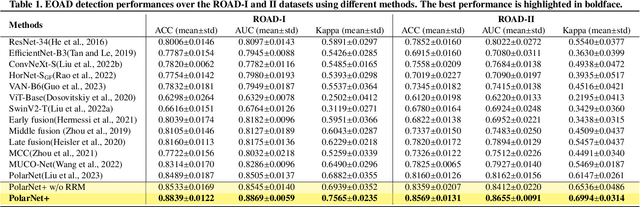

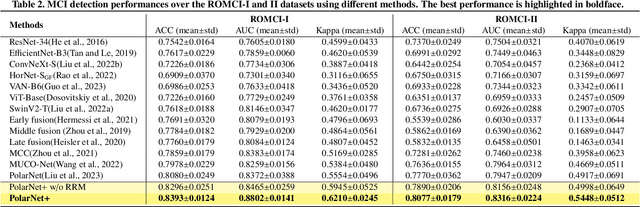
Early detection of dementia, such as Alzheimer's disease (AD) or mild cognitive impairment (MCI), is essential to enable timely intervention and potential treatment. Accurate detection of AD/MCI is challenging due to the high complexity, cost, and often invasive nature of current diagnostic techniques, which limit their suitability for large-scale population screening. Given the shared embryological origins and physiological characteristics of the retina and brain, retinal imaging is emerging as a potentially rapid and cost-effective alternative for the identification of individuals with or at high risk of AD. In this paper, we present a novel PolarNet+ that uses retinal optical coherence tomography angiography (OCTA) to discriminate early-onset AD (EOAD) and MCI subjects from controls. Our method first maps OCTA images from Cartesian coordinates to polar coordinates, allowing approximate sub-region calculation to implement the clinician-friendly early treatment of diabetic retinopathy study (ETDRS) grid analysis. We then introduce a multi-view module to serialize and analyze the images along three dimensions for comprehensive, clinically useful information extraction. Finally, we abstract the sequence embedding into a graph, transforming the detection task into a general graph classification problem. A regional relationship module is applied after the multi-view module to excavate the relationship between the sub-regions. Such regional relationship analyses validate known eye-brain links and reveal new discriminative patterns.
A Neural Matrix Decomposition Recommender System Model based on the Multimodal Large Language Model
Jul 12, 2024


Recommendation systems have become an important solution to information search problems. This article proposes a neural matrix factorization recommendation system model based on the multimodal large language model called BoNMF. This model combines BoBERTa's powerful capabilities in natural language processing, ViT in computer in vision, and neural matrix decomposition technology. By capturing the potential characteristics of users and items, and after interacting with a low-dimensional matrix composed of user and item IDs, the neural network outputs the results. recommend. Cold start and ablation experimental results show that the BoNMF model exhibits excellent performance on large public data sets and significantly improves the accuracy of recommendations.