 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVENI: Variational Encoder for Natural Illumination
Jan 20, 2026Inverse rendering is an ill-posed problem, but priors like illumination priors, can simplify it. Existing work either disregards the spherical and rotation-equivariant nature of illumination environments or does not provide a well-behaved latent space. We propose a rotation-equivariant variational autoencoder that models natural illumination on the sphere without relying on 2D projections. To preserve the SO(2)-equivariance of environment maps, we use a novel Vector Neuron Vision Transformer (VN-ViT) as encoder and a rotation-equivariant conditional neural field as decoder. In the encoder, we reduce the equivariance from SO(3) to SO(2) using a novel SO(2)-equivariant fully connected layer, an extension of Vector Neurons. We show that our SO(2)-equivariant fully connected layer outperforms standard Vector Neurons when used in our SO(2)-equivariant model. Compared to previous methods, our variational autoencoder enables smoother interpolation in latent space and offers a more well-behaved latent space.
iRBSM: A Deep Implicit 3D Breast Shape Model
Dec 17, 2024
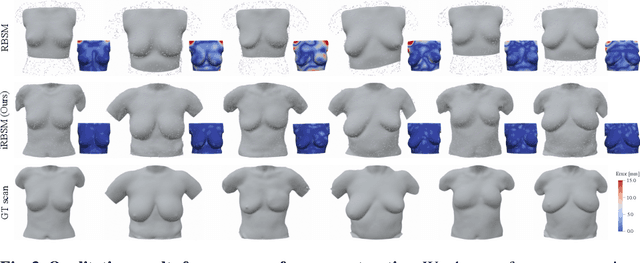
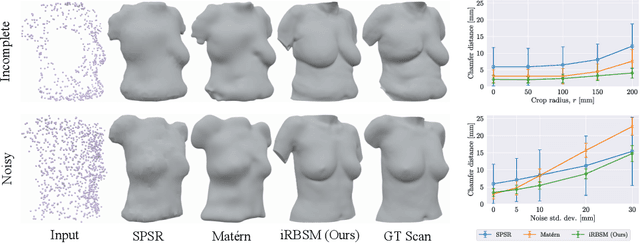
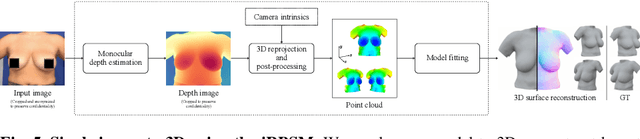
We present the first deep implicit 3D shape model of the female breast, building upon and improving the recently proposed Regensburg Breast Shape Model (RBSM). Compared to its PCA-based predecessor, our model employs implicit neural representations; hence, it can be trained on raw 3D breast scans and eliminates the need for computationally demanding non-rigid registration -- a task that is particularly difficult for feature-less breast shapes. The resulting model, dubbed iRBSM, captures detailed surface geometry including fine structures such as nipples and belly buttons, is highly expressive, and outperforms the RBSM on different surface reconstruction tasks. Finally, leveraging the iRBSM, we present a prototype application to 3D reconstruct breast shapes from just a single image. Model and code publicly available at https://rbsm.re-mic.de/implicit.
ProPLIKS: Probablistic 3D human body pose estimation
Dec 05, 2024

We present a novel approach for 3D human pose estimation by employing probabilistic modeling. This approach leverages the advantages of normalizing flows in non-Euclidean geometries to address uncertain poses. Specifically, our method employs normalizing flow tailored to the SO(3) rotational group, incorporating a coupling mechanism based on the M\"obius transformation. This enables the framework to accurately represent any distribution on SO(3), effectively addressing issues related to discontinuities. Additionally, we reinterpret the challenge of reconstructing 3D human figures from 2D pixel-aligned inputs as the task of mapping these inputs to a range of probable poses. This perspective acknowledges the intrinsic ambiguity of the task and facilitates a straightforward integration method for multi-view scenarios. The combination of these strategies showcases the effectiveness of probabilistic models in complex scenarios for human pose estimation techniques. Our approach notably surpasses existing methods in the field of pose estimation. We also validate our methodology on human pose estimation from RGB images as well as medical X-Ray datasets.
3D Face Reconstruction From Radar Images
Dec 03, 2024
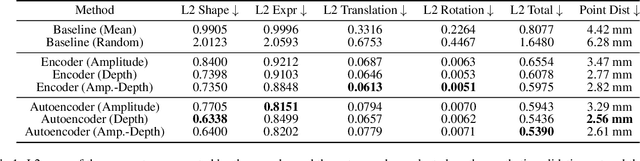
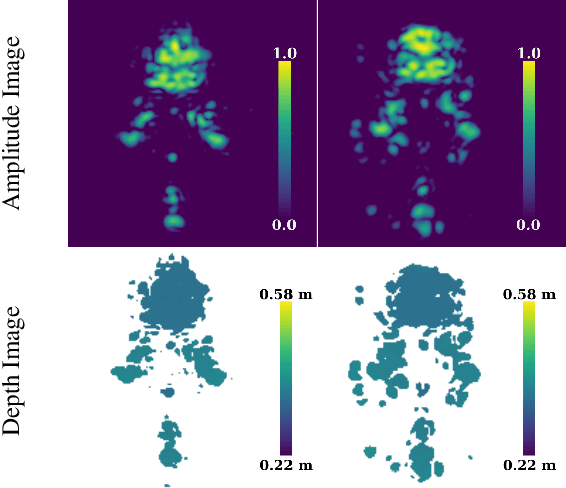
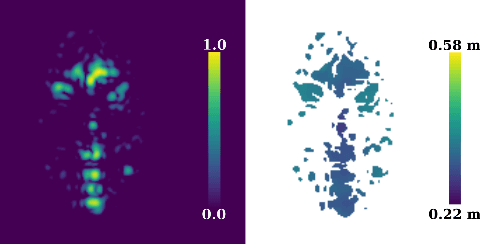
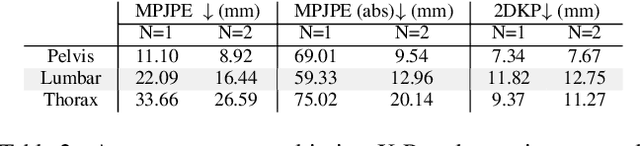
The 3D reconstruction of faces gains wide attention in computer vision and is used in many fields of application, for example, animation, virtual reality, and even forensics. This work is motivated by monitoring patients in sleep laboratories. Due to their unique characteristics, sensors from the radar domain have advantages compared to optical sensors, namely penetration of electrically non-conductive materials and independence of light. These advantages of radar signals unlock new applications and require adaptation of 3D reconstruction frameworks. We propose a novel model-based method for 3D reconstruction from radar images. We generate a dataset of synthetic radar images with a physics-based but non-differentiable radar renderer. This dataset is used to train a CNN-based encoder to estimate the parameters of a 3D morphable face model. Whilst the encoder alone already leads to strong reconstructions of synthetic data, we extend our reconstruction in an Analysis-by-Synthesis fashion to a model-based autoencoder. This is enabled by learning the rendering process in the decoder, which acts as an object-specific differentiable radar renderer. Subsequently, the combination of both network parts is trained to minimize both, the loss of the parameters and the loss of the resulting reconstructed radar image. This leads to the additional benefit, that at test time the parameters can be further optimized by finetuning the autoencoder unsupervised on the image loss. We evaluated our framework on generated synthetic face images as well as on real radar images with 3D ground truth of four individuals.
Neural Image Unfolding: Flattening Sparse Anatomical Structures using Neural Fields
Nov 27, 2024



Tomographic imaging reveals internal structures of 3D objects and is crucial for medical diagnoses. Visualizing the morphology and appearance of non-planar sparse anatomical structures that extend over multiple 2D slices in tomographic volumes is inherently difficult but valuable for decision-making and reporting. Hence, various organ-specific unfolding techniques exist to map their densely sampled 3D surfaces to a distortion-minimized 2D representation. However, there is no versatile framework to flatten complex sparse structures including vascular, duct or bone systems. We deploy a neural field to fit the transformation of the anatomy of interest to a 2D overview image. We further propose distortion regularization strategies and combine geometric with intensity-based loss formulations to also display non-annotated and auxiliary targets. In addition to improved versatility, our unfolding technique outperforms mesh-based baselines for sparse structures w.r.t. peak distortion and our regularization scheme yields smoother transformations compared to Jacobian formulations from neural field-based image registration.
ArCSEM: Artistic Colorization of SEM Images via Gaussian Splatting
Oct 25, 2024



Scanning Electron Microscopes (SEMs) are widely renowned for their ability to analyze the surface structures of microscopic objects, offering the capability to capture highly detailed, yet only grayscale, images. To create more expressive and realistic illustrations, these images are typically manually colorized by an artist with the support of image editing software. This task becomes highly laborious when multiple images of a scanned object require colorization. We propose facilitating this process by using the underlying 3D structure of the microscopic scene to propagate the color information to all the captured images, from as little as one colorized view. We explore several scene representation techniques and achieve high-quality colorized novel view synthesis of a SEM scene. In contrast to prior work, there is no manual intervention or labelling involved in obtaining the 3D representation. This enables an artist to color a single or few views of a sequence and automatically retrieve a fully colored scene or video. Project page: https://ronly2460.github.io/ArCSEM
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
Apr 25, 2024



Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., "a woman is drinking water."). Existing TI2V frameworks often require costly training on video-text datasets and specific model designs for text and image conditioning. In this paper, we propose TI2V-Zero, a zero-shot, tuning-free method that empowers a pretrained text-to-video (T2V) diffusion model to be conditioned on a provided image, enabling TI2V generation without any optimization, fine-tuning, or introducing external modules. Our approach leverages a pretrained T2V diffusion foundation model as the generative prior. To guide video generation with the additional image input, we propose a "repeat-and-slide" strategy that modulates the reverse denoising process, allowing the frozen diffusion model to synthesize a video frame-by-frame starting from the provided image. To ensure temporal continuity, we employ a DDPM inversion strategy to initialize Gaussian noise for each newly synthesized frame and a resampling technique to help preserve visual details. We conduct comprehensive experiments on both domain-specific and open-domain datasets, where TI2V-Zero consistently outperforms a recent open-domain TI2V model. Furthermore, we show that TI2V-Zero can seamlessly extend to other tasks such as video infilling and prediction when provided with more images. Its autoregressive design also supports long video generation.
Generalizable 3D Scene Reconstruction via Divide and Conquer from a Single View
Apr 04, 2024



Single-view 3D reconstruction is currently approached from two dominant perspectives: reconstruction of scenes with limited diversity using 3D data supervision or reconstruction of diverse singular objects using large image priors. However, real-world scenarios are far more complex and exceed the capabilities of these methods. We therefore propose a hybrid method following a divide-and-conquer strategy. We first process the scene holistically, extracting depth and semantic information, and then leverage a single-shot object-level method for the detailed reconstruction of individual components. By following a compositional processing approach, the overall framework achieves full reconstruction of complex 3D scenes from a single image. We purposely design our pipeline to be highly modular by carefully integrating specific procedures for each processing step, without requiring an end-to-end training of the whole system. This enables the pipeline to naturally improve as future methods can replace the individual modules. We demonstrate the reconstruction performance of our approach on both synthetic and real-world scenes, comparing favorable against prior works. Project page: https://andreeadogaru.github.io/Gen3DSR.
AMOR: Ambiguous Authorship Order
Apr 01, 2024As we all know, writing scientific papers together with our beloved colleagues is a truly remarkable experience (partially): endless discussions about the same useless paragraph over and over again, followed by long days and long nights -- both at the same time. What a wonderful ride it is! What a beautiful life we have. But wait, there's one tiny little problem that utterly shatters the peace, turning even renowned scientists into bloodthirsty monsters: author order. The reason is that, contrary to widespread opinion, it's not the font size that matters, but the way things are ordered. Of course, this is a fairly well-known fact among scientists all across the planet (and beyond) and explains clearly why we regularly have to read about yet another escalated paper submission in local police reports. In this paper, we take an important step backwards to tackle this issue by solving the so-called author ordering problem (AOP) once and for all. Specifically, we propose AMOR, a system that replaces silly constructs like co-first or co-middle authorship with a simple yet easy probabilistic approach based on random shuffling of the author list at viewing time. In addition to AOP, we also solve the ambiguous author ordering citation problem} (AAOCP) on the fly. Stop author violence, be human.
Exploring Multi-modal Neural Scene Representations With Applications on Thermal Imaging
Mar 18, 2024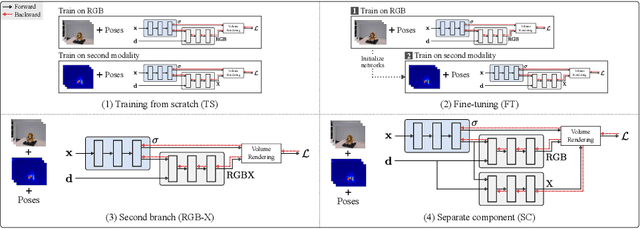

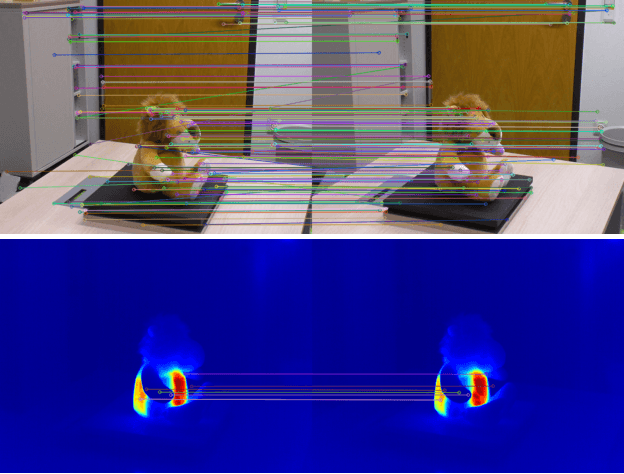

Neural Radiance Fields (NeRFs) quickly evolved as the new de-facto standard for the task of novel view synthesis when trained on a set of RGB images. In this paper, we conduct a comprehensive evaluation of neural scene representations, such as NeRFs, in the context of multi-modal learning. Specifically, we present four different strategies of how to incorporate a second modality, other than RGB, into NeRFs: (1) training from scratch independently on both modalities; (2) pre-training on RGB and fine-tuning on the second modality; (3) adding a second branch; and (4) adding a separate component to predict (color) values of the additional modality. We chose thermal imaging as second modality since it strongly differs from RGB in terms of radiosity, making it challenging to integrate into neural scene representations. For the evaluation of the proposed strategies, we captured a new publicly available multi-view dataset, ThermalMix, consisting of six common objects and about 360 RGB and thermal images in total. We employ cross-modality calibration prior to data capturing, leading to high-quality alignments between RGB and thermal images. Our findings reveal that adding a second branch to NeRF performs best for novel view synthesis on thermal images while also yielding compelling results on RGB. Finally, we also show that our analysis generalizes to other modalities, including near-infrared images and depth maps. Project page: https://mert-o.github.io/ThermalNeRF/.