 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Eye: A Relational Model for Early Dementia Detection Using Retinal OCTA Images
Aug 09, 2024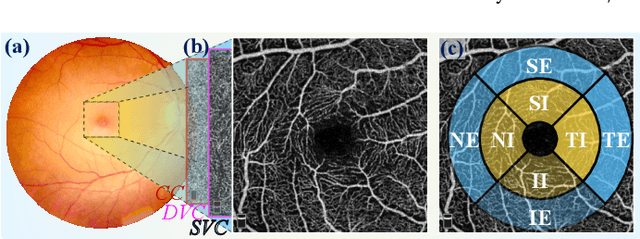
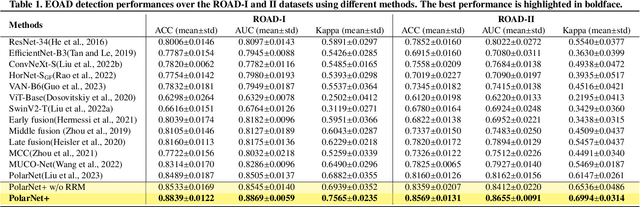

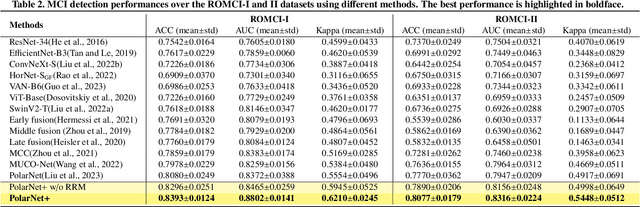
Early detection of dementia, such as Alzheimer's disease (AD) or mild cognitive impairment (MCI), is essential to enable timely intervention and potential treatment. Accurate detection of AD/MCI is challenging due to the high complexity, cost, and often invasive nature of current diagnostic techniques, which limit their suitability for large-scale population screening. Given the shared embryological origins and physiological characteristics of the retina and brain, retinal imaging is emerging as a potentially rapid and cost-effective alternative for the identification of individuals with or at high risk of AD. In this paper, we present a novel PolarNet+ that uses retinal optical coherence tomography angiography (OCTA) to discriminate early-onset AD (EOAD) and MCI subjects from controls. Our method first maps OCTA images from Cartesian coordinates to polar coordinates, allowing approximate sub-region calculation to implement the clinician-friendly early treatment of diabetic retinopathy study (ETDRS) grid analysis. We then introduce a multi-view module to serialize and analyze the images along three dimensions for comprehensive, clinically useful information extraction. Finally, we abstract the sequence embedding into a graph, transforming the detection task into a general graph classification problem. A regional relationship module is applied after the multi-view module to excavate the relationship between the sub-regions. Such regional relationship analyses validate known eye-brain links and reveal new discriminative patterns.
Polar-Net: A Clinical-Friendly Model for Alzheimer's Disease Detection in OCTA Images
Nov 10, 2023Optical Coherence Tomography Angiography (OCTA) is a promising tool for detecting Alzheimer's disease (AD) by imaging the retinal microvasculature. Ophthalmologists commonly use region-based analysis, such as the ETDRS grid, to study OCTA image biomarkers and understand the correlation with AD. However, existing studies have used general deep computer vision methods, which present challenges in providing interpretable results and leveraging clinical prior knowledge. To address these challenges, we propose a novel deep-learning framework called Polar-Net. Our approach involves mapping OCTA images from Cartesian coordinates to polar coordinates, which allows for the use of approximate sector convolution and enables the implementation of the ETDRS grid-based regional analysis method commonly used in clinical practice. Furthermore, Polar-Net incorporates clinical prior information of each sector region into the training process, which further enhances its performance. Additionally, our framework adapts to acquire the importance of the corresponding retinal region, which helps researchers and clinicians understand the model's decision-making process in detecting AD and assess its conformity to clinical observations. Through evaluations on private and public datasets, we have demonstrated that Polar-Net outperforms existing state-of-the-art methods and provides more valuable pathological evidence for the association between retinal vascular changes and AD. In addition, we also show that the two innovative modules introduced in our framework have a significant impact on improving overall performance.
SR-GNN: Spatial Relation-aware Graph Neural Network for Fine-Grained Image Categorization
Sep 05, 2022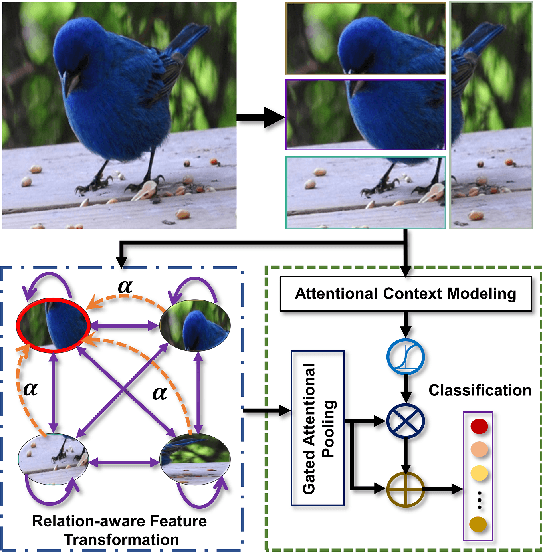
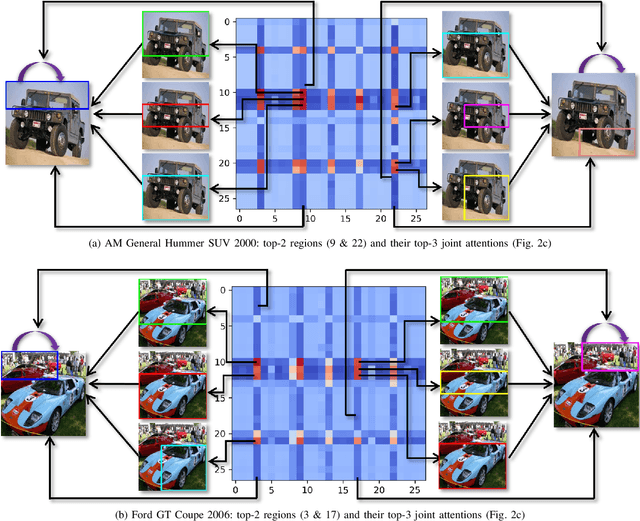
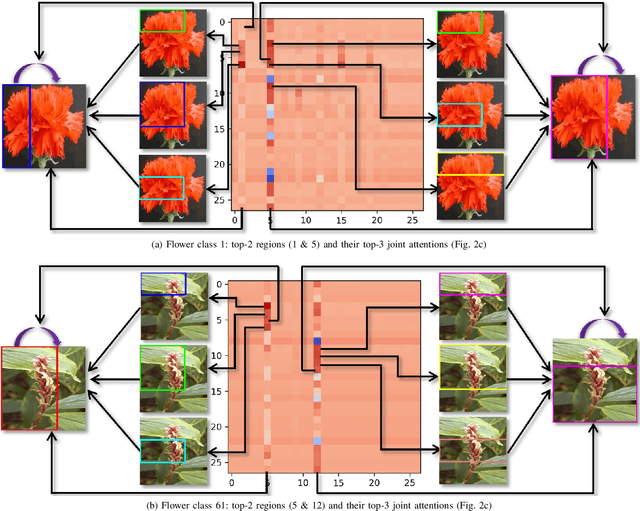
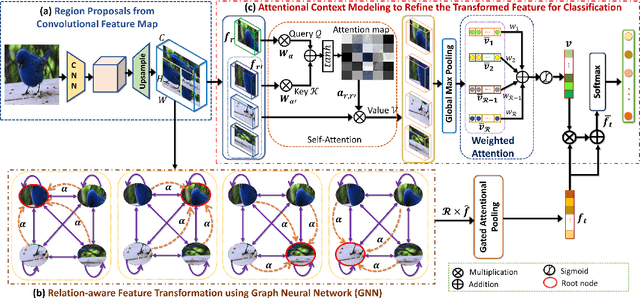
Over the past few years, a significant progress has been made in deep convolutional neural networks (CNNs)-based image recognition. This is mainly due to the strong ability of such networks in mining discriminative object pose and parts information from texture and shape. This is often inappropriate for fine-grained visual classification (FGVC) since it exhibits high intra-class and low inter-class variances due to occlusions, deformation, illuminations, etc. Thus, an expressive feature representation describing global structural information is a key to characterize an object/ scene. To this end, we propose a method that effectively captures subtle changes by aggregating context-aware features from most relevant image-regions and their importance in discriminating fine-grained categories avoiding the bounding-box and/or distinguishable part annotations. Our approach is inspired by the recent advancement in self-attention and graph neural networks (GNNs) approaches to include a simple yet effective relation-aware feature transformation and its refinement using a context-aware attention mechanism to boost the discriminability of the transformed feature in an end-to-end learning process. Our model is evaluated on eight benchmark datasets consisting of fine-grained objects and human-object interactions. It outperforms the state-of-the-art approaches by a significant margin in recognition accuracy.
Retinal Structure Detection in OCTA Image via Voting-based Multi-task Learning
Aug 23, 2022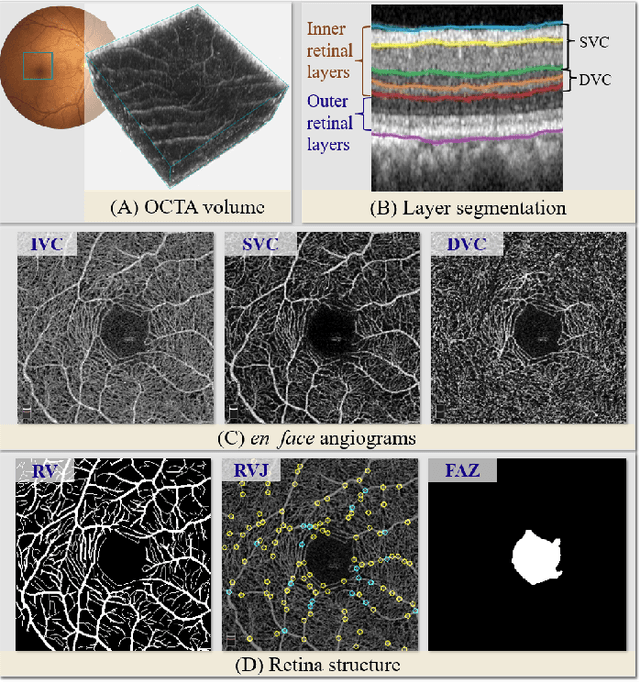
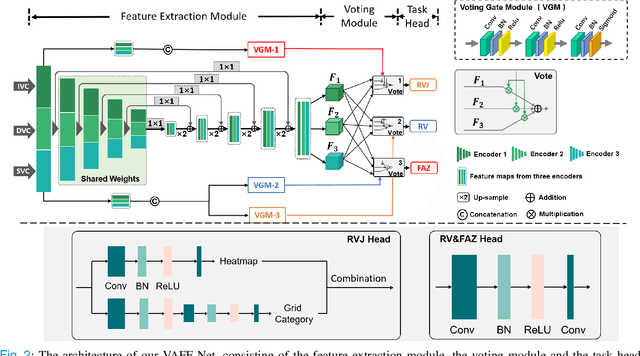
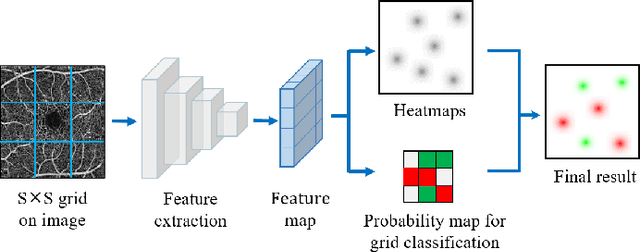
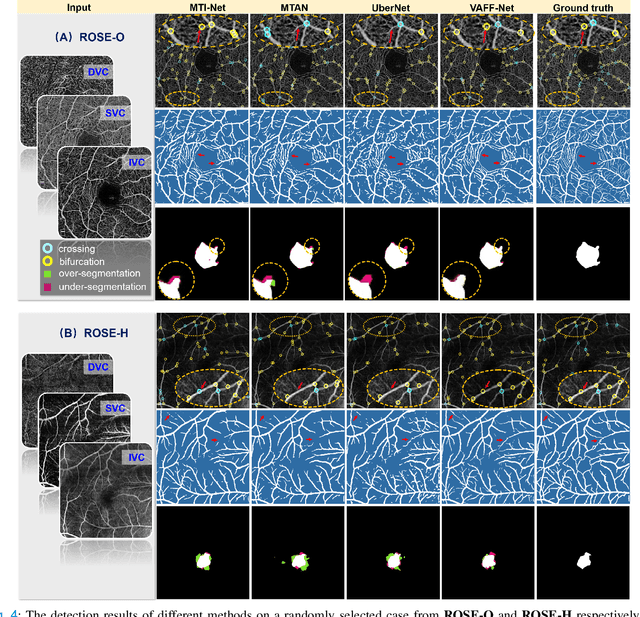
Automated detection of retinal structures, such as retinal vessels (RV), the foveal avascular zone (FAZ), and retinal vascular junctions (RVJ), are of great importance for understanding diseases of the eye and clinical decision-making. In this paper, we propose a novel Voting-based Adaptive Feature Fusion multi-task network (VAFF-Net) for joint segmentation, detection, and classification of RV, FAZ, and RVJ in optical coherence tomography angiography (OCTA). A task-specific voting gate module is proposed to adaptively extract and fuse different features for specific tasks at two levels: features at different spatial positions from a single encoder, and features from multiple encoders. In particular, since the complexity of the microvasculature in OCTA images makes simultaneous precise localization and classification of retinal vascular junctions into bifurcation/crossing a challenging task, we specifically design a task head by combining the heatmap regression and grid classification. We take advantage of three different \textit{en face} angiograms from various retinal layers, rather than following existing methods that use only a single \textit{en face}. To facilitate further research, part of these datasets with the source code and evaluation benchmark have been released for public access:https://github.com/iMED-Lab/VAFF-Net.
Attend and Guide : A Keypoints-driven Attention-based Deep Network for Image Recognition
Oct 23, 2021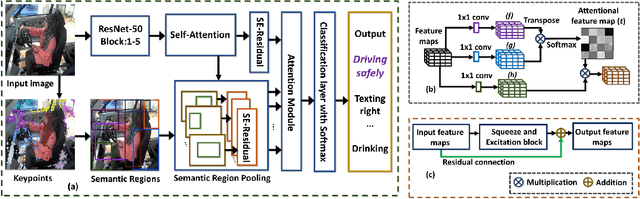
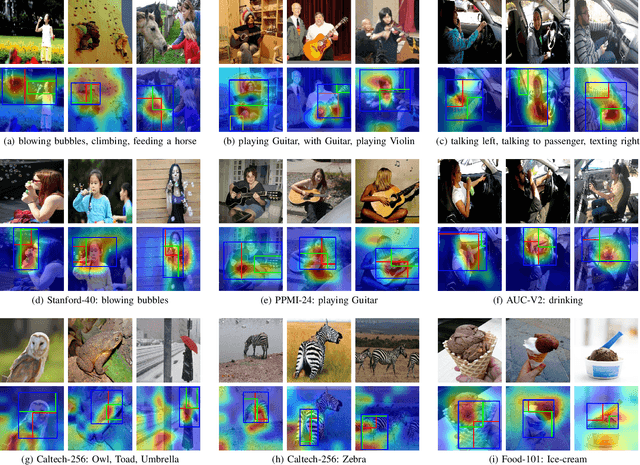


This paper presents a novel keypoints-based attention mechanism for visual recognition in still images. Deep Convolutional Neural Networks (CNNs) for recognizing images with distinctive classes have shown great success, but their performance in discriminating fine-grained changes is not at the same level. We address this by proposing an end-to-end CNN model, which learns meaningful features linking fine-grained changes using our novel attention mechanism. It captures the spatial structures in images by identifying semantic regions (SRs) and their spatial distributions, and is proved to be the key to modelling subtle changes in images. We automatically identify these SRs by grouping the detected keypoints in a given image. The ``usefulness'' of these SRs for image recognition is measured using our innovative attentional mechanism focusing on parts of the image that are most relevant to a given task. This framework applies to traditional and fine-grained image recognition tasks and does not require manually annotated regions (e.g. bounding-box of body parts, objects, etc.) for learning and prediction. Moreover, the proposed keypoints-driven attention mechanism can be easily integrated into the existing CNN models. The framework is evaluated on six diverse benchmark datasets. The model outperforms the state-of-the-art approaches by a considerable margin using Distracted Driver V1 (Acc: 3.39%), Distracted Driver V2 (Acc: 6.58%), Stanford-40 Actions (mAP: 2.15%), People Playing Musical Instruments (mAP: 16.05%), Food-101 (Acc: 6.30%) and Caltech-256 (Acc: 2.59%) datasets.
* Published in IEEE Transaction on Image Processing 2021, Vol. 30, pp. 3691 - 3704
Coarse Temporal Attention Network (CTA-Net) for Driver's Activity Recognition
Jan 17, 2021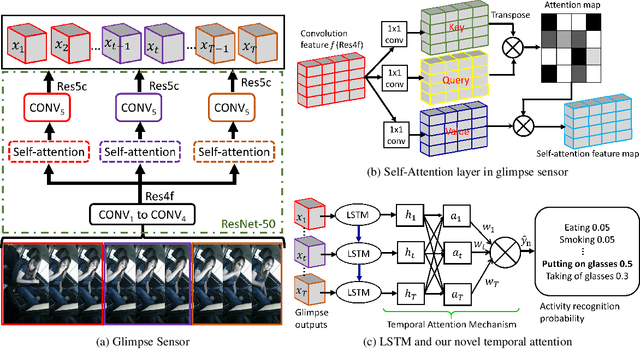
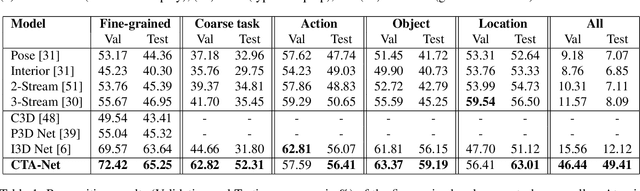

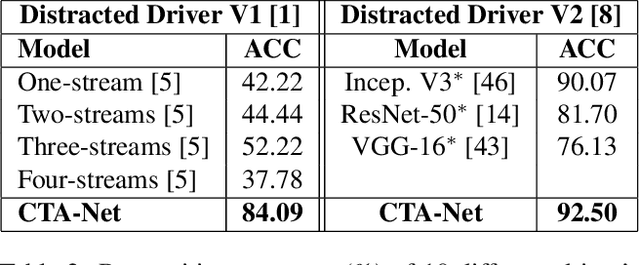
There is significant progress in recognizing traditional human activities from videos focusing on highly distinctive actions involving discriminative body movements, body-object and/or human-human interactions. Driver's activities are different since they are executed by the same subject with similar body parts movements, resulting in subtle changes. To address this, we propose a novel framework by exploiting the spatiotemporal attention to model the subtle changes. Our model is named Coarse Temporal Attention Network (CTA-Net), in which coarse temporal branches are introduced in a trainable glimpse network. The goal is to allow the glimpse to capture high-level temporal relationships, such as 'during', 'before' and 'after' by focusing on a specific part of a video. These branches also respect the topology of the temporal dynamics in the video, ensuring that different branches learn meaningful spatial and temporal changes. The model then uses an innovative attention mechanism to generate high-level action specific contextual information for activity recognition by exploring the hidden states of an LSTM. The attention mechanism helps in learning to decide the importance of each hidden state for the recognition task by weighing them when constructing the representation of the video. Our approach is evaluated on four publicly accessible datasets and significantly outperforms the state-of-the-art by a considerable margin with only RGB video as input.
* Extended version of the accepted WACV 2021
FFD: Fast Feature Detector
Dec 01, 2020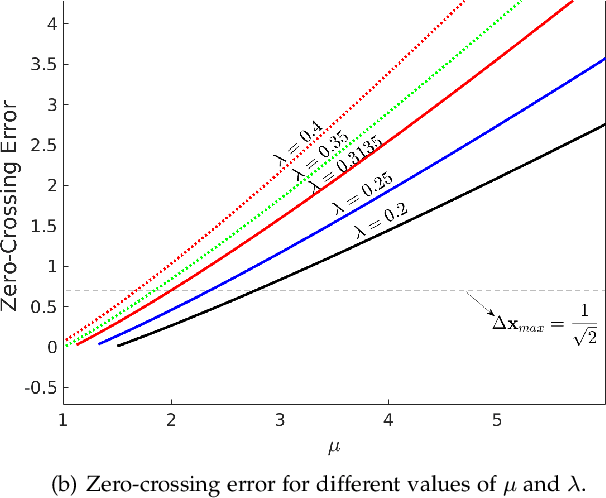
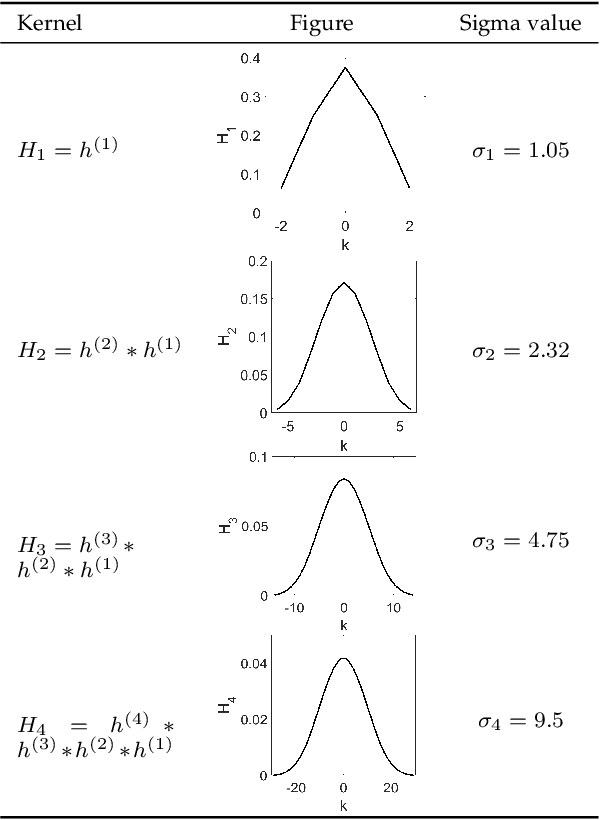
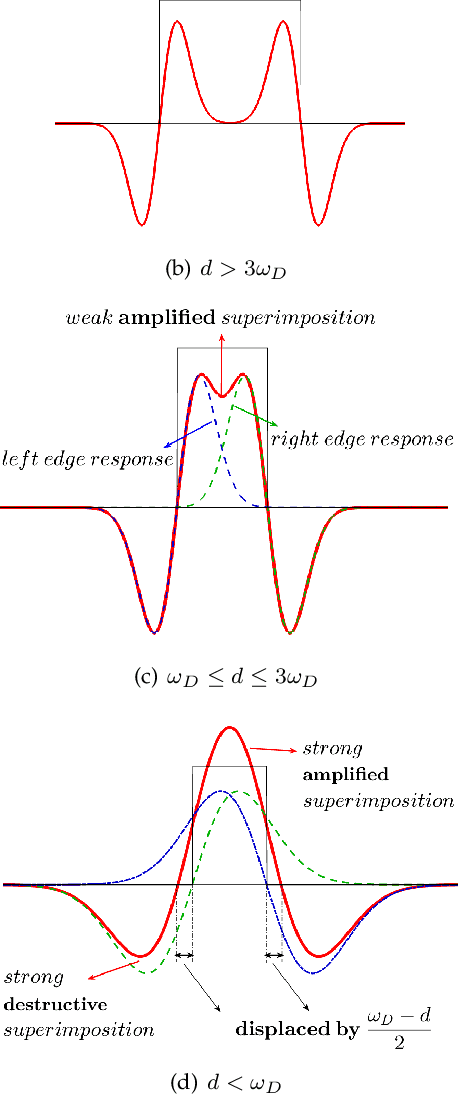

Scale-invariance, good localization and robustness to noise and distortions are the main properties that a local feature detector should possess. Most existing local feature detectors find excessive unstable feature points that increase the number of keypoints to be matched and the computational time of the matching step. In this paper, we show that robust and accurate keypoints exist in the specific scale-space domain. To this end, we first formulate the superimposition problem into a mathematical model and then derive a closed-form solution for multiscale analysis. The model is formulated via difference-of-Gaussian (DoG) kernels in the continuous scale-space domain, and it is proved that setting the scale-space pyramid's blurring ratio and smoothness to 2 and 0.627, respectively, facilitates the detection of reliable keypoints. For the applicability of the proposed model to discrete images, we discretize it using the undecimated wavelet transform and the cubic spline function. Theoretically, the complexity of our method is less than 5\% of that of the popular baseline Scale Invariant Feature Transform (SIFT). Extensive experimental results show the superiority of the proposed feature detector over the existing representative hand-crafted and learning-based techniques in accuracy and computational time. The code and supplementary materials can be found at~{\url{https://github.com/mogvision/FFD}}.
CS2-Net: Deep Learning Segmentation of Curvilinear Structures in Medical Imaging
Oct 19, 2020
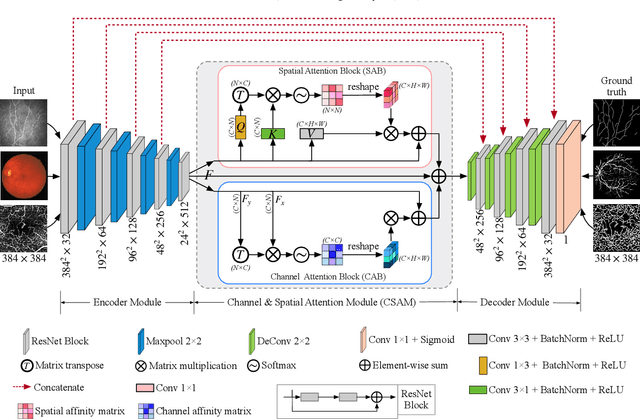
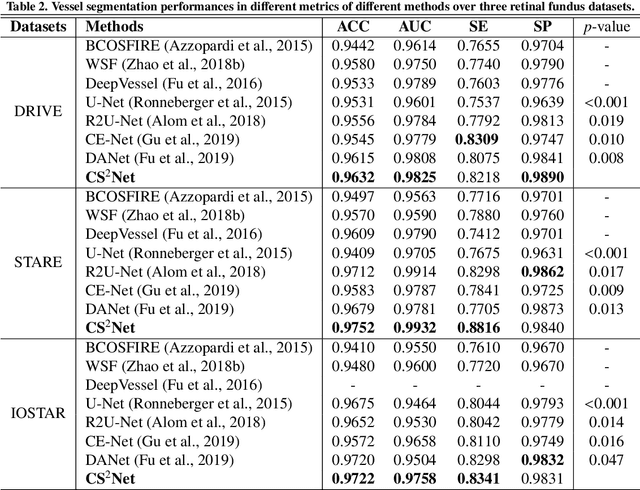
Automated detection of curvilinear structures, e.g., blood vessels or nerve fibres, from medical and biomedical images is a crucial early step in automatic image interpretation associated to the management of many diseases. Precise measurement of the morphological changes of these curvilinear organ structures informs clinicians for understanding the mechanism, diagnosis, and treatment of e.g. cardiovascular, kidney, eye, lung, and neurological conditions. In this work, we propose a generic and unified convolution neural network for the segmentation of curvilinear structures and illustrate in several 2D/3D medical imaging modalities. We introduce a new curvilinear structure segmentation network (CS2-Net), which includes a self-attention mechanism in the encoder and decoder to learn rich hierarchical representations of curvilinear structures. Two types of attention modules - spatial attention and channel attention - are utilized to enhance the inter-class discrimination and intra-class responsiveness, to further integrate local features with their global dependencies and normalization, adaptively. Furthermore, to facilitate the segmentation of curvilinear structures in medical images, we employ a 1x3 and a 3x1 convolutional kernel to capture boundary features. ...
Orderly Disorder in Point Cloud Domain
Aug 21, 2020
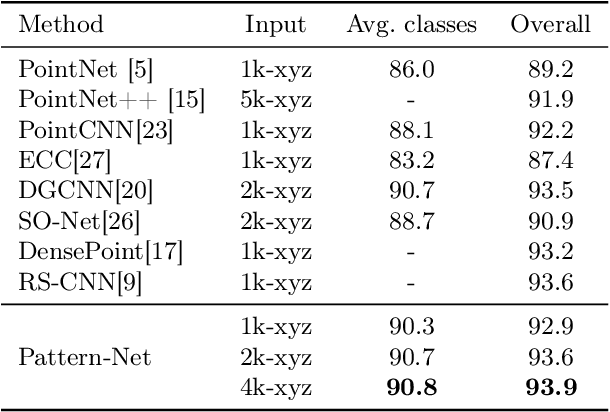
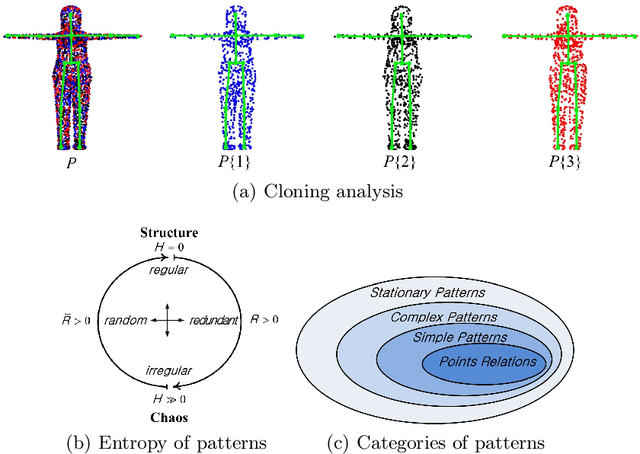
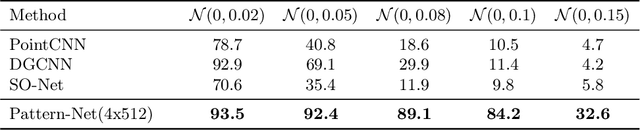
In the real world, out-of-distribution samples, noise and distortions exist in test data. Existing deep networks developed for point cloud data analysis are prone to overfitting and a partial change in test data leads to unpredictable behaviour of the networks. In this paper, we propose a smart yet simple deep network for analysis of 3D models using `orderly disorder' theory. Orderly disorder is a way of describing the complex structure of disorders within complex systems. Our method extracts the deep patterns inside a 3D object via creating a dynamic link to seek the most stable patterns and at once, throws away the unstable ones. Patterns are more robust to changes in data distribution, especially those that appear in the top layers. Features are extracted via an innovative cloning decomposition technique and then linked to each other to form stable complex patterns. Our model alleviates the vanishing-gradient problem, strengthens dynamic link propagation and substantially reduces the number of parameters. Extensive experiments on challenging benchmark datasets verify the superiority of our light network on the segmentation and classification tasks, especially in the presence of noise wherein our network's performance drops less than 10% while the state-of-the-art networks fail to work.