 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSphere-Guided Training of Neural Implicit Surfaces
Sep 30, 2022
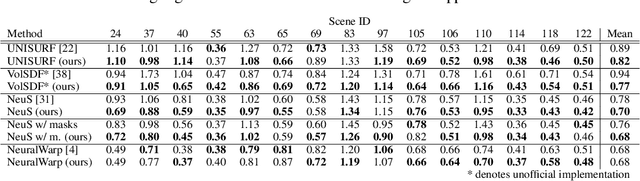
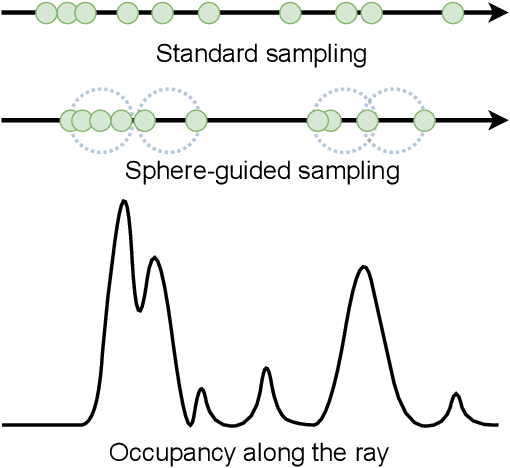
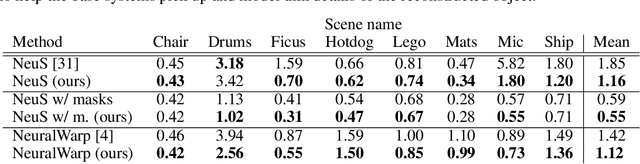
In recent years, surface modeling via neural implicit functions has become one of the main techniques for multi-view 3D reconstruction. However, the state-of-the-art methods rely on the implicit functions to model an entire volume of the scene, leading to reduced reconstruction fidelity in the areas with thin objects or high-frequency details. To address that, we present a method for jointly training neural implicit surfaces alongside an auxiliary explicit shape representation, which acts as surface guide. In our approach, this representation encapsulates the surface region of the scene and enables us to boost the efficiency of the implicit function training by only modeling the volume in that region. We propose using a set of learnable spherical primitives as a learnable surface guidance since they can be efficiently trained alongside the neural surface function using its gradients. Our training pipeline consists of iterative updates of the spheres' centers using the gradients of the implicit function and then fine-tuning the latter to the updated surface region of the scene. We show that such modification to the training procedure can be plugged into several popular implicit reconstruction methods, improving the quality of the results over multiple 3D reconstruction benchmarks.