 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATATA: One Algorithm to Align Them All
Jan 16, 2026We suggest a new multi-modal algorithm for joint inference of paired structurally aligned samples with Rectified Flow models. While some existing methods propose a codependent generation process, they do not view the problem of joint generation from a structural alignment perspective. Recent work uses Score Distillation Sampling to generate aligned 3D models, but SDS is known to be time-consuming, prone to mode collapse, and often provides cartoonish results. By contrast, our suggested approach relies on the joint transport of a segment in the sample space, yielding faster computation at inference time. Our approach can be built on top of an arbitrary Rectified Flow model operating on the structured latent space. We show the applicability of our method to the domains of image, video, and 3D shape generation using state-of-the-art baselines and evaluate it against both editing-based and joint inference-based competing approaches. We demonstrate a high degree of structural alignment for the sample pairs obtained with our method and a high visual quality of the samples. Our method improves the state-of-the-art for image and video generation pipelines. For 3D generation, it is able to show comparable quality while working orders of magnitude faster.
A3D: Does Diffusion Dream about 3D Alignment?
Jun 21, 2024



We tackle the problem of text-driven 3D generation from a geometry alignment perspective. We aim at the generation of multiple objects which are consistent in terms of semantics and geometry. Recent methods based on Score Distillation have succeeded in distilling the knowledge from 2D diffusion models to high-quality objects represented by 3D neural radiance fields. These methods handle multiple text queries separately, and therefore, the resulting objects have a high variability in object pose and structure. However, in some applications such as geometry editing, it is desirable to obtain aligned objects. In order to achieve alignment, we propose to optimize the continuous trajectories between the aligned objects, by modeling a space of linear pairwise interpolations of the textual embeddings with a single NeRF representation. We demonstrate that similar objects, consisting of semantically corresponding parts, can be well aligned in 3D space without costly modifications to the generation process. We provide several practical scenarios including mesh editing and object hybridization that benefit from geometry alignment and experimentally demonstrate the efficiency of our method. https://voyleg.github.io/a3d/
NeuSD: Surface Completion with Multi-View Text-to-Image Diffusion
Dec 07, 2023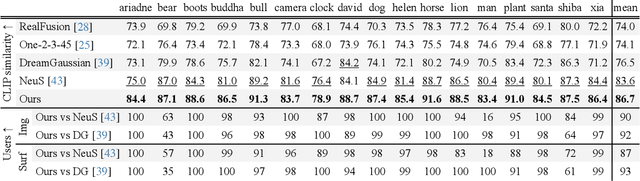


We present a novel method for 3D surface reconstruction from multiple images where only a part of the object of interest is captured. Our approach builds on two recent developments: surface reconstruction using neural radiance fields for the reconstruction of the visible parts of the surface, and guidance of pre-trained 2D diffusion models in the form of Score Distillation Sampling (SDS) to complete the shape in unobserved regions in a plausible manner. We introduce three components. First, we suggest employing normal maps as a pure geometric representation for SDS instead of color renderings which are entangled with the appearance information. Second, we introduce the freezing of the SDS noise during training which results in more coherent gradients and better convergence. Third, we propose Multi-View SDS as a way to condition the generation of the non-observable part of the surface without fine-tuning or making changes to the underlying 2D Stable Diffusion model. We evaluate our approach on the BlendedMVS dataset demonstrating significant qualitative and quantitative improvements over competing methods.
Factored-NeuS: Reconstructing Surfaces, Illumination, and Materials of Possibly Glossy Objects
May 29, 2023We develop a method that recovers the surface, materials, and illumination of a scene from its posed multi-view images. In contrast to prior work, it does not require any additional data and can handle glossy objects or bright lighting. It is a progressive inverse rendering approach, which consists of three stages. First, we reconstruct the scene radiance and signed distance function (SDF) with our novel regularization strategy for specular reflections. Our approach considers both the diffuse and specular colors, which allows for handling complex view-dependent lighting effects for surface reconstruction. Second, we distill light visibility and indirect illumination from the learned SDF and radiance field using learnable mapping functions. Third, we design a method for estimating the ratio of incoming direct light represented via Spherical Gaussians reflected in a specular manner and then reconstruct the materials and direct illumination of the scene. Experimental results demonstrate that the proposed method outperforms the current state-of-the-art in recovering surfaces, materials, and lighting without relying on any additional data.
Sphere-Guided Training of Neural Implicit Surfaces
Sep 30, 2022
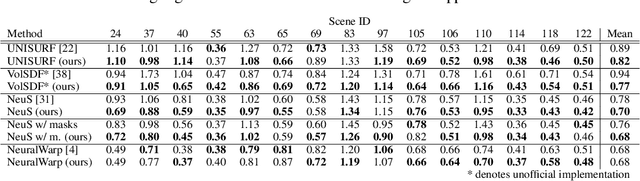
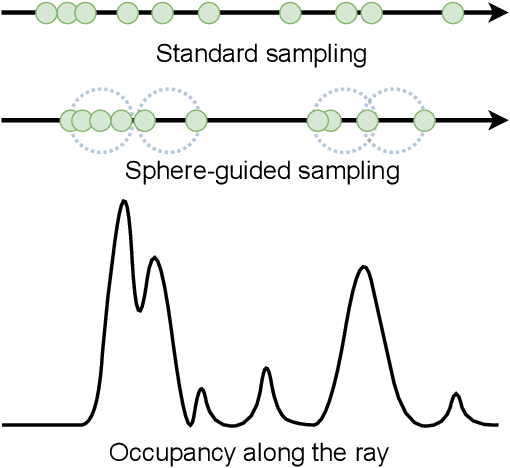
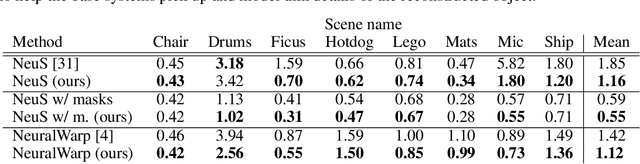
In recent years, surface modeling via neural implicit functions has become one of the main techniques for multi-view 3D reconstruction. However, the state-of-the-art methods rely on the implicit functions to model an entire volume of the scene, leading to reduced reconstruction fidelity in the areas with thin objects or high-frequency details. To address that, we present a method for jointly training neural implicit surfaces alongside an auxiliary explicit shape representation, which acts as surface guide. In our approach, this representation encapsulates the surface region of the scene and enables us to boost the efficiency of the implicit function training by only modeling the volume in that region. We propose using a set of learnable spherical primitives as a learnable surface guidance since they can be efficiently trained alongside the neural surface function using its gradients. Our training pipeline consists of iterative updates of the spheres' centers using the gradients of the implicit function and then fine-tuning the latter to the updated surface region of the scene. We show that such modification to the training procedure can be plugged into several popular implicit reconstruction methods, improving the quality of the results over multiple 3D reconstruction benchmarks.
How Good MVSNets Are at Depth Fusion
Nov 30, 2020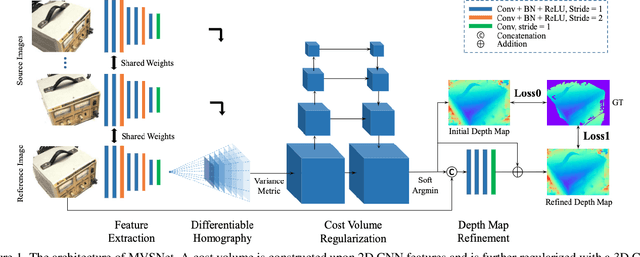
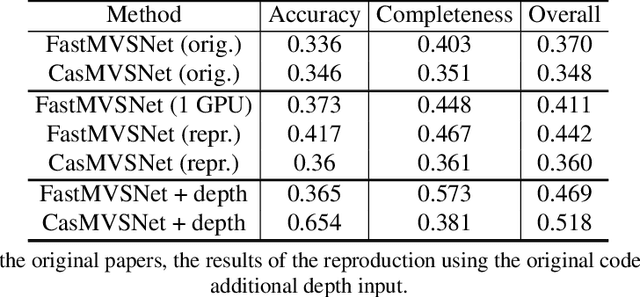
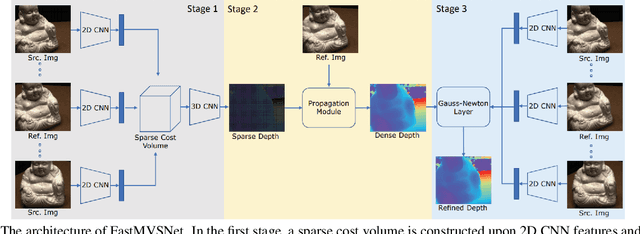
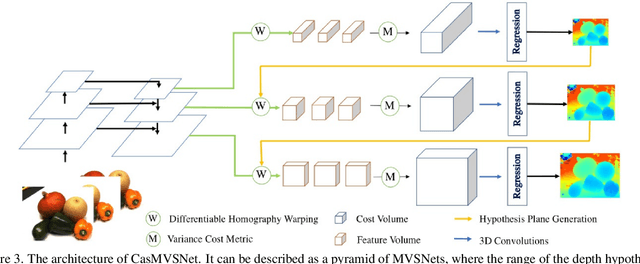
We study the effects of the additional input to deep multi-view stereo methods in the form of low-quality sensor depth. We modify two state-of-the-art deep multi-view stereo methods for using with the input depth. We show that the additional input depth may improve the quality of deep multi-view stereo.
Adversarial Generation of Continuous Images
Nov 24, 2020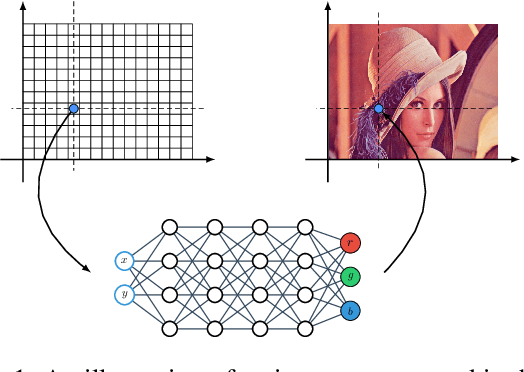


In most existing learning systems, images are typically viewed as 2D pixel arrays. However, in another paradigm gaining popularity, a 2D image is represented as an implicit neural representation (INR) -- an MLP that predicts an RGB pixel value given its (x,y) coordinate. In this paper, we propose two novel architectural techniques for building INR-based image decoders: factorized multiplicative modulation and multi-scale INRs, and use them to build a state-of-the-art continuous image GAN. Previous attempts to adapt INRs for image generation were limited to MNIST-like datasets and do not scale to complex real-world data. Our proposed architectural design improves the performance of continuous image generators by x6-40 times and reaches FID scores of 6.27 on LSUN bedroom 256x256 and 16.32 on FFHQ 1024x1024, greatly reducing the gap between continuous image GANs and pixel-based ones. To the best of our knowledge, these are the highest reported scores for an image generator, that consists entirely of fully-connected layers. Apart from that, we explore several exciting properties of INR-based decoders, like out-of-the-box superresolution, meaningful image-space interpolation, accelerated inference of low-resolution images, an ability to extrapolate outside of image boundaries and strong geometric prior. The source code is available at https://github.com/universome/inr-gan
CAD-Deform: Deformable Fitting of CAD Models to 3D Scans
Jul 23, 2020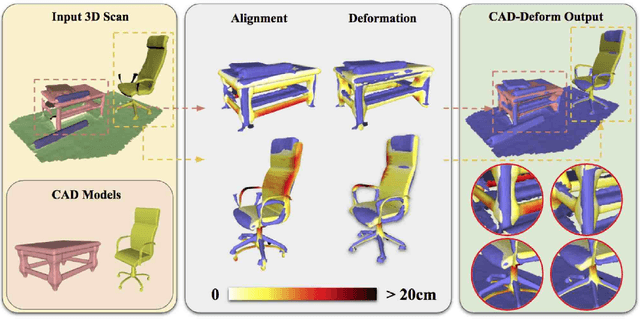
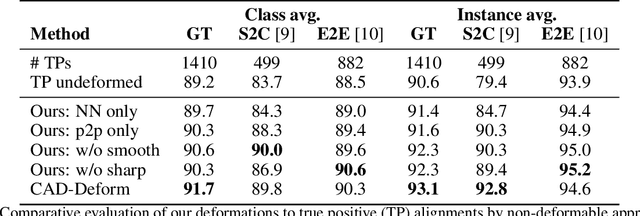
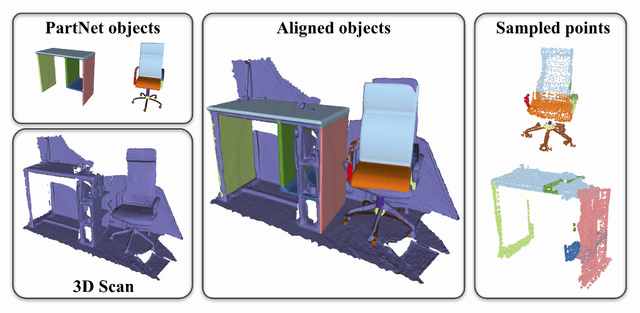

Shape retrieval and alignment are a promising avenue towards turning 3D scans into lightweight CAD representations that can be used for content creation such as mobile or AR/VR gaming scenarios. Unfortunately, CAD model retrieval is limited by the availability of models in standard 3D shape collections (e.g., ShapeNet). In this work, we address this shortcoming by introducing CAD-Deform, a method which obtains more accurate CAD-to-scan fits by non-rigidly deforming retrieved CAD models. Our key contribution is a new non-rigid deformation model incorporating smooth transformations and preservation of sharp features, that simultaneously achieves very tight fits from CAD models to the 3D scan and maintains the clean, high-quality surface properties of hand-modeled CAD objects. A series of thorough experiments demonstrate that our method achieves significantly tighter scan-to-CAD fits, allowing a more accurate digital replica of the scanned real-world environment while preserving important geometric features present in synthetic CAD environments.
Latent-Space Laplacian Pyramids for Adversarial Representation Learning with 3D Point Clouds
Dec 13, 2019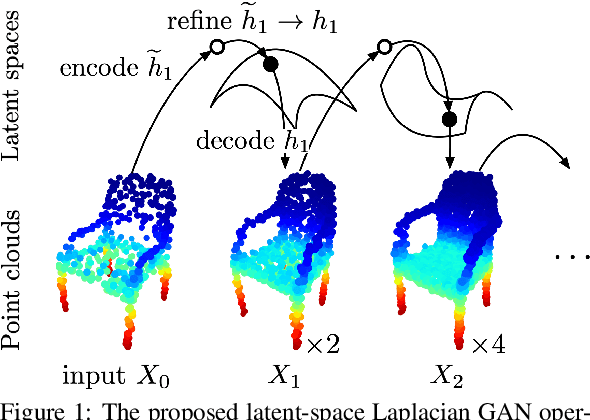
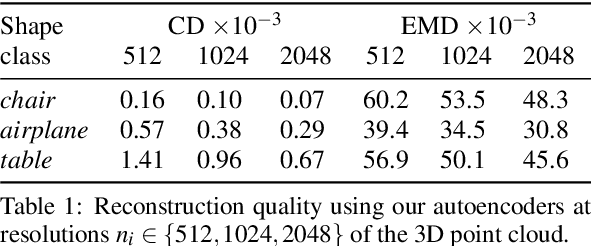
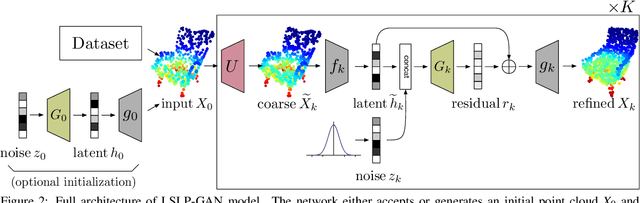
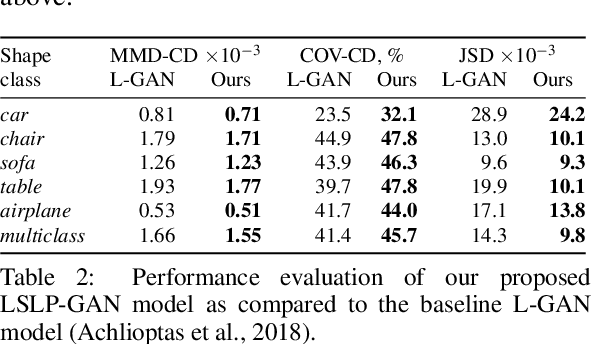
Constructing high-quality generative models for 3D shapes is a fundamental task in computer vision with diverse applications in geometry processing, engineering, and design. Despite the recent progress in deep generative modelling, synthesis of finely detailed 3D surfaces, such as high-resolution point clouds, from scratch has not been achieved with existing approaches. In this work, we propose to employ the latent-space Laplacian pyramid representation within a hierarchical generative model for 3D point clouds. We combine the recently proposed latent-space GAN and Laplacian GAN architectures to form a multi-scale model capable of generating 3D point clouds at increasing levels of detail. Our evaluation demonstrates that our model outperforms the existing generative models for 3D point clouds.