 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInpainting Normal Maps for Lightstage data
Jan 16, 2024This study introduces a novel method for inpainting normal maps using a generative adversarial network (GAN). Normal maps, often derived from a lightstage, are crucial in performance capture but can have obscured areas due to movement (e.g., by arms, hair, or props). Inpainting fills these missing areas with plausible data. Our approach extends previous general image inpainting techniques, employing a bow tie-like generator network and a discriminator network, with alternating training phases. The generator aims to synthesize images aligning with the ground truth and deceive the discriminator, which differentiates between real and processed images. Periodically, the discriminator undergoes retraining to enhance its ability to identify processed images. Importantly, our method adapts to the unique characteristics of normal map data, necessitating modifications to the loss function. We utilize a cosine loss instead of mean squared error loss for generator training. Limited training data availability, even with synthetic datasets, demands significant augmentation, considering the specific nature of the input data. This includes appropriate image flipping and in-plane rotations to accurately alter normal vectors. Throughout training, we monitored key metrics such as average loss, Structural Similarity Index Measure (SSIM), and Peak Signal-to-Noise Ratio (PSNR) for the generator, along with average loss and accuracy for the discriminator. Our findings suggest that the proposed model effectively generates high-quality, realistic inpainted normal maps, suitable for performance capture applications. These results establish a foundation for future research, potentially involving more advanced networks and comparisons with inpainting of source images used to create the normal maps.
* 8 pages, 4 figures, CGVC Conference, The Eurographics Association
FFD: Fast Feature Detector
Dec 01, 2020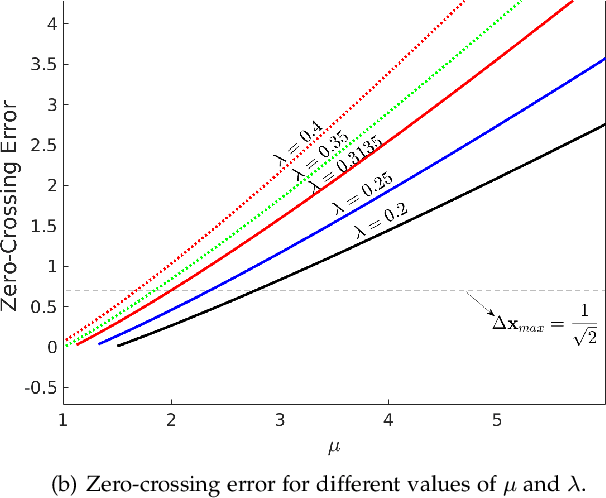
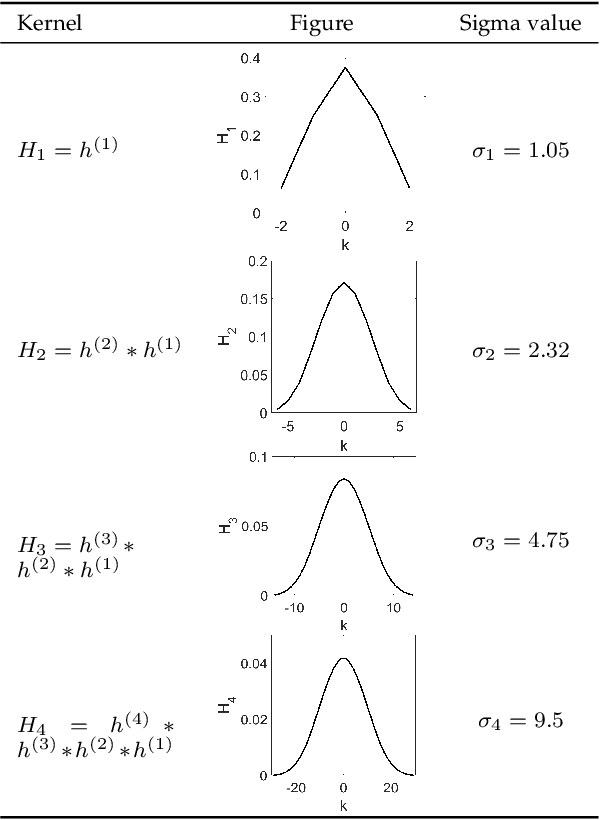
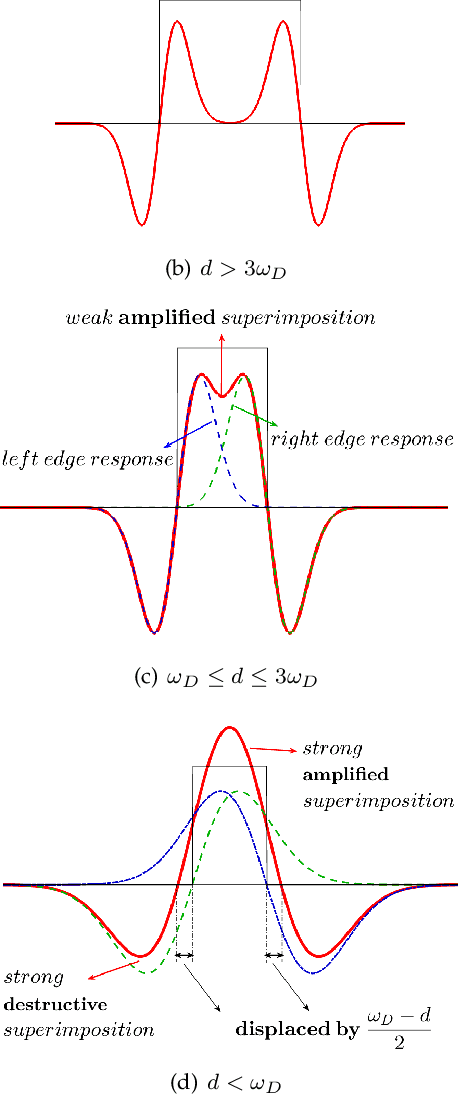

Scale-invariance, good localization and robustness to noise and distortions are the main properties that a local feature detector should possess. Most existing local feature detectors find excessive unstable feature points that increase the number of keypoints to be matched and the computational time of the matching step. In this paper, we show that robust and accurate keypoints exist in the specific scale-space domain. To this end, we first formulate the superimposition problem into a mathematical model and then derive a closed-form solution for multiscale analysis. The model is formulated via difference-of-Gaussian (DoG) kernels in the continuous scale-space domain, and it is proved that setting the scale-space pyramid's blurring ratio and smoothness to 2 and 0.627, respectively, facilitates the detection of reliable keypoints. For the applicability of the proposed model to discrete images, we discretize it using the undecimated wavelet transform and the cubic spline function. Theoretically, the complexity of our method is less than 5\% of that of the popular baseline Scale Invariant Feature Transform (SIFT). Extensive experimental results show the superiority of the proposed feature detector over the existing representative hand-crafted and learning-based techniques in accuracy and computational time. The code and supplementary materials can be found at~{\url{https://github.com/mogvision/FFD}}.
Orderly Disorder in Point Cloud Domain
Aug 21, 2020
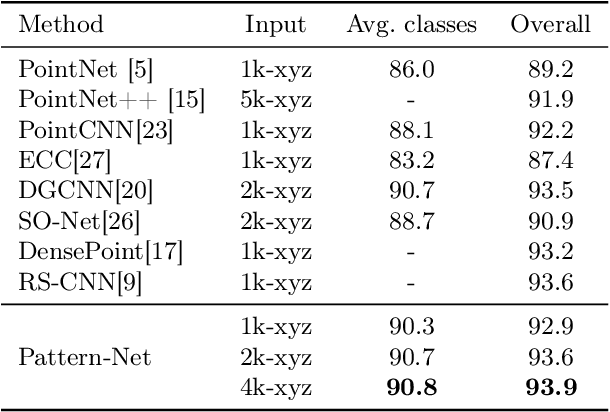
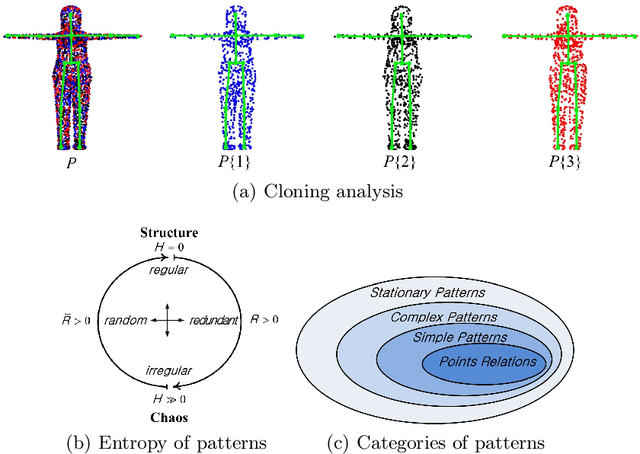
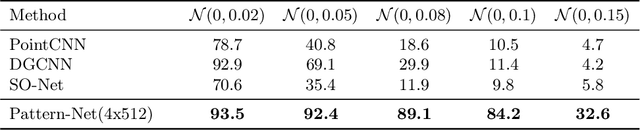
In the real world, out-of-distribution samples, noise and distortions exist in test data. Existing deep networks developed for point cloud data analysis are prone to overfitting and a partial change in test data leads to unpredictable behaviour of the networks. In this paper, we propose a smart yet simple deep network for analysis of 3D models using `orderly disorder' theory. Orderly disorder is a way of describing the complex structure of disorders within complex systems. Our method extracts the deep patterns inside a 3D object via creating a dynamic link to seek the most stable patterns and at once, throws away the unstable ones. Patterns are more robust to changes in data distribution, especially those that appear in the top layers. Features are extracted via an innovative cloning decomposition technique and then linked to each other to form stable complex patterns. Our model alleviates the vanishing-gradient problem, strengthens dynamic link propagation and substantially reduces the number of parameters. Extensive experiments on challenging benchmark datasets verify the superiority of our light network on the segmentation and classification tasks, especially in the presence of noise wherein our network's performance drops less than 10% while the state-of-the-art networks fail to work.
A Morphable Face Albedo Model
Apr 06, 2020



In this paper, we bring together two divergent strands of research: photometric face capture and statistical 3D face appearance modelling. We propose a novel lightstage capture and processing pipeline for acquiring ear-to-ear, truly intrinsic diffuse and specular albedo maps that fully factor out the effects of illumination, camera and geometry. Using this pipeline, we capture a dataset of 50 scans and combine them with the only existing publicly available albedo dataset (3DRFE) of 23 scans. This allows us to build the first morphable face albedo model. We believe this is the first statistical analysis of the variability of facial specular albedo maps. This model can be used as a plug in replacement for the texture model of the Basel Face Model and we make our new albedo model publicly available. We ensure careful spectral calibration such that our model is built in a linear sRGB space, suitable for inverse rendering of images taken by typical cameras. We demonstrate our model in a state of the art analysis-by-synthesis 3DMM fitting pipeline, are the first to integrate specular map estimation and outperform the Basel Face Model in albedo reconstruction.
Ear-to-ear Capture of Facial Intrinsics
Sep 08, 2016
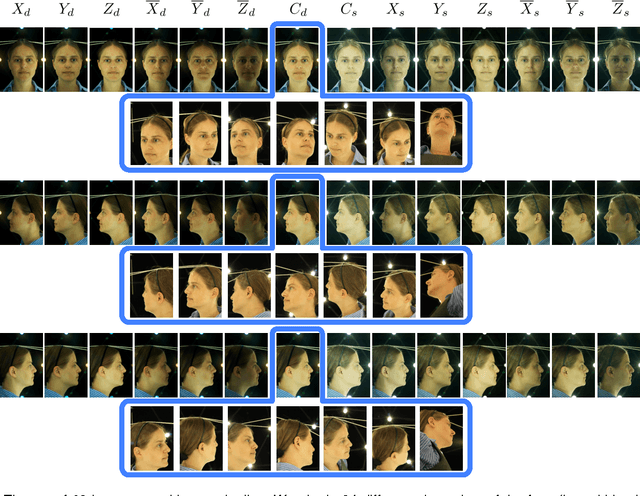


We present a practical approach to capturing ear-to-ear face models comprising both 3D meshes and intrinsic textures (i.e. diffuse and specular albedo). Our approach is a hybrid of geometric and photometric methods and requires no geometric calibration. Photometric measurements made in a lightstage are used to estimate view dependent high resolution normal maps. We overcome the problem of having a single photometric viewpoint by capturing in multiple poses. We use uncalibrated multiview stereo to estimate a coarse base mesh to which the photometric views are registered. We propose a novel approach to robustly stitching surface normal and intrinsic texture data into a seamless, complete and highly detailed face model. The resulting relightable models provide photorealistic renderings in any view.