 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArCSEM: Artistic Colorization of SEM Images via Gaussian Splatting
Oct 25, 2024



Scanning Electron Microscopes (SEMs) are widely renowned for their ability to analyze the surface structures of microscopic objects, offering the capability to capture highly detailed, yet only grayscale, images. To create more expressive and realistic illustrations, these images are typically manually colorized by an artist with the support of image editing software. This task becomes highly laborious when multiple images of a scanned object require colorization. We propose facilitating this process by using the underlying 3D structure of the microscopic scene to propagate the color information to all the captured images, from as little as one colorized view. We explore several scene representation techniques and achieve high-quality colorized novel view synthesis of a SEM scene. In contrast to prior work, there is no manual intervention or labelling involved in obtaining the 3D representation. This enables an artist to color a single or few views of a sequence and automatically retrieve a fully colored scene or video. Project page: https://ronly2460.github.io/ArCSEM
Generalizable 3D Scene Reconstruction via Divide and Conquer from a Single View
Apr 04, 2024



Single-view 3D reconstruction is currently approached from two dominant perspectives: reconstruction of scenes with limited diversity using 3D data supervision or reconstruction of diverse singular objects using large image priors. However, real-world scenarios are far more complex and exceed the capabilities of these methods. We therefore propose a hybrid method following a divide-and-conquer strategy. We first process the scene holistically, extracting depth and semantic information, and then leverage a single-shot object-level method for the detailed reconstruction of individual components. By following a compositional processing approach, the overall framework achieves full reconstruction of complex 3D scenes from a single image. We purposely design our pipeline to be highly modular by carefully integrating specific procedures for each processing step, without requiring an end-to-end training of the whole system. This enables the pipeline to naturally improve as future methods can replace the individual modules. We demonstrate the reconstruction performance of our approach on both synthetic and real-world scenes, comparing favorable against prior works. Project page: https://andreeadogaru.github.io/Gen3DSR.
AMOR: Ambiguous Authorship Order
Apr 01, 2024As we all know, writing scientific papers together with our beloved colleagues is a truly remarkable experience (partially): endless discussions about the same useless paragraph over and over again, followed by long days and long nights -- both at the same time. What a wonderful ride it is! What a beautiful life we have. But wait, there's one tiny little problem that utterly shatters the peace, turning even renowned scientists into bloodthirsty monsters: author order. The reason is that, contrary to widespread opinion, it's not the font size that matters, but the way things are ordered. Of course, this is a fairly well-known fact among scientists all across the planet (and beyond) and explains clearly why we regularly have to read about yet another escalated paper submission in local police reports. In this paper, we take an important step backwards to tackle this issue by solving the so-called author ordering problem (AOP) once and for all. Specifically, we propose AMOR, a system that replaces silly constructs like co-first or co-middle authorship with a simple yet easy probabilistic approach based on random shuffling of the author list at viewing time. In addition to AOP, we also solve the ambiguous author ordering citation problem} (AAOCP) on the fly. Stop author violence, be human.
RANRAC: Robust Neural Scene Representations via Random Ray Consensus
Dec 15, 2023We introduce RANRAC, a robust reconstruction algorithm for 3D objects handling occluded and distracted images, which is a particularly challenging scenario that prior robust reconstruction methods cannot deal with. Our solution supports single-shot reconstruction by involving light-field networks, and is also applicable to photo-realistic, robust, multi-view reconstruction from real-world images based on neural radiance fields. While the algorithm imposes certain limitations on the scene representation and, thereby, the supported scene types, it reliably detects and excludes inconsistent perspectives, resulting in clean images without floating artifacts. Our solution is based on a fuzzy adaption of the random sample consensus paradigm, enabling its application to large scale models. We interpret the minimal number of samples to determine the model parameters as a tunable hyperparameter. This is applicable, as a cleaner set of samples improves reconstruction quality. Further, this procedure also handles outliers. Especially for conditioned models, it can result in the same local minimum in the latent space as would be obtained with a completely clean set. We report significant improvements for novel-view synthesis in occluded scenarios, of up to 8dB PSNR compared to the baseline.
Neural Haircut: Prior-Guided Strand-Based Hair Reconstruction
Jun 12, 2023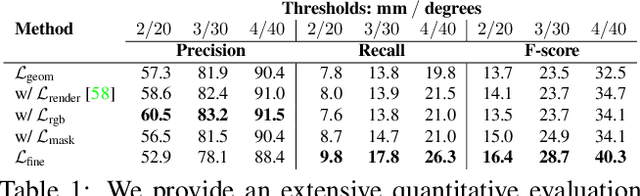
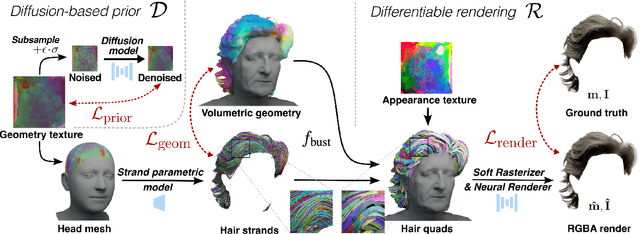
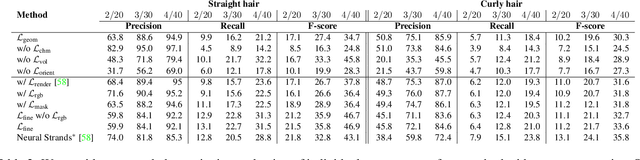
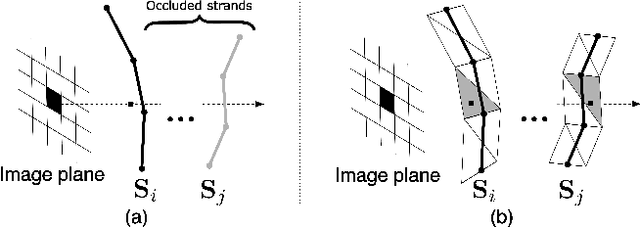
Generating realistic human 3D reconstructions using image or video data is essential for various communication and entertainment applications. While existing methods achieved impressive results for body and facial regions, realistic hair modeling still remains challenging due to its high mechanical complexity. This work proposes an approach capable of accurate hair geometry reconstruction at a strand level from a monocular video or multi-view images captured in uncontrolled lighting conditions. Our method has two stages, with the first stage performing joint reconstruction of coarse hair and bust shapes and hair orientation using implicit volumetric representations. The second stage then estimates a strand-level hair reconstruction by reconciling in a single optimization process the coarse volumetric constraints with hair strand and hairstyle priors learned from the synthetic data. To further increase the reconstruction fidelity, we incorporate image-based losses into the fitting process using a new differentiable renderer. The combined system, named Neural Haircut, achieves high realism and personalization of the reconstructed hairstyles.
Sphere-Guided Training of Neural Implicit Surfaces
Sep 30, 2022
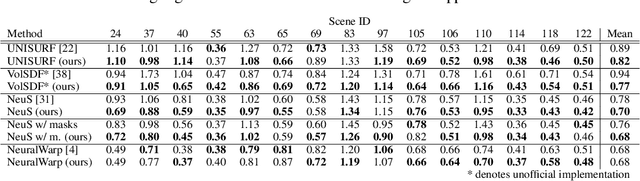
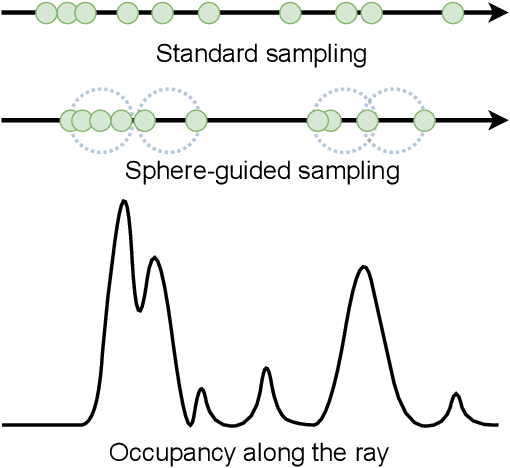
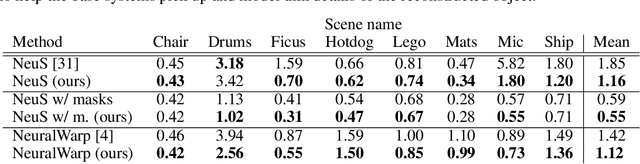
In recent years, surface modeling via neural implicit functions has become one of the main techniques for multi-view 3D reconstruction. However, the state-of-the-art methods rely on the implicit functions to model an entire volume of the scene, leading to reduced reconstruction fidelity in the areas with thin objects or high-frequency details. To address that, we present a method for jointly training neural implicit surfaces alongside an auxiliary explicit shape representation, which acts as surface guide. In our approach, this representation encapsulates the surface region of the scene and enables us to boost the efficiency of the implicit function training by only modeling the volume in that region. We propose using a set of learnable spherical primitives as a learnable surface guidance since they can be efficiently trained alongside the neural surface function using its gradients. Our training pipeline consists of iterative updates of the spheres' centers using the gradients of the implicit function and then fine-tuning the latter to the updated surface region of the scene. We show that such modification to the training procedure can be plugged into several popular implicit reconstruction methods, improving the quality of the results over multiple 3D reconstruction benchmarks.