 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn autoencoder for compressing angle-resolved photoemission spectroscopy data
Jul 05, 2024Angle-resolved photoemission spectroscopy (ARPES) is a powerful experimental technique to determine the electronic structure of solids. Advances in light sources for ARPES experiments are currently leading to a vast increase of data acquisition rates and data quantity. On the other hand, access time to the most advanced ARPES instruments remains strictly limited, calling for fast, effective, and on-the-fly data analysis tools to exploit this time. In response to this need, we introduce ARPESNet, a versatile autoencoder network that efficiently summmarises and compresses ARPES datasets. We train ARPESNet on a large and varied dataset of 2-dimensional ARPES data extracted by cutting standard 3-dimensional ARPES datasets along random directions in $\mathbf{k}$. To test the data representation capacity of ARPESNet, we compare $k$-means clustering quality between data compressed by ARPESNet, data compressed by discrete cosine transform, and raw data, at different noise levels. ARPESNet data excels in clustering quality despite its high compression ratio.
Making the black-box brighter: interpreting machine learning algorithm for forecasting drilling accidents
Sep 06, 2022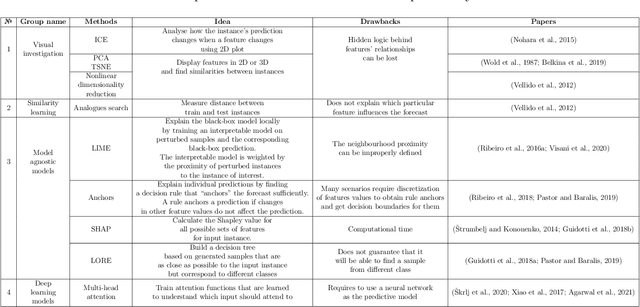


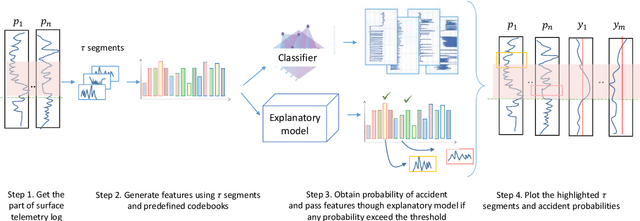
We present an approach for interpreting a black-box alarming system for forecasting accidents and anomalies during the drilling of oil and gas wells. The interpretation methodology aims to explain the local behavior of the accident predictive model to drilling engineers. The explanatory model uses Shapley additive explanations analysis of features, obtained through Bag-of-features representation of telemetry logs used during the drilling accident forecasting phase. Validation shows that the explanatory model has 15% precision at 70% recall, and overcomes the metric values of a random baseline and multi-head attention neural network. These results justify that the developed explanatory model is better aligned with explanations of drilling engineers, than the state-of-the-art method. The joint performance of explanatory and Bag-of-features models allows drilling engineers to understand the logic behind the system decisions at the particular moment, pay attention to highlighted telemetry regions, and correspondingly, increase the trust level in the accident forecasting alarms.
Forecasting the abnormal events at well drilling with machine learning
Mar 10, 2022
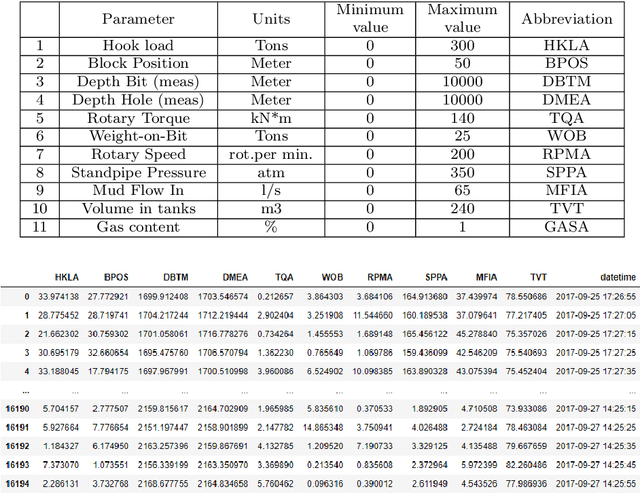
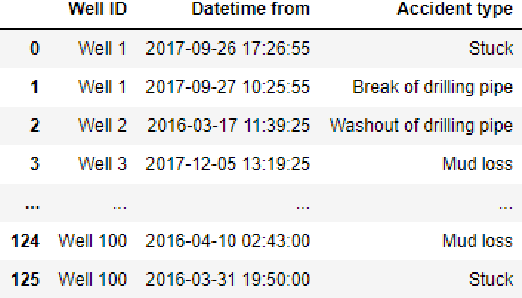

We present a data-driven and physics-informed algorithm for drilling accident forecasting. The core machine-learning algorithm uses the data from the drilling telemetry representing the time-series. We have developed a Bag-of-features representation of the time series that enables the algorithm to predict the probabilities of six types of drilling accidents in real-time. The machine-learning model is trained on the 125 past drilling accidents from 100 different Russian oil and gas wells. Validation shows that the model can forecast 70% of drilling accidents with a false positive rate equals to 40%. The model addresses partial prevention of the drilling accidents at the well construction.
A Differentiable Language Model Adversarial Attack on Text Classifiers
Jul 23, 2021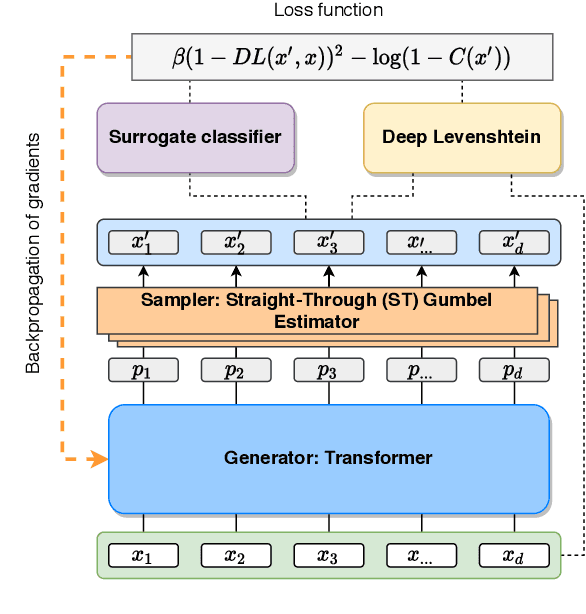
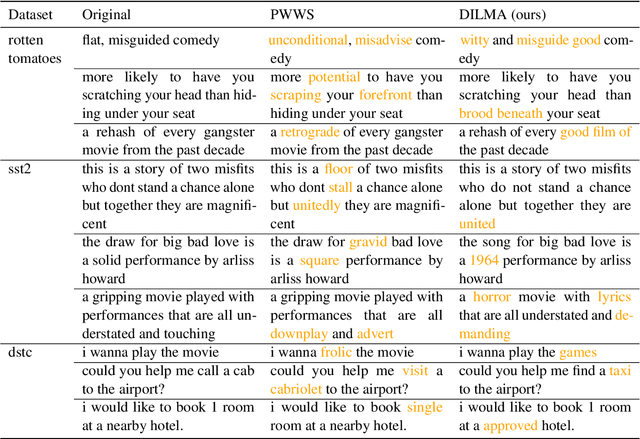
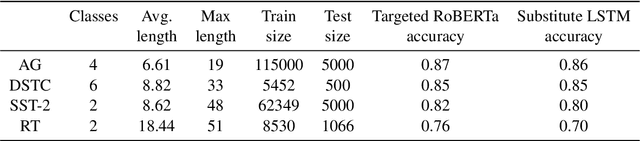
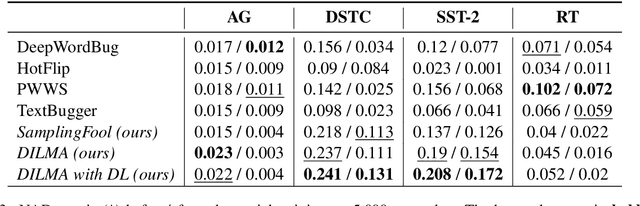
Robustness of huge Transformer-based models for natural language processing is an important issue due to their capabilities and wide adoption. One way to understand and improve robustness of these models is an exploration of an adversarial attack scenario: check if a small perturbation of an input can fool a model. Due to the discrete nature of textual data, gradient-based adversarial methods, widely used in computer vision, are not applicable per~se. The standard strategy to overcome this issue is to develop token-level transformations, which do not take the whole sentence into account. In this paper, we propose a new black-box sentence-level attack. Our method fine-tunes a pre-trained language model to generate adversarial examples. A proposed differentiable loss function depends on a substitute classifier score and an approximate edit distance computed via a deep learning model. We show that the proposed attack outperforms competitors on a diverse set of NLP problems for both computed metrics and human evaluation. Moreover, due to the usage of the fine-tuned language model, the generated adversarial examples are hard to detect, thus current models are not robust. Hence, it is difficult to defend from the proposed attack, which is not the case for other attacks.
Multi-fidelity Neural Architecture Search with Knowledge Distillation
Jun 15, 2020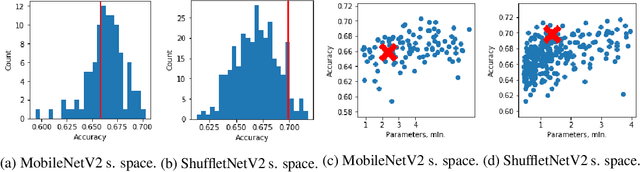
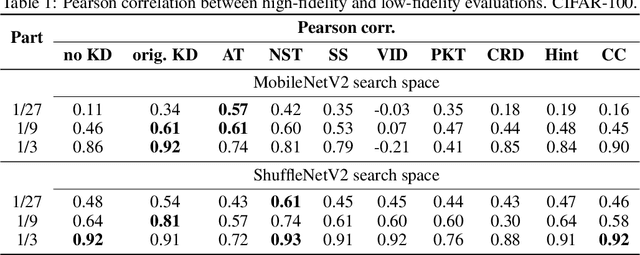
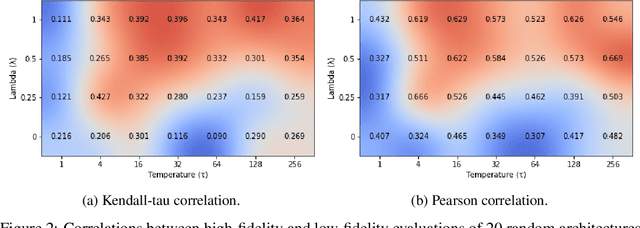
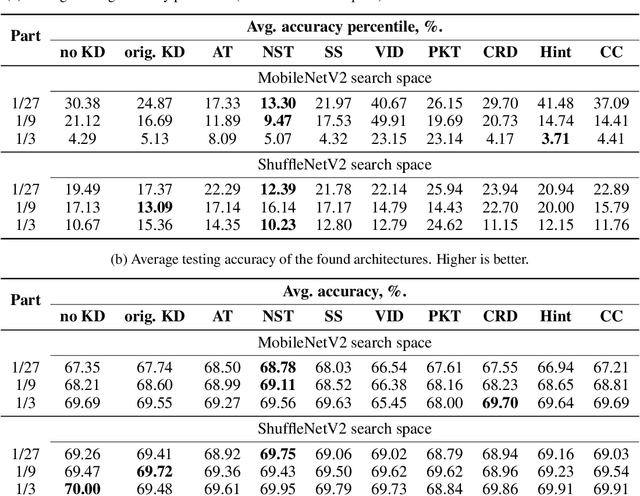
Neural architecture search (NAS) targets at finding the optimal architecture of a neural network for a problem or a family of problems. Evaluations of neural architectures are very time-consuming. One of the possible ways to mitigate this issue is to use low-fidelity evaluations, namely training on a part of a dataset, fewer epochs, with fewer channels, etc. In this paper, we propose to improve low-fidelity evaluations of neural architectures by using a knowledge distillation. Knowledge distillation adds to a loss function a term forcing a network to mimic some teacher network. We carry out experiments on CIFAR-100 and ImageNet and study various knowledge distillation methods. We show that training on the small part of a dataset with such a modified loss function leads to a better selection of neural architectures than training with a logistic loss. The proposed low-fidelity evaluations were incorporated into a multi-fidelity search algorithm that outperformed the search based on high-fidelity evaluations only (training on a full dataset).
NAS-Bench-NLP: Neural Architecture Search Benchmark for Natural Language Processing
Jun 12, 2020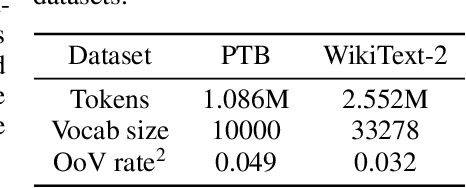

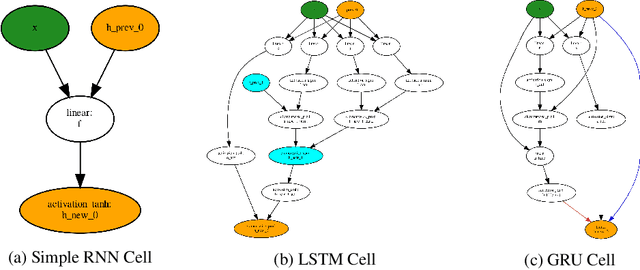
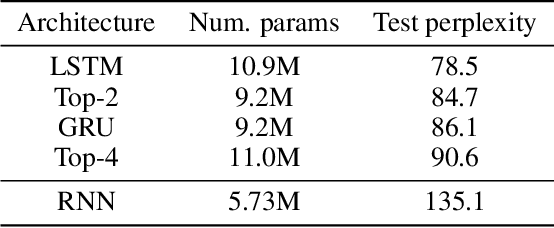
Neural Architecture Search (NAS) is a promising and rapidly evolving research area. Training a large number of neural networks requires an exceptional amount of computational power, which makes NAS unreachable for those researchers who have limited or no access to high-performance clusters and supercomputers. A few benchmarks with precomputed neural architectures performances have been recently introduced to overcome this problem and ensure more reproducible experiments. However, these benchmarks are only for the computer vision domain and, thus, are built from the image datasets and convolution-derived architectures. In this work, we step outside the computer vision domain by leveraging the language modeling task, which is the core of natural language processing (NLP). Our main contribution is as follows: we have provided search space of recurrent neural networks on the text datasets and trained 14k architectures within it; we have conducted both intrinsic and extrinsic evaluation of the trained models using datasets for semantic relatedness and language understanding evaluation; finally, we have tested several NAS algorithms to demonstrate how the precomputed results can be utilized. We believe that our results have high potential of usage for both NAS and NLP communities.
Failures detection at directional drilling using real-time analogues search
Jun 06, 2019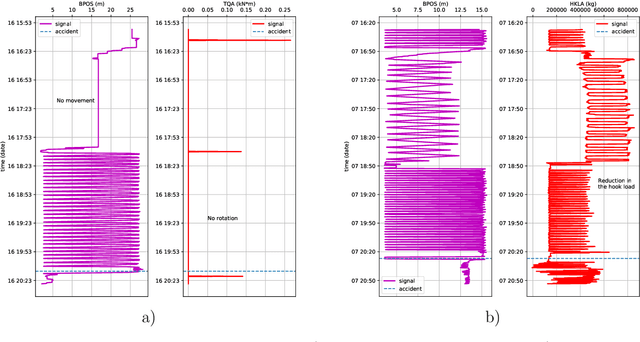
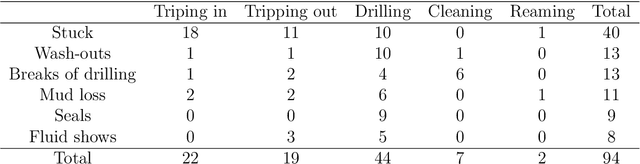

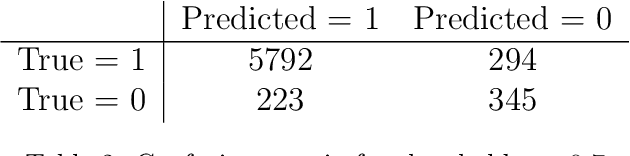
One of the main challenges in the construction of oil and gas wells is the need to detect and avoid abnormal situations, which can lead to accidents. Accidents have some indicators that help to find them during the drilling process. In this article, we present a data-driven model trained on historical data from drilling accidents that can detect different types of accidents using real-time signals. The results show that using the time-series comparison, based on aggregated statistics and gradient boosting classification, it is possible to detect an anomaly and identify its type by comparing current measurements while drilling with the stored ones from the database of accidents.
Real-time data-driven detection of the rock type alteration during a directional drilling
Mar 27, 2019
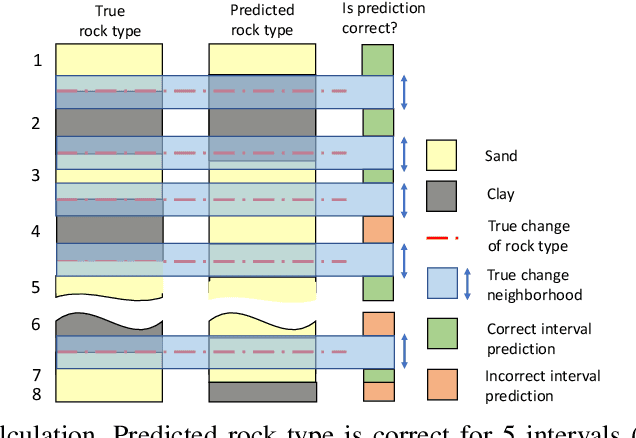
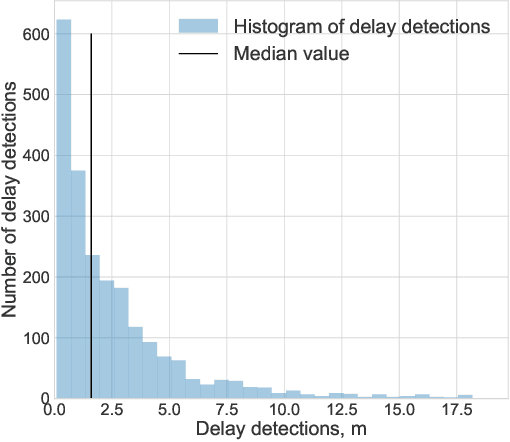
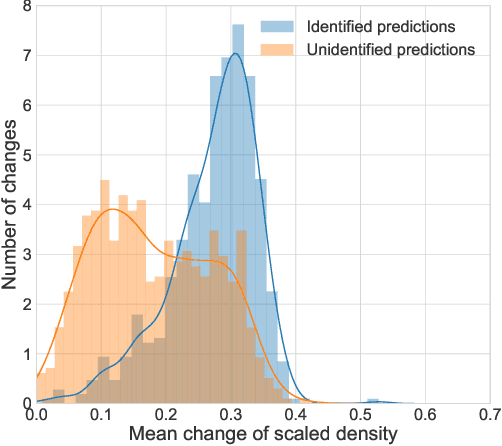
During the directional drilling, a bit may sometimes go to a nonproductive rock layer due to the gap about 20 m between the bit and high-fidelity rock type sensors. The only way to detect the lithotype changes in time is the usage of Measurements While Drilling (MWD) data. However, there are no mathematical modeling approaches that reconstruct the rock type based on MWD data with high accuracy. In this article, we present a data-driven procedure that utilizes MWD data for quick detection of changes in rock type. We propose the approach that combines traditional machine learning based on the solution of the rock type classification problem with change detection procedures rarely used before in Oil & Gas industry. The data come from a newly developed oilfield in the North of Western Siberia. The results suggest that we can detect a significant part of changes in rock type reducing the change detection delay from 20 to 2.6 m and the number of false positive alarms from 71 to 7 per well.
Laplace Inference for Multi-fidelity Gaussian Process Classification
Sep 13, 2018
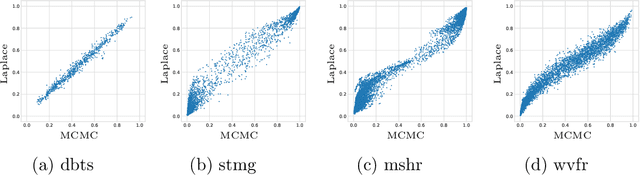


In this paper we address a classification problem where two sources of labels with different levels of fidelity are available. Our approach is to combine data from both sources by applying a co-kriging schema on latent functions, which allows the model to account item-dependent labeling discrepancy. We provide an extension for Laplace inference for Gaussian process classification, that takes into account multi-fidelity data. We evaluate the proposed method on real and synthetic datasets and show that it is more resistant to different levels of discrepancy between sources, than other approaches for data fusion. Our method can provide accuracy/cost trade-off for a number of practical tasks such as crowd-sourced data annotation and feasibility regions construction in engineering design.
Data-driven model for the identification of the rock type at a drilling bit
Sep 13, 2018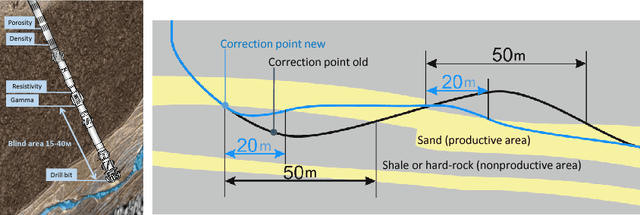
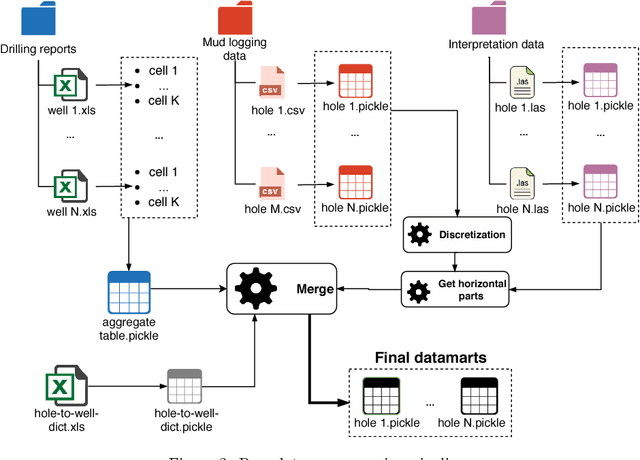
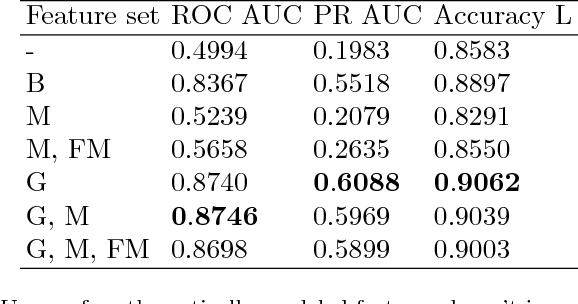
In order to bridge the gap of more than 15m between the drilling bit and high-fidelity rock type sensors during the directional drilling, we present a novel approach for identifying rock type at the drilling bit. The approach is based on application of machine learning techniques for Measurements While Drilling (MWD) data. We demonstrate capabilities of the developed approach for distinguishing between the rock types corresponding to (1) a target oil bearing interval of a reservoir and (2) a non-productive shale layer and compare it to more traditional physics-driven approaches. The dataset includes MWD data and lithology mapping along multiple wellbores obtained by processing of Logging While Drilling (LWD) measurements from a massive drilling effort on one of the major newly developed oilfield in the North of Western Siberia. We compare various machine-learning algorithms, examine extra features coming from physical modeling of drilling mechanics, and show that the classification error can be reduced from 13.5% to 9%.