 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADFS: A Big CAD Program Dataset and Framework for Computer-Aided Design with Large Language Models
May 03, 2026We introduce CADFS, a data-centric framework that enables large vision-language models to generate complex CAD design histories. Existing generative CAD systems are restricted to sketch-extrude operations due to simplified representations and limited datasets. We address this by introducing a FeatureScript-based representation and constructing a dataset of 450k real-world CAD models spanning 15 modeling operations. We obtain the dataset via a new pipeline that reconstructs clean, executable FeatureScript programs and provides multimodal annotations. Fine-tuning a VLM on this representation yields state-of-the-art results in text-conditioned CAD generation and image-based reconstruction, producing more accurate, diverse, and feature-rich designs than prior frameworks. Ablations show that each individual component of our framework, i.e., the FeatureScript representation, the extended operation set, and representation-aligned textual descriptions, significantly improves performance. Our framework substantially broadens the complexity and realism achievable in generative CAD. The CADFS framework and the new dataset are available at https://voyleg.github.io/cadfs/.
One-Step Residual Shifting Diffusion for Image Super-Resolution via Distillation
Mar 17, 2025Diffusion models for super-resolution (SR) produce high-quality visual results but require expensive computational costs. Despite the development of several methods to accelerate diffusion-based SR models, some (e.g., SinSR) fail to produce realistic perceptual details, while others (e.g., OSEDiff) may hallucinate non-existent structures. To overcome these issues, we present RSD, a new distillation method for ResShift, one of the top diffusion-based SR models. Our method is based on training the student network to produce such images that a new fake ResShift model trained on them will coincide with the teacher model. RSD achieves single-step restoration and outperforms the teacher by a large margin. We show that our distillation method can surpass the other distillation-based method for ResShift - SinSR - making it on par with state-of-the-art diffusion-based SR distillation methods. Compared to SR methods based on pre-trained text-to-image models, RSD produces competitive perceptual quality, provides images with better alignment to degraded input images, and requires fewer parameters and GPU memory. We provide experimental results on various real-world and synthetic datasets, including RealSR, RealSet65, DRealSR, ImageNet, and DIV2K.
A3D: Does Diffusion Dream about 3D Alignment?
Jun 21, 2024



We tackle the problem of text-driven 3D generation from a geometry alignment perspective. We aim at the generation of multiple objects which are consistent in terms of semantics and geometry. Recent methods based on Score Distillation have succeeded in distilling the knowledge from 2D diffusion models to high-quality objects represented by 3D neural radiance fields. These methods handle multiple text queries separately, and therefore, the resulting objects have a high variability in object pose and structure. However, in some applications such as geometry editing, it is desirable to obtain aligned objects. In order to achieve alignment, we propose to optimize the continuous trajectories between the aligned objects, by modeling a space of linear pairwise interpolations of the textual embeddings with a single NeRF representation. We demonstrate that similar objects, consisting of semantically corresponding parts, can be well aligned in 3D space without costly modifications to the generation process. We provide several practical scenarios including mesh editing and object hybridization that benefit from geometry alignment and experimentally demonstrate the efficiency of our method. https://voyleg.github.io/a3d/
Unpaired Image Super-Resolution with Optimal Transport Maps
Feb 02, 2022
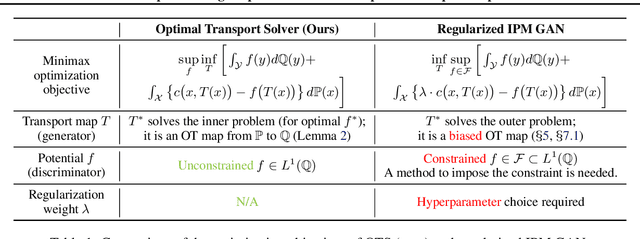
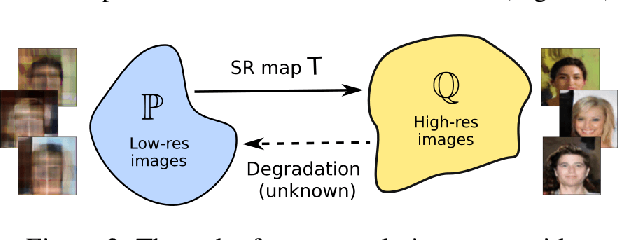

Real-world image super-resolution (SR) tasks often do not have paired datasets limiting the application of supervised techniques. As a result, the tasks are usually approached by unpaired techniques based on Generative Adversarial Networks (GANs) which yield complex training losses with several regularization terms such as content and identity losses. We theoretically investigate the optimization problems which arise in such models and find two surprising observations. First, the learned SR map is always an optimal transport (OT) map. Second, we empirically show that the learned map is biased, i.e., it may not actually transform the distribution of low-resolution images to high-resolution images. Inspired by these findings, we propose an algorithm for unpaired SR which learns an unbiased OT map for the perceptual transport cost. Unlike existing GAN-based alternatives, our algorithm has a simple optimization objective reducing the neccesity to perform complex hyperparameter selection and use additional regularizations. At the same time, it provides nearly state-of-the-art performance on the large-scale unpaired AIM-19 dataset.
Manifold Topology Divergence: a Framework for Comparing Data Manifolds
Jun 08, 2021
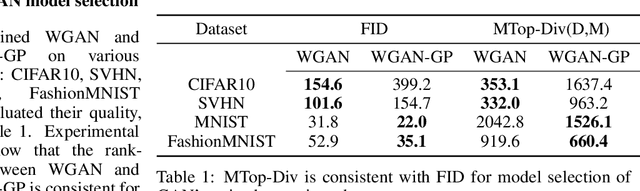
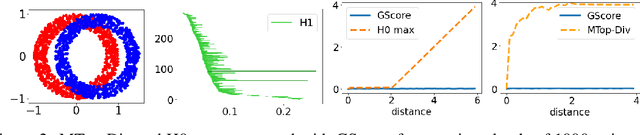
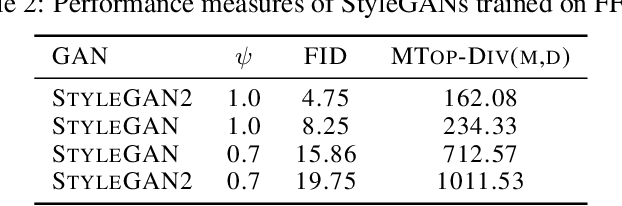
We develop a framework for comparing data manifolds, aimed, in particular, towards the evaluation of deep generative models. We describe a novel tool, Cross-Barcode(P,Q), that, given a pair of distributions in a high-dimensional space, tracks multiscale topology spacial discrepancies between manifolds on which the distributions are concentrated. Based on the Cross-Barcode, we introduce the Manifold Topology Divergence score (MTop-Divergence) and apply it to assess the performance of deep generative models in various domains: images, 3D-shapes, time-series, and on different datasets: MNIST, Fashion MNIST, SVHN, CIFAR10, FFHQ, chest X-ray images, market stock data, ShapeNet. We demonstrate that the MTop-Divergence accurately detects various degrees of mode-dropping, intra-mode collapse, mode invention, and image disturbance. Our algorithm scales well (essentially linearly) with the increase of the dimension of the ambient high-dimensional space. It is one of the first TDA-based practical methodologies that can be applied universally to datasets of different sizes and dimensions, including the ones on which the most recent GANs in the visual domain are trained. The proposed method is domain agnostic and does not rely on pre-trained networks.
Do Neural Optimal Transport Solvers Work? A Continuous Wasserstein-2 Benchmark
Jun 03, 2021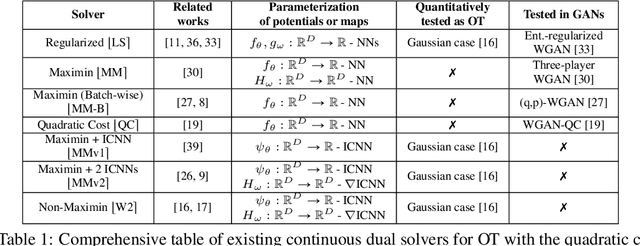
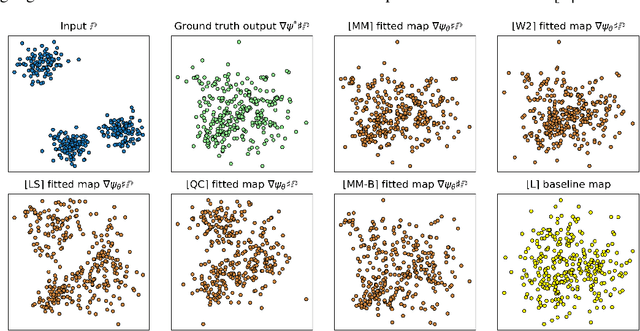
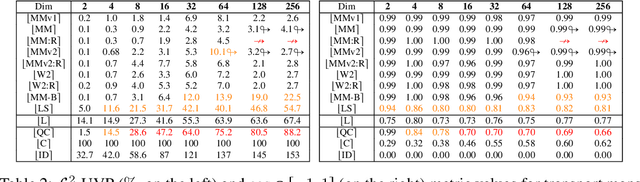

Despite the recent popularity of neural network-based solvers for optimal transport (OT), there is no standard quantitative way to evaluate their performance. In this paper, we address this issue for quadratic-cost transport -- specifically, computation of the Wasserstein-2 distance, a commonly-used formulation of optimal transport in machine learning. To overcome the challenge of computing ground truth transport maps between continuous measures needed to assess these solvers, we use input-convex neural networks (ICNN) to construct pairs of measures whose ground truth OT maps can be obtained analytically. This strategy yields pairs of continuous benchmark measures in high-dimensional spaces such as spaces of images. We thoroughly evaluate existing optimal transport solvers using these benchmark measures. Even though these solvers perform well in downstream tasks, many do not faithfully recover optimal transport maps. To investigate the cause of this discrepancy, we further test the solvers in a setting of image generation. Our study reveals crucial limitations of existing solvers and shows that increased OT accuracy does not necessarily correlate to better results downstream.
Towards Unpaired Depth Enhancement and Super-Resolution in the Wild
May 25, 2021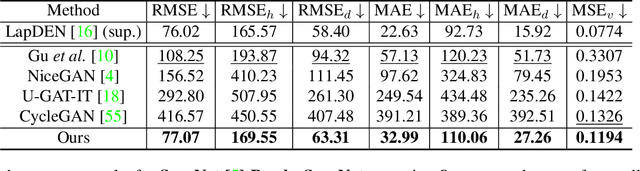
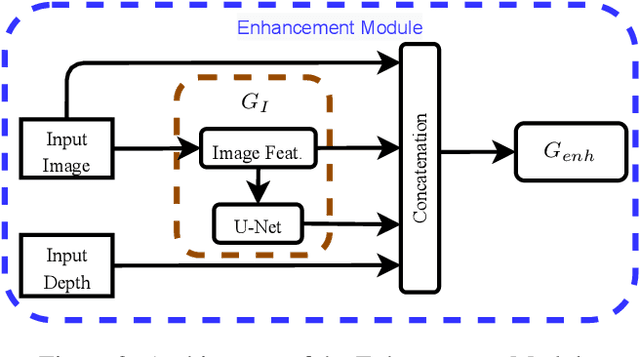
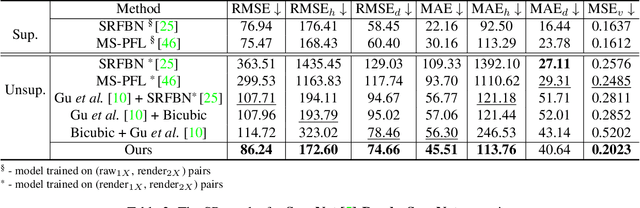
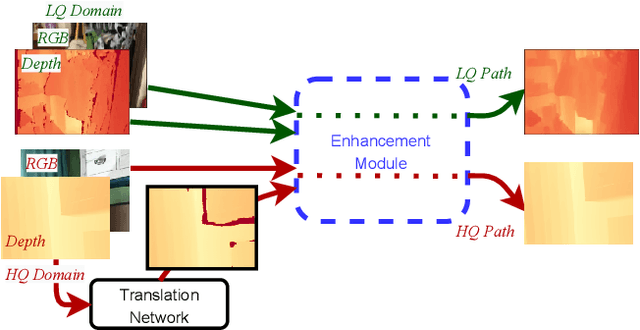
Depth maps captured with commodity sensors are often of low quality and resolution; these maps need to be enhanced to be used in many applications. State-of-the-art data-driven methods of depth map super-resolution rely on registered pairs of low- and high-resolution depth maps of the same scenes. Acquisition of real-world paired data requires specialized setups. Another alternative, generating low-resolution maps from high-resolution maps by subsampling, adding noise and other artificial degradation methods, does not fully capture the characteristics of real-world low-resolution images. As a consequence, supervised learning methods trained on such artificial paired data may not perform well on real-world low-resolution inputs. We consider an approach to depth map enhancement based on learning from unpaired data. While many techniques for unpaired image-to-image translation have been proposed, most are not directly applicable to depth maps. We propose an unpaired learning method for simultaneous depth enhancement and super-resolution, which is based on a learnable degradation model and surface normal estimates as features to produce more accurate depth maps. We demonstrate that our method outperforms existing unpaired methods and performs on par with paired methods on a new benchmark for unpaired learning that we developed.
Multi-fidelity Neural Architecture Search with Knowledge Distillation
Jun 15, 2020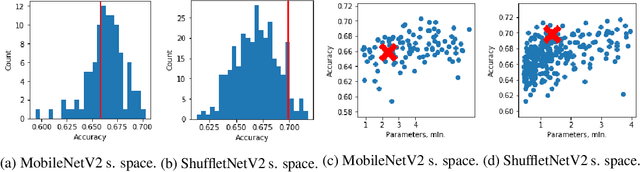
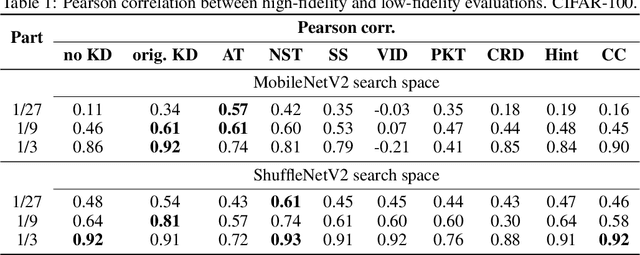
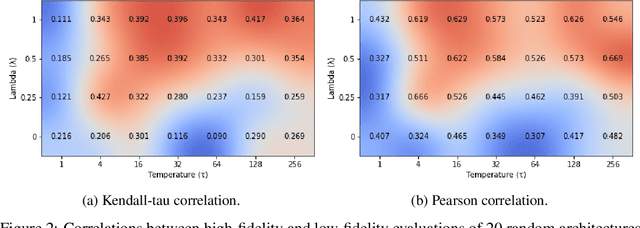
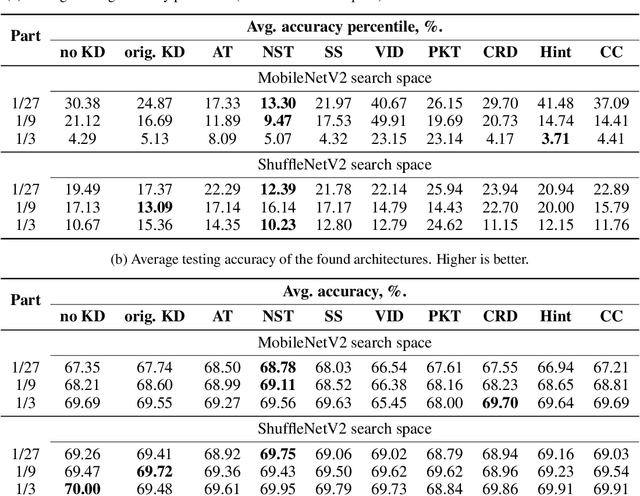
Neural architecture search (NAS) targets at finding the optimal architecture of a neural network for a problem or a family of problems. Evaluations of neural architectures are very time-consuming. One of the possible ways to mitigate this issue is to use low-fidelity evaluations, namely training on a part of a dataset, fewer epochs, with fewer channels, etc. In this paper, we propose to improve low-fidelity evaluations of neural architectures by using a knowledge distillation. Knowledge distillation adds to a loss function a term forcing a network to mimic some teacher network. We carry out experiments on CIFAR-100 and ImageNet and study various knowledge distillation methods. We show that training on the small part of a dataset with such a modified loss function leads to a better selection of neural architectures than training with a logistic loss. The proposed low-fidelity evaluations were incorporated into a multi-fidelity search algorithm that outperformed the search based on high-fidelity evaluations only (training on a full dataset).