 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Eye: A Relational Model for Early Dementia Detection Using Retinal OCTA Images
Aug 09, 2024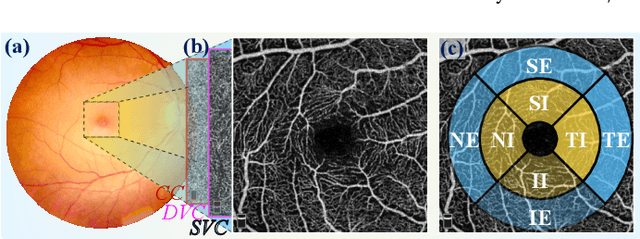
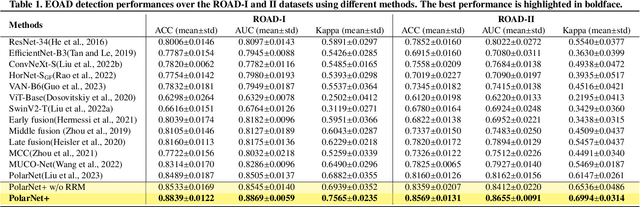

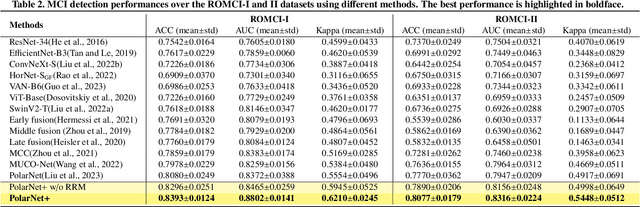
Early detection of dementia, such as Alzheimer's disease (AD) or mild cognitive impairment (MCI), is essential to enable timely intervention and potential treatment. Accurate detection of AD/MCI is challenging due to the high complexity, cost, and often invasive nature of current diagnostic techniques, which limit their suitability for large-scale population screening. Given the shared embryological origins and physiological characteristics of the retina and brain, retinal imaging is emerging as a potentially rapid and cost-effective alternative for the identification of individuals with or at high risk of AD. In this paper, we present a novel PolarNet+ that uses retinal optical coherence tomography angiography (OCTA) to discriminate early-onset AD (EOAD) and MCI subjects from controls. Our method first maps OCTA images from Cartesian coordinates to polar coordinates, allowing approximate sub-region calculation to implement the clinician-friendly early treatment of diabetic retinopathy study (ETDRS) grid analysis. We then introduce a multi-view module to serialize and analyze the images along three dimensions for comprehensive, clinically useful information extraction. Finally, we abstract the sequence embedding into a graph, transforming the detection task into a general graph classification problem. A regional relationship module is applied after the multi-view module to excavate the relationship between the sub-regions. Such regional relationship analyses validate known eye-brain links and reveal new discriminative patterns.
M3KE: A Massive Multi-Level Multi-Subject Knowledge Evaluation Benchmark for Chinese Large Language Models
May 21, 2023



Large language models have recently made tremendous progress in a variety of aspects, e.g., cross-task generalization, instruction following. Comprehensively evaluating the capability of large language models in multiple tasks is of great importance. In this paper, we propose M3KE, a Massive Multi-Level Multi-Subject Knowledge Evaluation benchmark, which is developed to measure knowledge acquired by Chinese large language models by testing their multitask accuracy in zero- and few-shot settings. We have collected 20,477 questions from 71 tasks. Our selection covers all major levels of Chinese education system, ranging from the primary school to college, as well as a wide variety of subjects, including humanities, history, politics, law, education, psychology, science, technology, art and religion. All questions are multiple-choice questions with four options, hence guaranteeing a standardized and unified assessment process. We've assessed a number of state-of-the-art open-source Chinese large language models on the proposed benchmark. The size of these models varies from 335M to 130B parameters. Experiment results demonstrate that they perform significantly worse than GPT-3.5 that reaches an accuracy of ~ 48% on M3KE. The dataset is available at https://github.com/tjunlp-lab/M3KE.